TabTransformerとは?表形式データをTransformerで扱う仕組みと使いどころ

AIの初心者
TabTransformerという言葉を見ました。画像や文章ではなく、表のデータにもTransformerを使うのですか?

AI専門家
はい。TabTransformerは、顧客属性や購買履歴のような表形式データを扱うために、カテゴリ特徴量を埋め込みに変換し、Transformerの自己注意で列同士の関係を学習する考え方です。
AIの初心者
表データならLightGBMやCatBoostが強いと聞きます。TabTransformerはそれらの代わりになるのでしょうか?
AI専門家
常に置き換えるものではありません。この記事では、TabTransformerの定義、仕組み、カテゴリ特徴量の扱い、木系モデルとの違い、実務で試すときの判断基準を順番に整理します。
TabTransformerとは。
TabTransformerとは、表形式データのカテゴリ特徴量を埋め込みベクトルとして表現し、Transformerの自己注意機構によって列同士の関係を学習するニューラルネットワーク型のモデルです。顧客属性、商品カテゴリ、地域、契約プラン、利用端末など、値の種類が意味を持つ列を多く含むデータで、特徴量間の組み合わせを柔軟に捉えることを目的に使われます。
表形式データは、企業や研究の現場で最もよく使われるデータ形式の一つです。たとえば、行が顧客、列が年齢、契約プラン、地域、購入回数、解約有無になっているデータを考えると分かりやすいでしょう。このようなデータから「この顧客は解約しそうか」「この申込は不正の可能性が高いか」「この商品は購入されそうか」を予測するのが、表形式データの機械学習です。
従来、表形式データでは決定木、ランダムフォレスト、XGBoost、LightGBM、CatBoostのような木系モデルが強力な選択肢として使われてきました。一方で、深層学習の発展により、文章や画像で成果を出したTransformerの考え方を、表データにも応用できないかという流れが生まれました。TabTransformerはその代表的なアプローチの一つです。
初心者が最初に押さえるべき点は、TabTransformerが単に「表データにTransformerを貼り付けたモデル」ではないことです。表データには、文章のような明確な語順がありません。列ごとの意味、カテゴリ値の意味、数値特徴量との関係、欠損や外れ値の扱いが重要になります。そのため、TabTransformerは特にカテゴリ特徴量をどう表現し、列同士の関係をどう学習するかに焦点を当てています。
TabTransformerを理解する前に押さえたい表形式データの特徴
表形式データとは、行と列で整理されたデータです。スプレッドシート、CSV、データベースのテーブルを思い浮かべるとよいでしょう。1行は一つの対象を表し、列はその対象を説明する情報を表します。顧客データなら、1行が1人の顧客、列が年齢、性別、居住地域、契約プラン、利用回数、過去の問い合わせ回数などになります。
表データの難しさは、列の種類が混ざっている点にあります。年齢や金額のように大小関係がある数値特徴量もあれば、地域、職業、商品カテゴリ、端末種別のように、値がラベルとして意味を持つカテゴリ特徴量もあります。さらに、欠損値、まれなカテゴリ、年月日、ID、テキストの短い説明などが混ざることもあります。これらを同じ方法で扱うと、情報の意味を壊してしまう場合があります。
