エンドツーエンド学習とは?意味・仕組み・従来手法との違いをわかりやすく解説

AIの初心者
「エンドツーエンド学習」って、普通の機械学習と何が違うんですか?

AI専門家
たとえば手書き文字を読み取る場合、従来は画像を整え、文字の場所を探し、文字を判定する、と段階を分けていました。エンドツーエンド学習では、画像を入力し、読み取り結果を出力する流れを一つの大きなモデルでまとめて学習します。
AIの初心者
途中の処理を人が細かく作らなくてもよいなら、とても便利そうですね。
AI専門家
その通りです。ただし、モデルが途中の処理まで自分で学ぶためには、十分な量と質のデータが欠かせません。便利な反面、データ準備や学習コストにも注意が必要です。
End-to-End Learningとは。
エンドツーエンド学習とは、機械学習で入力から出力までの関係を一つのモデルにまとめて学習させる考え方です。従来のように前処理、特徴抽出、分類などを細かく分けて個別に設計するのではなく、画像なら画像、音声なら音声といった入力データから、認識結果や予測結果までを直接結び付けます。中間の処理はニューラルネットワークなどのモデルがデータから学習するため、全体として最適な処理を見つけられる可能性があります。一方で、大量の学習データ、計算資源、結果の解釈の難しさといった課題もあるため、目的に合わせた使い分けが重要です。
エンドツーエンド学習とは
エンドツーエンド学習は、英語では End-to-End Learning と呼ばれます。直訳すると「端から端までの学習」であり、機械学習では入力データから最終的な出力までを一つの大きなモデルで直接学習する方法を指します。
たとえば、手書き文字の画像を見て「これは何という文字か」を判定するシステムを考えます。従来は、画像をきれいにする、文字がある範囲を切り出す、形の特徴を取り出す、文字を分類する、といった複数の処理を人が設計していました。エンドツーエンド学習では、画像と正解ラベルの組み合わせを大量に与え、画像から文字列を出す流れをモデル全体で学習させます。
重要なのは、途中の処理が消えるわけではない点です。前処理や特徴抽出に相当する働きは、ニューラルネットワークの内部で学習されます。つまり、人が明示的に各段階を作る代わりに、モデルがデータから必要な表現を見つけていく、という考え方です。
従来の機械学習との違い

従来の機械学習では、問題をいくつかの小さな処理に分け、それぞれに適した手法を選びます。OCRなら、画像補正、文字領域の検出、特徴量の抽出、文字分類といった段階です。それぞれの処理を改善しやすく、どこで失敗しているかを調べやすいという利点があります。
