交差エントロピーとは?意味・計算・損失関数としての使い方をわかりやすく解説

AIの初心者
先生、「交差エントロピー」って何を測るものなんですか?

AI専門家
ひと言でいうと、正解の確率分布と、AIが予測した確率分布のズレを測る指標だよ。分類問題では、このズレを小さくするように学習を進めるんだ。
AIの初心者
値が小さいほど、正解に近い予測ができているということですか?
AI専門家
その通り。特に、正解ではないクラスを高い確率で選んでしまうと、交差エントロピーは大きくなるよ。
交差エントロピーとは
交差エントロピーとは、正解ラベルが表す確率分布と、モデルが出した予測確率分布のズレを数値化する指標です。主に分類問題の損失関数として使われ、値が小さいほど正解に近い予測、値が大きいほど正解から外れた予測を意味します。
交差エントロピーの定義
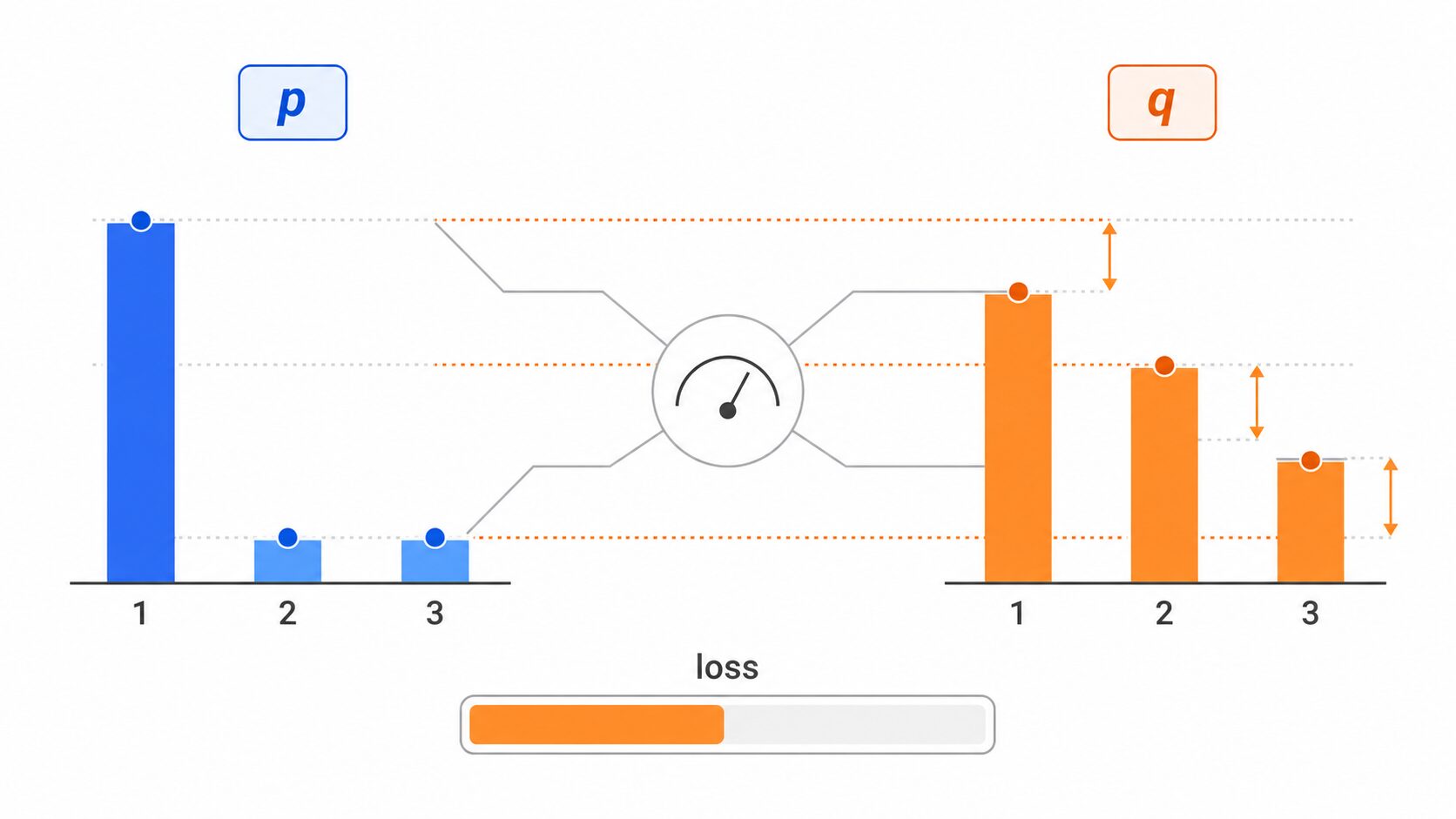
交差エントロピーは、機械学習の分類問題でよく使われる評価指標であり、損失関数です。ここでいう分類問題とは、画像を「猫・犬・鳥」のどれかに分ける、メールを「迷惑メール・通常メール」に分ける、文章の感情を「肯定・否定・中立」に分ける、といった問題を指します。
分類モデルは、多くの場合「どのクラスだと思うか」を1つだけ出すのではなく、各クラスに対する確率を出します。たとえば猫の画像に対して、モデルが「猫0.8、犬0.15、鳥0.05」と予測するような形です。