たとえば「地域」という列に、東京、大阪、福岡という値が入っているとします。これを単純に東京=1、大阪=2、福岡=3のように数値へ置き換えると、モデルは大阪が東京と福岡の中間にあるような誤った大小関係を学ぶ可能性があります。カテゴリ値には順序がない場合が多いため、単純な番号付けでは不自然です。この問題を避けるために、One-hotエンコーディングやターゲットエンコーディング、カテゴリ埋め込みなどが使われます。
TabTransformerは、このカテゴリ特徴量の扱いを重視します。カテゴリ値を意味のあるベクトルへ変換し、それぞれの列を一種のトークンとして扱います。文章のTransformerが単語同士の関係を見るように、TabTransformerは表の列同士の関係を見ようとします。ただし、表データの列は文章の単語とは異なり、順番よりも「どの列がどの列と関係するか」が重要です。
TabTransformerの基本的な考え方
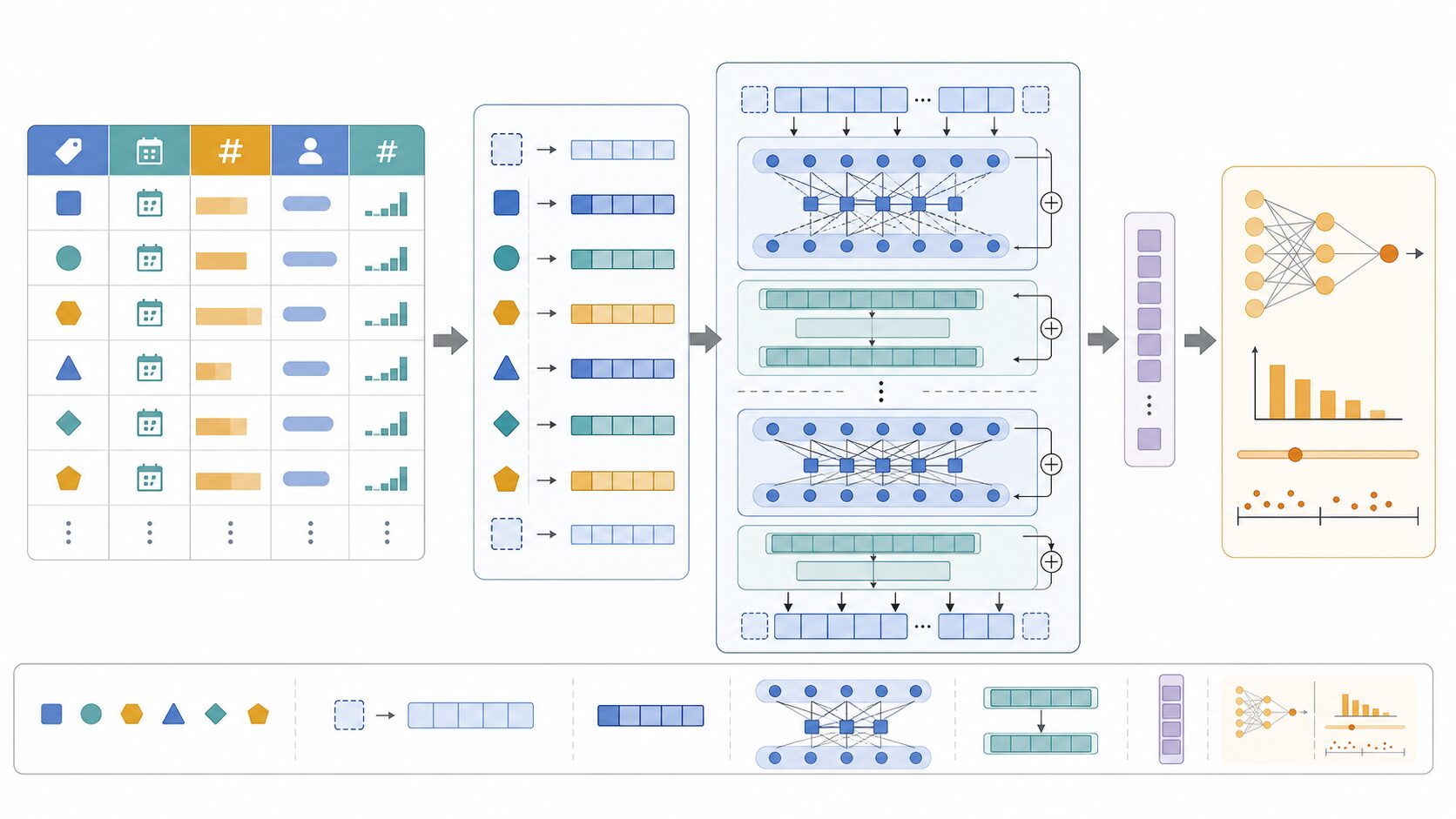
TabTransformerの基本は、表形式データのカテゴリ特徴量を埋め込みベクトルに変換し、その埋め込みをTransformer層に通すことです。埋め込みとは、カテゴリ値を複数の数値からなるベクトルで表す方法です。たとえば、商品カテゴリ「家電」「食品」「衣料」をそれぞれ数十次元のベクトルとして表現し、モデルが学習を通じてそれらの関係を調整します。
カテゴリ特徴量を埋め込みにすると、単なる番号やOne-hotよりも柔軟な表現ができます。似た購買傾向を持つカテゴリが近いベクトルになる可能性があり、まれなカテゴリやカテゴリ同士の組み合わせを扱いやすくなることがあります。TabTransformerでは、この埋め込み表現をTransformerの自己注意に入力し、列同士の相互作用を学習します。
自己注意とは、ある特徴量を見るときに、他の特徴量の情報をどれくらい参照するかを学ぶ仕組みです。顧客の解約予測であれば、「契約プラン」だけを見るのではなく、「契約プラン」と「利用頻度」と「問い合わせ回数」の組み合わせが重要かもしれません。自己注意は、このような特徴量間の関係をデータから学習するための部品です。
TabTransformerの出力は、変換されたカテゴリ特徴量の表現です。これに数値特徴量を組み合わせ、最終的に分類や回帰の予測を行います。分類なら解約するかどうか、不正かどうか、購入するかどうかを予測します。回帰なら売上額、需要量、滞在時間、スコアなどの連続値を予測します。
重要なのは、TabTransformerがカテゴリ特徴量を深層学習向けに表現し直すためのモデルとして理解できる点です。すべての表データ問題を一気に解決する魔法の方法ではありませんが、カテゴリ列が多く、列同士の関係が複雑で、十分なデータがある場合に検討する価値があります。
カテゴリ特徴量を埋め込みで扱う理由
カテゴリ特徴量とは、値が分類やラベルを表す特徴量です。都道府県、商品カテゴリ、職業、契約プラン、デバイス種別、店舗ID、曜日、キャンペーン種別などが代表例です。カテゴリ特徴量は表データの予測で重要な情報源になりますが、そのままではニューラルネットワークに入力しにくいという問題があります。