一方、エンドツーエンド学習では、これらの段階をできるだけ一つのモデルに統合します。入力と正解出力の関係を直接学習するため、個別の段階ではなくシステム全体の性能を基準に調整できることが特徴です。ある段階だけを見ると最適でなくても、最終的な出力が良くなるように内部表現が調整されます。
| 観点 | 従来の段階的な手法 | エンドツーエンド学習 |
|---|---|---|
| 設計方法 | 処理を複数の段階に分けて設計する | 入力から出力までを一つのモデルで学習する |
| 調整の単位 | 前処理、特徴抽出、分類などを個別に調整する | 最終的な出力結果を見ながら全体を調整する |
| 強み | 原因分析や部分的な改善がしやすい | 全体最適化により高い性能を得られる可能性がある |
| 注意点 | 各段階の最適化が全体最適とは限らない | 大量のデータや計算資源が必要になりやすい |
OCRで見るエンドツーエンド学習の仕組み
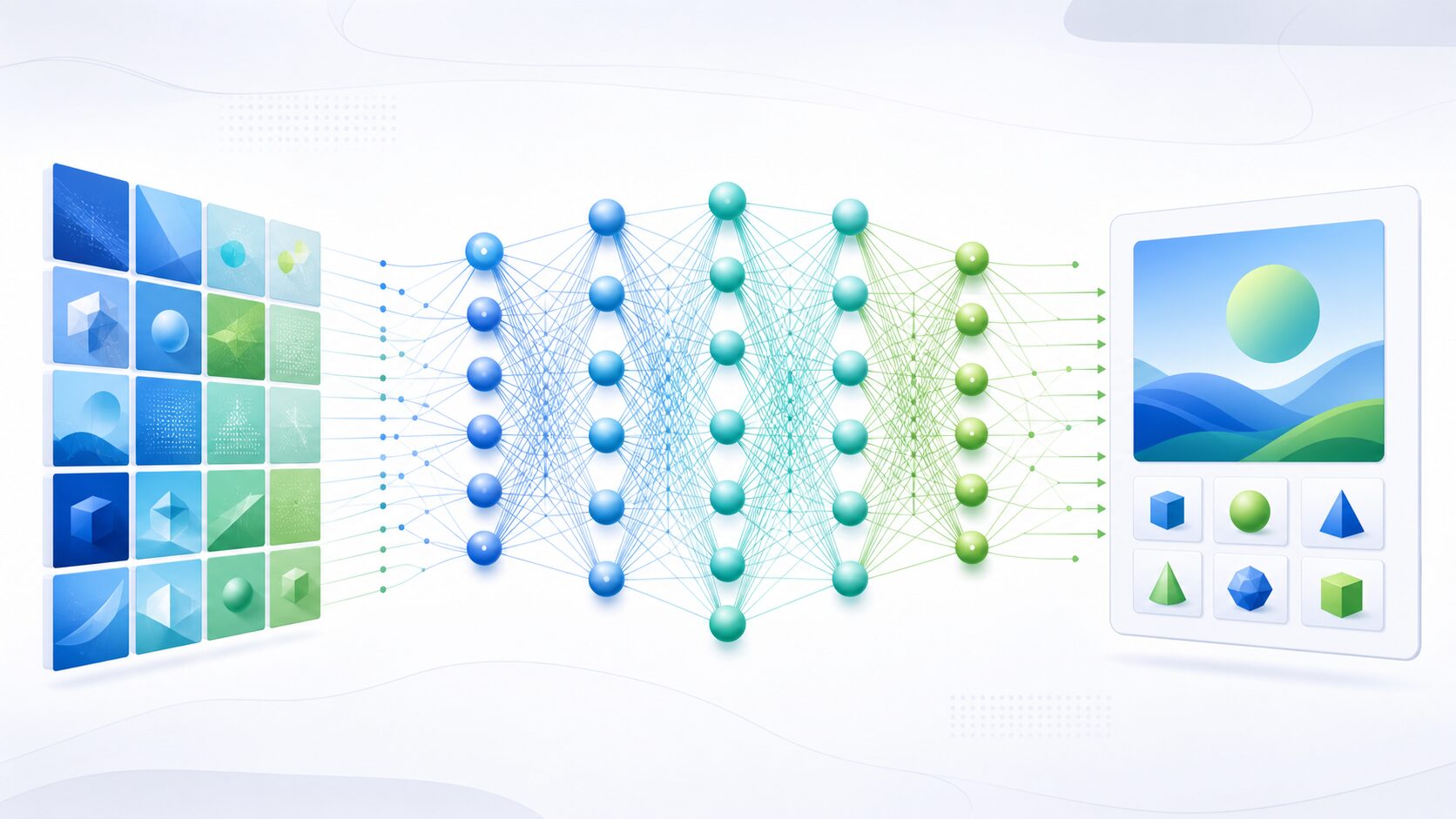
エンドツーエンド学習の例として分かりやすいのが、OCR、つまり光学文字認識です。OCRは、印刷物や手書きの文字を画像から読み取り、コンピュータで扱える文字列に変換する技術です。
従来のOCRでは、画像に含まれるノイズを取り除き、文字の位置を見つけ、文字の形を特徴量として取り出し、最後にどの文字かを判定する、という段階的な処理がよく使われていました。この方法は各段階の意味が分かりやすい反面、前の段階で失敗すると後ろの段階にも影響が伝わります。
エンドツーエンド型のOCRでは、たくさんの画像と正解の文字列を使って、画像から文字列を出すモデルを直接学習させます。ニューラルネットワークは、文字の線の形、周囲との位置関係、画像全体の文脈などを組み合わせて認識に必要な内部表現を作ります。そのため、十分なデータがある場合には、人が細かく特徴を設計するより柔軟に対応できることがあります。
この考え方はOCRだけでなく、音声認識、画像認識、機械翻訳、画像キャプション生成などにも応用されています。いずれも「入力」と「期待する出力」が明確で、中間処理をデータから学ばせたい場面で使われます。
エンドツーエンド学習のメリット
エンドツーエンド学習の大きなメリットは、全体最適化を狙えることです。段階的な手法では、各工程をそれぞれ良くしても、最終結果が必ず良くなるとは限りません。エンドツーエンド学習では、最終的な誤りが小さくなるようにモデル全体を更新するため、入力から出力までの流れを一つの目的に向けて調整できます。
