学習
学習 誤差関数:機械学習の要
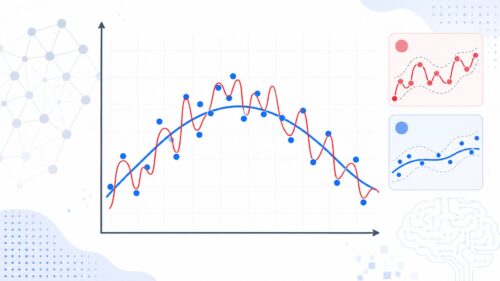
機械学習は、与えられた情報から規則性を、まだ知らない情報に対しても推測を行う技術です。この学習の過程で、作り上げた模型の良し悪しを評価する重要な指標となるのが誤差関数です。誤差関数は、模型が推測した値と、実際に正しい値との違いを数値で表します。この違いが小さいほど、模型の推測の正確さが高いことを意味します。
機械学習の最終目標は、この誤差関数の値を可能な限り小さくすることです。誤差関数の値を小さくすることで、模型は情報の背にある本当の繋がりをより正しく捉えることができるようになります。例えば、家の値段を予測する模型を考えてみましょう。この模型に家の広さや築年数などの情報を入力すると、家の価格が予測されます。もし、この模型が実際の価格と大きく異なる価格を予測した場合、誤差関数の値は大きくなります。反対に、実際の価格に近い価格を予測した場合、誤差関数の値は小さくなります。
誤差関数の種類は様々で、目的に合わせて適切なものを選ぶ必要があります。例えば、二乗誤差は、予測値と正解値の差の二乗を計算し、その合計を誤差とします。これは、外れ値の影響を受けやすいという特徴があります。一方、絶対値誤差は、予測値と正解値の差の絶対値を計算し、その合計を誤差とします。これは、二乗誤差に比べて外れ値の影響を受けにくいという特徴があります。
このように、誤差関数は模型の学習を正しい方向へ導く羅針盤のような役割を果たします。誤差関数を適切に設定することで、より精度の高い予測模型を作り上げることが可能になります。