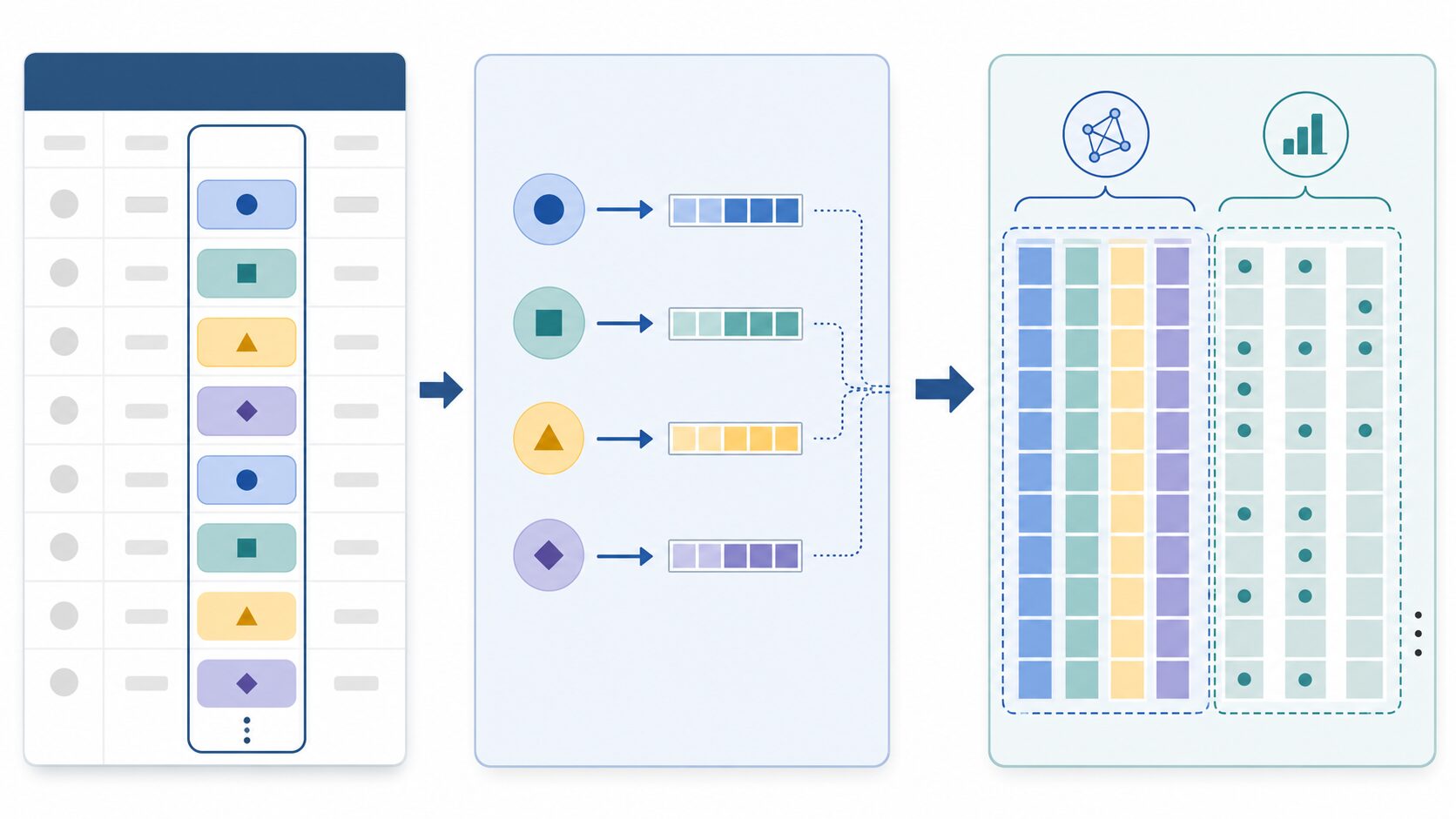
One-hotエンコーディングでは、カテゴリの種類ごとに列を作ります。値が「東京」なら東京の列を1にし、他を0にします。この方法は分かりやすい一方で、カテゴリ数が多いと列数が増えすぎます。商品IDや店舗IDのように数千、数万の種類がある場合、One-hotだけでは扱いにくくなります。また、カテゴリ同士の近さや似ている関係を直接表現しにくいという弱点もあります。
埋め込みは、カテゴリを固定長のベクトルへ変換します。たとえば、ある店舗IDを32次元のベクトルで表すとします。最初はランダムに近い値でも、学習が進むと、予測に役立つ方向へベクトルが調整されます。似た購買傾向の店舗、似たリスクを持つ契約プラン、似た行動を示すデバイス種別が、モデル内部で近い表現になることがあります。
TabTransformerでは、このカテゴリ埋め込みをさらにTransformer層に通します。単独のカテゴリ値だけではなく、複数のカテゴリ特徴量の関係を見ます。たとえば「若年層」「モバイルアプリ利用」「短期契約」「問い合わせ回数が多い」という組み合わせが、解約率の上昇と関係するかもしれません。カテゴリ埋め込みと自己注意を組み合わせることで、このような相互作用を表現しやすくなります。
ただし、埋め込みが常に便利というわけではありません。データ量が少ない場合、カテゴリごとの埋め込みを十分に学習できないことがあります。非常にまれなカテゴリが多い場合、学習データにほとんど出てこない値の表現は不安定になります。実務では、低頻度カテゴリをまとめる、未知カテゴリを扱う、学習時と推論時でカテゴリ辞書を固定するなどの設計が必要です。
自己注意で列同士の関係を見る仕組み
Transformerの中心的な部品は自己注意です。文章では、ある単語を理解するときに文中の他の単語を参照します。TabTransformerでは、ある列の情報を理解するときに、他の列の情報を参照します。表データには単語のような順序はありませんが、列同士の関係は存在します。
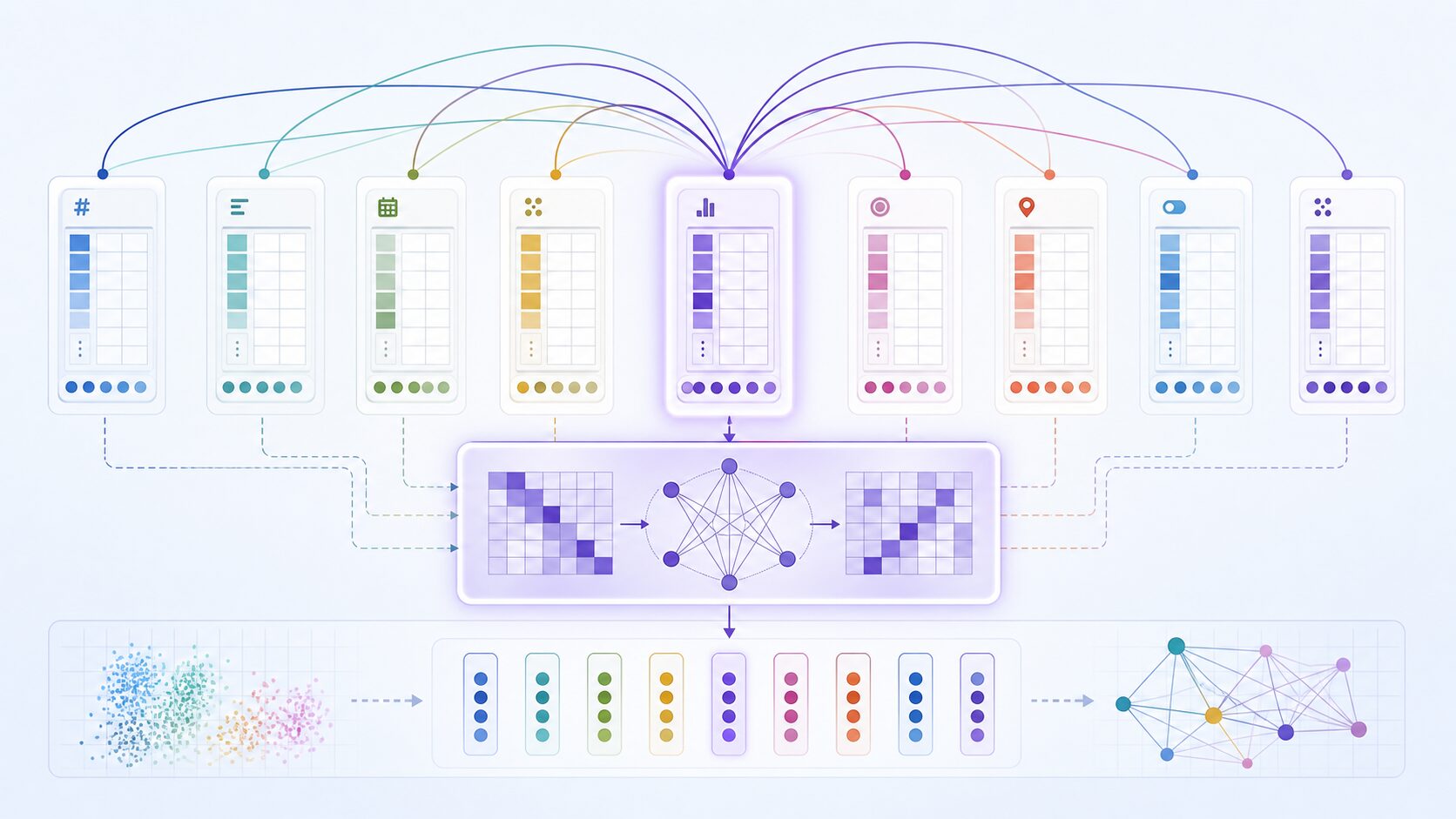
たとえば、クレジット審査のデータで「年収」「職業」「雇用形態」「借入額」「過去の延滞履歴」という列があるとします。借入額だけを見てもリスクは判断しにくく、年収や雇用形態との関係を見る必要があります。自己注意は、ある特徴量を表現するときに、他の特徴量をどの程度重視するかを学習します。これにより、単独の列では見えにくい組み合わせを捉えやすくなります。
従来の多層パーセプトロンでも、複数特徴量の非線形な関係を学ぶことはできます。しかし、TabTransformerはカテゴリ特徴量を列ごとのトークンのように扱い、自己注意で相互作用を明示的に計算する点に特徴があります。これは、カテゴリ列が多く、それぞれの列が異なる意味を持つ表データで有効に働く可能性があります。
一方で、自己注意には計算コストがあります。列数が増えるほど、列同士の組み合わせを見る計算が増えます。文章モデルほど長い系列を扱うわけではないため、表データでは現実的な範囲に収まることも多いですが、列数が非常に多いデータでは注意が必要です。また、自己注意があるからといって、必ず人間にとって分かりやすい理由が得られるとは限りません。注意重みは参考情報になりますが、説明可能性そのものとは区別して考える必要があります。