また、人が特徴量や処理手順を細かく作り込む負担を減らせることも利点です。特に画像、音声、自然言語のように、どの特徴が重要かを人が完全に決めるのが難しいデータでは、モデルが有用な特徴を学習できる点が強みになります。
ただし、これは人間の設計が不要になるという意味ではありません。モデル構造の選択、学習データの設計、評価方法、運用時の監視などは依然として重要です。エンドツーエンド学習は、手作業の処理設計を減らす一方で、データと学習全体の設計がより重要になる方法だと考えると理解しやすいでしょう。
大量のデータが必要になる理由
エンドツーエンド学習では、中間の処理までモデルが学ぶため、学習すべき内容が多くなります。そのため、少ないデータだけでは入力と出力の関係を十分に理解できず、見たことのないデータに弱くなることがあります。
典型的な問題が過学習です。過学習とは、学習データに含まれる細かい特徴を覚え込みすぎて、新しいデータに対して正しく予測できなくなる状態です。たとえば、過去問だけを丸暗記した結果、少し表現が変わった問題に対応できない状態に近いものです。
エンドツーエンド学習では、モデルの規模が大きくなりやすいため、データ量が不足すると過学習のリスクが高まります。学習データと検証データを分けて評価する、データ拡張を使う、モデルの複雑さを調整するなど、汎化性能を確認する工夫が欠かせません。
データの質が結果を左右する
データは量だけでなく質も重要です。たとえば、ある種類の画像ばかりで学習したモデルは、それ以外の条件の画像を苦手にすることがあります。明るい場所の写真だけで学習したモデルが暗い場所の写真に弱い、特定の筆跡だけで学習したOCRが別の筆跡を読みづらい、といったケースです。
また、正解ラベルに誤りが多い場合、モデルは間違った関係を学習してしまいます。入力と出力を直接結び付けるエンドツーエンド学習では、ラベルの品質がそのまま学習結果に影響します。データの偏り、重複、誤ラベル、欠損、収集条件の違いを確認する作業は、モデルの精度を支える土台です。
| データの問題 | 起こりやすい影響 | 確認したいこと |
|---|---|---|
| 量が少ない | 過学習しやすく、未知の入力に弱くなる | 検証データで性能が保てているか |
| 偏りがある | 特定の条件だけに強いモデルになる | 利用場面に近いデータが含まれているか |
| ラベルに誤りがある | 誤った判断基準を学習する | 正解データの点検や修正が行われているか |
| ノイズが多い | 本質的でない特徴に引きずられる | 不要な情報を減らす前処理が必要か |