TabTransformerの一般的な処理の流れ
TabTransformerの処理は、大きく分けると、入力整理、カテゴリ埋め込み、Transformer層、数値特徴量との結合、予測層の順に進みます。ここでは初心者向けに、実装の細部よりもデータがどう変換されるかに注目して説明します。
| 段階 | 何をするか | 初心者が見るべき点 |
|---|---|---|
| 入力整理 | カテゴリ列、数値列、目的変数を分け、欠損値や未知カテゴリの扱いを決める | 学習時と推論時で前処理がずれないようにする |
| カテゴリ埋め込み | 各カテゴリ値をベクトルに変換する | カテゴリ数、低頻度カテゴリ、埋め込み次元を確認する |
| Transformer層 | 自己注意でカテゴリ列同士の関係を学習する | 列間の相互作用を学ぶための中心部分と考える |
| 数値特徴量との結合 | 変換されたカテゴリ表現と数値特徴量を合わせる | 数値のスケーリングや欠損処理を忘れない |
| 予測層 | 分類や回帰の出力を計算する | 評価指標と損失関数が目的に合っているか確認する |
この流れを見ると、TabTransformerは前処理が不要なモデルではないことが分かります。カテゴリを埋め込みにするにはカテゴリ辞書が必要です。未知カテゴリをどう扱うかも決める必要があります。数値特徴量はそのまま入れられる場合もありますが、ニューラルネットワークではスケーリングが有効なことが多く、欠損値の扱いも重要です。
また、TabTransformerはカテゴリ特徴量の処理に強みを持つため、カテゴリ列が少なく数値列中心のデータでは、効果が見えにくい場合があります。逆に、カテゴリ列が多く、カテゴリ同士の組み合わせが予測に効く問題では、試す価値が高まります。モデル選定では、データの形と課題の性質を先に見ることが大切です。
従来の木系モデルとの違い
表形式データの世界では、LightGBM、XGBoost、CatBoostのような勾配ブースティング決定木が非常に強いベースラインとして知られています。少ない前処理で高い精度を出しやすく、学習も比較的速く、特徴量重要度などの分析もしやすいからです。そのため、TabTransformerを学ぶときは、木系モデルとの違いを理解しておくと判断しやすくなります。
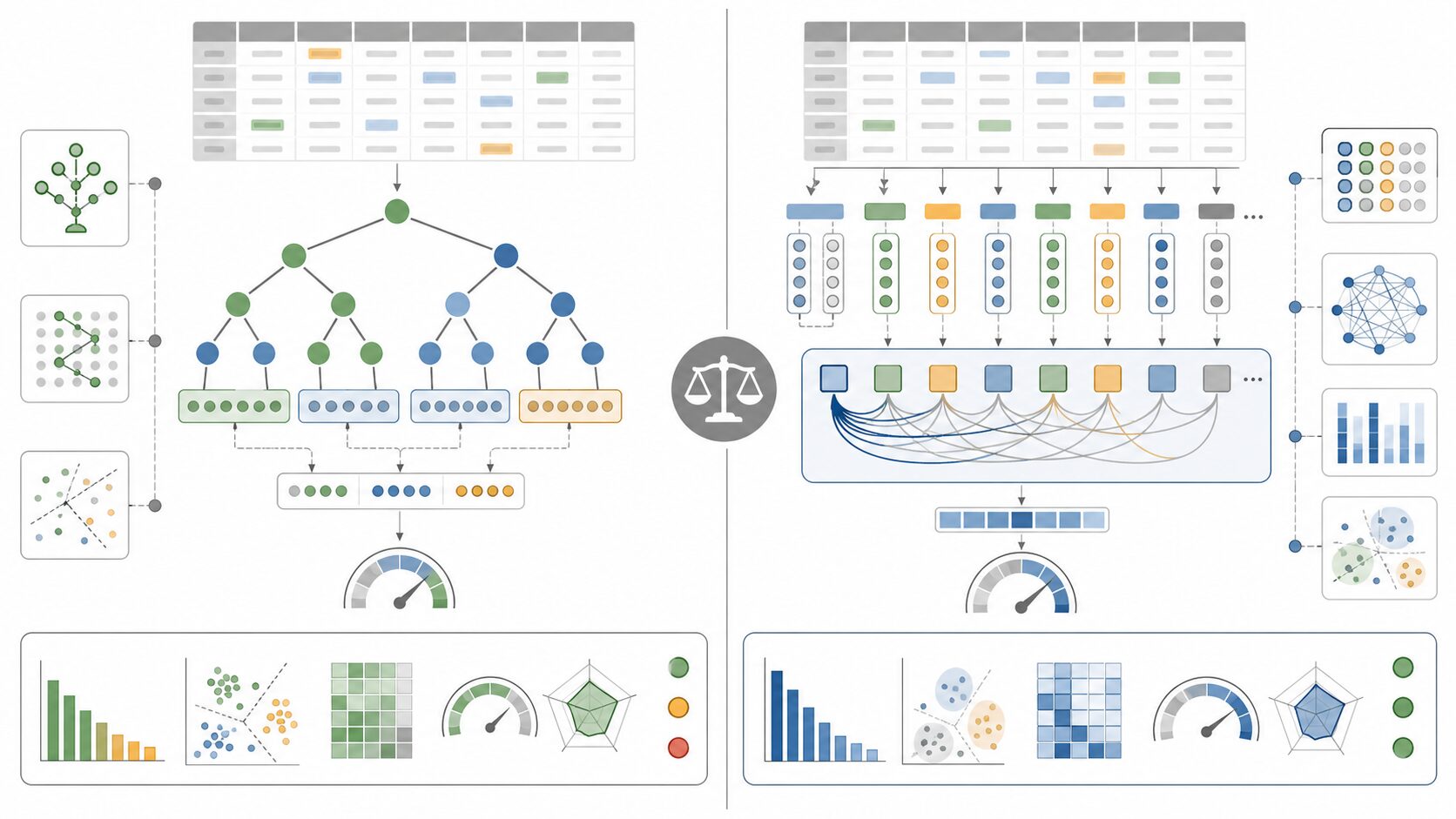
木系モデルは、特徴量の値に基づいてデータを分割していきます。「年齢が30未満か」「利用回数が一定以上か」「カテゴリが特定の値か」といった分岐を組み合わせ、予測を行います。非線形な関係や特徴量同士の相互作用を扱いやすく、表データでは非常に実用的です。カテゴリ特徴量については、ライブラリによって扱い方が異なり、CatBoostのようにカテゴリ処理に強いモデルもあります。
TabTransformerは、カテゴリ値を埋め込みにし、列同士の関係を自己注意で学習します。分岐の集合として予測するというより、各列の表現を更新しながら、ニューラルネットワークとして予測します。カテゴリ同士の意味的な近さや複雑な組み合わせを表現できる可能性がある一方で、学習にはより多くのデータ、チューニング、計算資源が必要になることがあります。
| 比較軸 | 木系モデル | TabTransformer |