向いている場面と向いていない場面
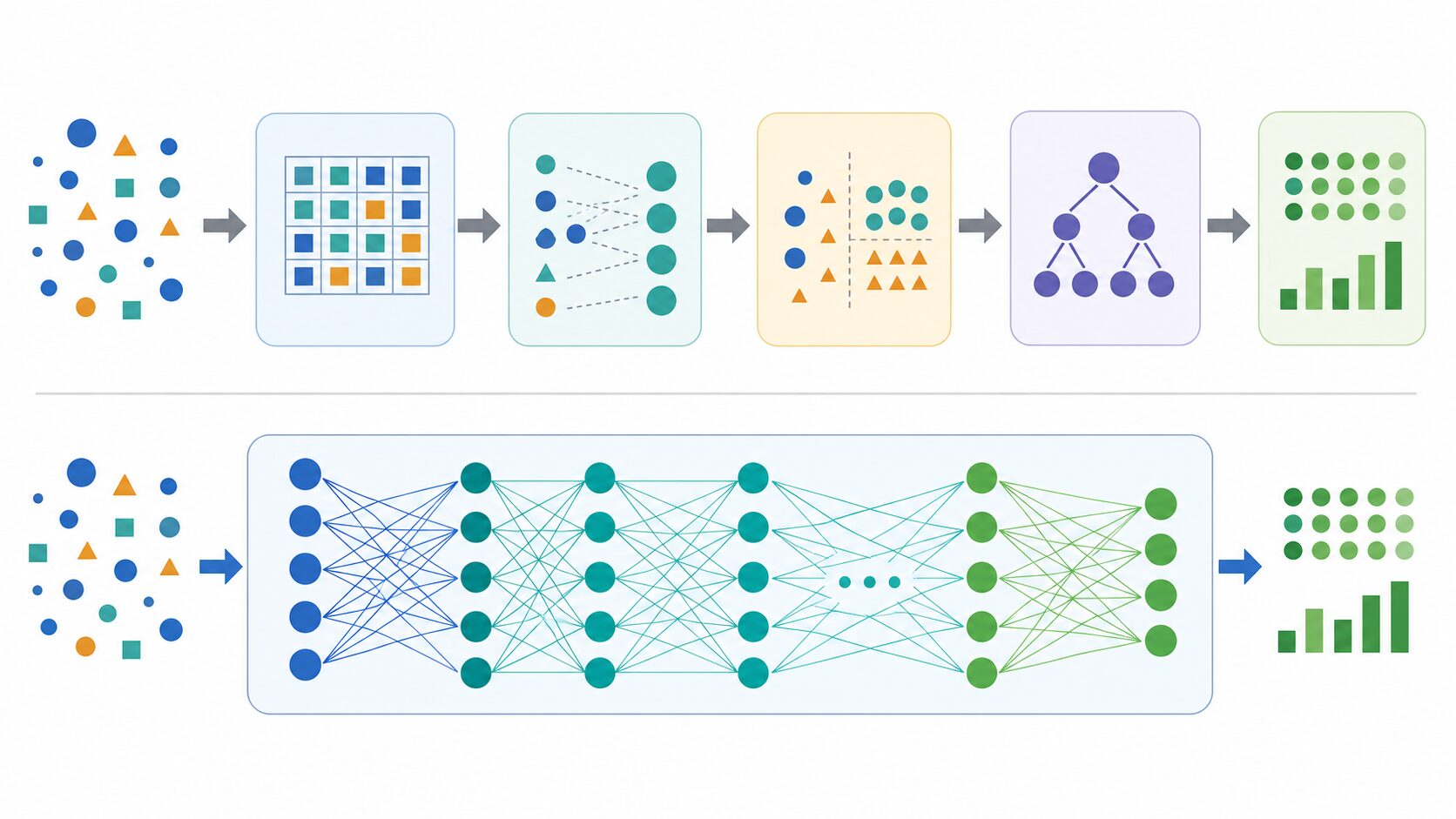
エンドツーエンド学習は強力ですが、すべての問題に最適とは限りません。向いているのは、入力と出力の対応が明確で、十分な学習データを用意でき、従来の手作業による特徴設計が難しい場面です。画像、音声、自然言語のように複雑なパターンを扱う問題では特に効果を発揮しやすい方法です。
反対に、データが少ない場合、なぜその結果になったかを詳しく説明する必要がある場合、処理の途中段階を人が明確に管理したい場合には、段階的な手法やルールベースの処理が適していることもあります。医療、金融、製造検査など、説明責任や安全性が重要な領域では、性能だけでなく解釈性や検証のしやすさも判断材料になります。
実務では、すべてをエンドツーエンドにするのではなく、従来手法と組み合わせることもあります。たとえば、最低限の前処理でノイズを減らしてからニューラルネットワークに入力する、検出部分だけを別モデルにする、といった構成です。目的、データ、計算資源、運用上の制約を見ながら、全体として扱いやすい形を選ぶことが大切です。
| 判断項目 | エンドツーエンド学習が向く場合 | 別手法も検討したい場合 |
|---|---|---|
| データ量 | 多様で十分な量のデータがある | データが少ない、収集が難しい |
| 問題の複雑さ | 人が特徴を設計しにくい | 単純なルールや既存手法で十分に解ける |
| 説明性 | 最終性能を重視し、別途評価で信頼性を確認できる | 判断理由を細かく説明する必要がある |
| 計算資源 | 学習時間やGPUなどの資源を確保できる | 短時間、低コストで学習したい |
まとめ
エンドツーエンド学習は、入力から出力までを一つのモデルで直接学習する機械学習の方法です。従来のように処理を細かく分けて設計するのではなく、モデルがデータから中間表現を学ぶことで、全体として高い性能を得られる可能性があります。
一方で、大量で質の高いデータ、十分な計算資源、過学習への対策、解釈性の確保が必要です。エンドツーエンド学習は「何でも自動で解決する方法」ではなく、データと目的に合えば強力に働く選択肢です。従来手法との違いを理解し、必要に応じて組み合わせながら使うことが、実務や学習での重要なポイントになります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月28日 | 従来手法との比較、OCR例、データ面の注意点を追記 |