|---|---|---|
| 得意なデータ | 幅広い表形式データ。中小規模でも強いことが多い | カテゴリ列が多く、列間の複雑な関係が重要なデータ |
| 前処理 | 比較的少なく始められる場合が多い | カテゴリ辞書、埋め込み、スケーリングなどの設計が必要 |
| 学習コスト | 一般に軽めでベースラインを作りやすい | ニューラルネットワークとしての学習管理が必要 |
| 説明しやすさ | 特徴量重要度やSHAPなどと組み合わせやすい | 注意重みだけでは説明にならないため追加分析が必要 |
| 拡張性 | 表データ単体で扱いやすい | 埋め込みや他の深層学習部品と組み合わせやすい |
実務では、TabTransformerを最初の唯一の選択肢にするより、まず木系モデルで強いベースラインを作り、その後でTabTransformerを比較する流れが現実的です。ベースラインより精度が上がるか、未知カテゴリや高カーディナリティの列で安定するか、運用コストに見合うかを確認します。精度が少し上がっても、学習時間、推論遅延、説明責任、保守性が大きく悪化するなら採用しない判断もあります。
TabTransformerが向いている場面
TabTransformerが向いているのは、カテゴリ特徴量が多く、それらの組み合わせが予測に効きそうな場面です。ECサイトの購買予測では、ユーザー属性、商品カテゴリ、流入チャネル、キャンペーン、デバイス、時間帯など、多くのカテゴリ情報が関係します。金融のリスク判定では、職業、地域、契約種別、過去の取引パターンなどが組み合わさります。医療やヘルスケアでも、診療科、薬剤カテゴリ、検査区分、既往歴のカテゴリ情報が複雑に関係することがあります。
また、カテゴリ値の種類が多い高カーディナリティの特徴量を含む場合も検討対象になります。店舗ID、商品ID、広告ID、ユーザーセグメント、地域コードなどは、One-hotでは次元が大きくなりがちです。埋め込みを使えば、カテゴリを密なベクトルで扱えるため、ニューラルネットワークの中で学習しやすくなることがあります。
さらに、他の深層学習モデルと組み合わせたい場合にも相性があります。たとえば、ユーザーの表形式属性と、レビュー文、商品画像、時系列ログを組み合わせるマルチモーダルな予測では、表データ側の表現をニューラルネットワークで作れることが利点になります。木系モデルでも特徴量を工夫すれば対応できますが、深層学習の表現と結合しやすい点はTabTransformerの魅力です。
ただし、データ件数が少ない、カテゴリ列が少ない、数値特徴量だけでほとんど説明できる、モデルの説明責任が非常に重い、学習や推論の環境が限られている場合は、TabTransformerが最適とは限りません。向いている場面を選ぶこと自体が、TabTransformerを使いこなす第一歩です。
実務で試すときの進め方
TabTransformerを実務で試すときは、いきなり本番投入を目指すのではなく、比較可能な実験として進めるのが安全です。まず、目的変数、評価指標、検証方法を決めます。解約予測ならAUC、F1、再現率、精度、コストをどう評価するかを決めます。需要予測ならMAEやRMSEだけでなく、業務上どの程度の誤差が許容されるかを確認します。
次に、データ分割を慎重に行います。時系列性があるデータでは、未来の情報が過去の学習に混ざらないようにする必要があります。顧客単位や店舗単位でデータが重複する場合は、同じ顧客が学習と検証の両方に入ることで過大評価になる可能性があります。TabTransformerに限らず、表データの評価ではデータリークが大きな問題になります。
そのうえで、木系モデルや単純なニューラルネットワークをベースラインとして作ります。ベースラインがないと、TabTransformerが本当に良いのか判断できません。LightGBMやCatBoostで十分な精度が出るなら、TabTransformerを使う理由は、精度向上、カテゴリ表現の安定性、他モデルとの統合、将来拡張性などに絞られます。
TabTransformerの実験では、カテゴリ列の選び方、埋め込み次元、Transformer層の数、注意ヘッド数、ドロップアウト、学習率、バッチサイズなどを調整します。初心者は最初から大きなモデルにしすぎないことが重要です。大きなモデルは表現力が高い反面、過学習しやすく、学習も不安定になりやすいからです。まず小さめの構成で、学習曲線と検証性能を見ながら調整するのが現実的です。
実装時に注意したい前処理と検証
TabTransformerで最も見落とされやすいのは、モデル構造よりも前処理と検証です。カテゴリ特徴量を埋め込みにするには、カテゴリ値を整数IDへ変換する辞書が必要です。この辞書は学習データで作り、検証データや本番データでは同じ辞書を使います。本番で新しいカテゴリが出てきたときのために、未知カテゴリ用のIDを用意しておく必要があります。
欠損値の扱いも重要です。カテゴリ列の欠損は「不明」というカテゴリとして扱う方法があります。数値列の欠損は、中央値で補完する、欠損フラグを追加する、モデルに欠損を表す値として渡すなどの方法があります。欠損そのものが意味を持つ業務もあります。たとえば、ある項目が未入力であることがリスクや購買意欲と関係する場合、単純に平均で埋めるだけでは情報を失うことがあります。
数値特徴量はスケーリングが必要になることがあります。木系モデルではスケールの違いに比較的強いですが、ニューラルネットワークでは入力のスケールが学習の安定性に影響します。金額、回数、年齢、日数などの値が大きく異なる場合、標準化や正規化を検討します。ただし、本番推論でも同じ変換を再現できるように、学習データで決めた平均や標準偏差を保存する必要があります。
検証では、ランダム分割だけに頼らないことが大切です。時間の流れがある予測では、過去で学習し未来で検証するほうが現実に近くなります。店舗やユーザーのグループ単位で汎化を見る必要があるなら、グループをまたいだ分割を使います。TabTransformerの性能が良く見えても、分割方法が甘ければ本番で落ちる可能性があります。
説明可能性と運用上の考え方
表データの予測モデルは、業務判断に使われることが多いため、説明可能性が重要になります。金融、医療、人事、公共サービスのような領域では、なぜその予測になったのかを説明する必要が高くなります。TabTransformerはニューラルネットワーク型のモデルなので、木系モデルより解釈が難しくなる場合があります。
自己注意の重みを見れば説明できると思われがちですが、注意重みは「モデル内部でどの特徴を参照したか」の一部を示すに過ぎません。それがそのまま因果関係や業務上の理由を意味するわけではありません。説明を行うには、特徴量重要度、SHAPのような手法、部分依存、反実仮想の分析、エラー分析などを組み合わせる必要があります。
運用では、推論速度、モデルサイズ、再学習の頻度、カテゴリ辞書の更新、データ分布の変化を管理します。カテゴリ特徴量は時間とともに増えます。新しい商品、新しいキャンペーン、新しい店舗、新しい端末が登場すると、未知カテゴリが増える可能性があります。未知カテゴリが多くなると、モデルの予測品質が落ちることがあります。そのため、カテゴリ分布の監視と再学習の仕組みが必要です。
また、TabTransformerは深層学習モデルであるため、乱数シード、学習環境、ライブラリバージョン、GPUの有無などによって再現性が揺れる場合があります。実務で使うなら、実験管理、モデル保存、前処理パイプラインの保存、評価レポート、ロールバック手順まで含めて設計する必要があります。
関連用語との違い
TabTransformerを理解するには、似た用語との違いも整理しておくと役立ちます。特に、Transformer、BERT、カテゴリ埋め込み、FT-Transformer、TabNet、CatBoostなどは混同されやすい用語です。
| 用語 | 概要 | TabTransformerとの関係 |
|---|---|---|
| Transformer | 自己注意を中心にしたニューラルネットワーク構造 | TabTransformerはTransformerの考え方を表形式データに応用する |
| BERT | 文章理解で使われるTransformer系モデル | 主に自然言語向けで、表データ用のTabTransformerとは入力の性質が異なる |
| カテゴリ埋め込み | カテゴリ値をベクトルで表す方法 | TabTransformerの重要な構成要素 |
| TabNet | 表データ向けの深層学習モデルの一つ | 同じ表データ向けだが、特徴選択や注意の使い方が異なる |
| CatBoost | カテゴリ特徴量の扱いに強い勾配ブースティング決定木 | 実務で比較対象になりやすい強力な木系モデル |
初心者は、TabTransformerを「BERTの表データ版」と単純に覚えるより、「表データのカテゴリ列を埋め込み、列同士の関係をTransformerで更新するモデル」と覚えるほうが正確です。文章には単語の並びがありますが、表データには列の意味があります。この違いを意識すると、なぜ表データ向けに工夫が必要なのかが見えてきます。
学習するときのおすすめの順番
TabTransformerを学ぶ前に、まず表形式データの機械学習の基本を押さえると理解しやすくなります。目的変数、特徴量、学習データ、検証データ、テストデータ、過学習、評価指標、データリークといった基礎は、どのモデルを使う場合でも重要です。ここが曖昧なままTransformer系モデルに進むと、モデル構造ばかりに目が向き、実験の信頼性を判断できなくなります。
次に、カテゴリ特徴量の前処理を学びます。ラベルエンコーディング、One-hotエンコーディング、ターゲットエンコーディング、頻度エンコーディング、カテゴリ埋め込みの違いを整理します。それぞれに利点と弱点があり、データ量やカテゴリ数、検証方法によって適切な方法が変わります。
その後で、決定木系モデルとニューラルネットワークの違いを学ぶとよいでしょう。木系モデルは表データで強いベースラインになりやすく、実務でもよく使われます。ニューラルネットワークは表現力が高い一方で、スケーリング、学習率、正則化、バッチサイズなどの管理が必要です。この違いを知っておくと、TabTransformerを採用する理由を説明しやすくなります。
最後に、Transformerの自己注意を学びます。クエリ、キー、バリュー、注意重み、マルチヘッド注意といった用語は難しく見えますが、最初は「ある要素を表現するときに、他の要素をどれくらい参照するかを学ぶ仕組み」と理解すれば十分です。TabTransformerでは、その要素が単語ではなく表データの列である点が重要です。
よくある誤解
TabTransformerについてよくある誤解の一つは、「Transformerなので必ず従来手法より高精度になる」というものです。実際には、表データでは木系モデルが非常に強く、TabTransformerが常に勝つわけではありません。データ量が少ない、カテゴリ列が少ない、列間の関係が単純、チューニングが不十分といった条件では、木系モデルのほうが良い結果になることもあります。
二つ目の誤解は、「前処理をしなくてもよい」というものです。TabTransformerはカテゴリ特徴量を埋め込みで扱えますが、カテゴリ辞書、未知カテゴリ、欠損値、数値スケーリング、検証分割などは依然として重要です。深層学習モデルは前処理のミスを自動で解決してくれるわけではありません。
三つ目の誤解は、「注意重みを見れば完全に説明できる」というものです。自己注意はモデルの内部計算の一部を示しますが、予測理由や因果関係をそのまま表すものではありません。業務説明には、別の説明手法やドメイン知識が必要です。
四つ目の誤解は、「表データならすべてTabTransformerでよい」というものです。表データといっても、数値中心の小規模データ、時系列性の強いデータ、階層構造を持つデータ、テキストや画像を含むデータなど、性質はさまざまです。モデルはデータの性質と目的に合わせて選ぶ必要があります。
まとめ
TabTransformerは、表形式データ、とくにカテゴリ特徴量を多く含むデータに対して、Transformerの自己注意を使って列同士の関係を学習するモデルです。カテゴリ値を埋め込みベクトルとして表現し、それらをTransformer層で更新することで、単独の列だけでは分かりにくい相互作用を捉えようとします。
一方で、TabTransformerは表データの万能解ではありません。LightGBM、XGBoost、CatBoostのような木系モデルは今でも非常に強力で、実務ではまず比較対象として使うべきです。TabTransformerを採用するかどうかは、カテゴリ列の多さ、データ量、特徴量間の複雑さ、精度向上の幅、説明可能性、運用コストを見て判断します。
初心者は、TabTransformerを「表データ版のTransformer」とだけ覚えるのではなく、カテゴリ特徴量を埋め込み、自己注意で列同士の関係を学ぶ表データ向けモデルとして理解すると実務に結びつけやすくなります。学習では、表データの基礎、カテゴリ前処理、木系モデル、ニューラルネットワーク、Transformerの順に積み上げると、モデルの役割と限界を整理できます。
更新履歴
| 日付 | 内容 |
|---|---|
| 2026年5月23日 | 初回公開 |