一方、正解ラベルも確率分布として見ることができます。正解が猫なら「猫1、犬0、鳥0」です。交差エントロピーは、この正解分布と予測分布がどれくらいズレているかを測ります。
交差エントロピーの値が小さいほど、モデルは正解クラスに高い確率を割り当てられていると考えられます。反対に、正解クラスの確率が低かったり、誤ったクラスに高い確率を割り当てたりすると、値は大きくなります。
| 見るもの | 意味 | 例 |
|---|---|---|
| 正解分布 | 本当のラベルを確率で表したもの | 猫が正解なら、猫1、犬0、鳥0 |
| 予測分布 | モデルが各クラスに割り当てた確率 | 猫0.8、犬0.15、鳥0.05 |
| 交差エントロピー | 正解分布と予測分布のズレの大きさ | 小さいほど正解に近い |
予測確率と正解ラベルのズレとして考える
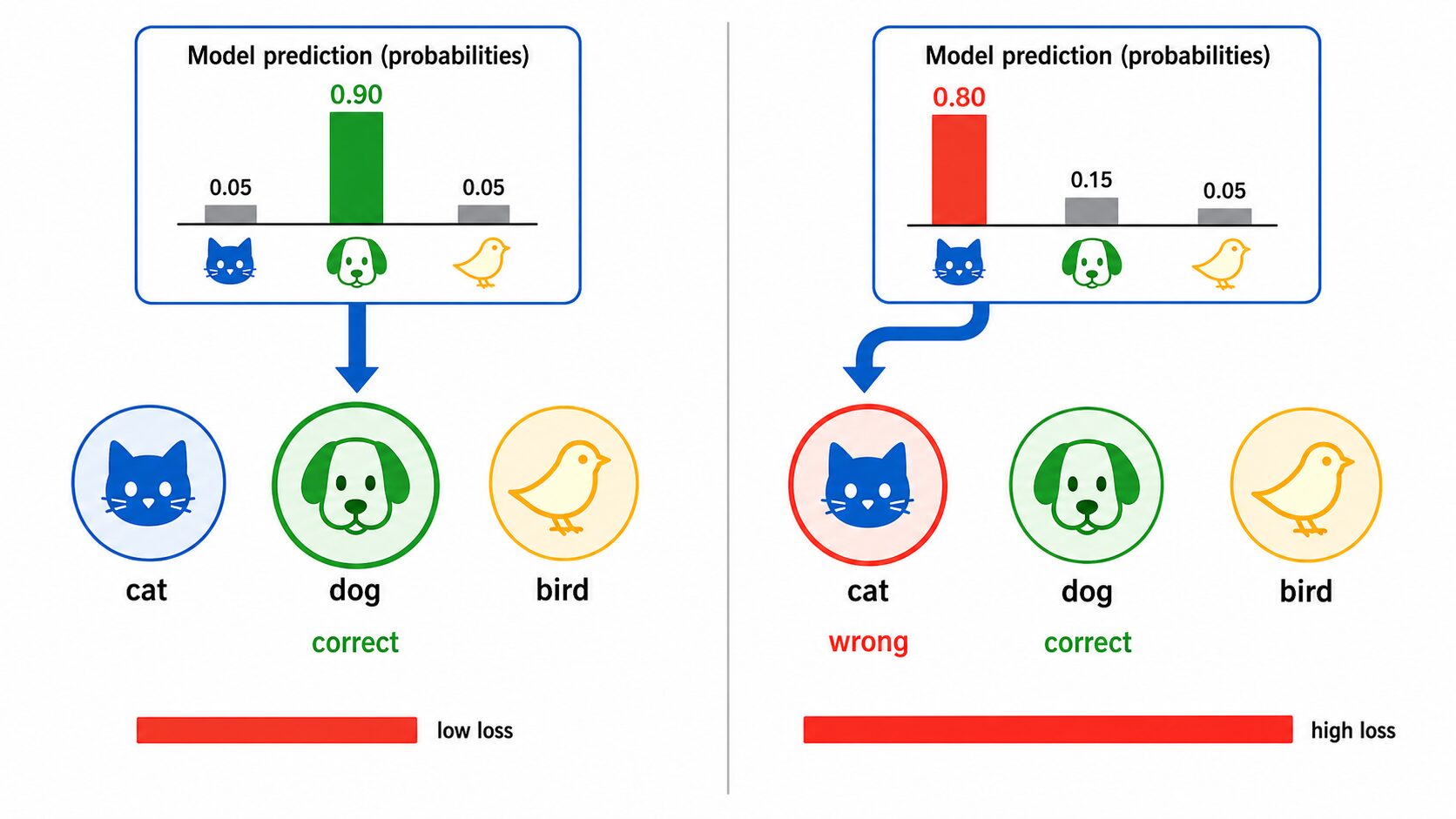
交差エントロピーを直感的に理解するには、「正解クラスにどれくらい高い確率を置けたか」を見ると分かりやすくなります。
たとえば正解が「猫」だとします。モデルが猫を0.9と予測した場合、正解にかなり近い予測です。猫を0.6と予測した場合は、正解ではあるものの少し迷っています。猫を0.1と予測した場合は、正解クラスに低い確率しか置けていないため、交差エントロピーは大きくなります。
特に重要なのは、交差エントロピーが「間違えたかどうか」だけでなく、「どれくらい自信を持って間違えたか」も反映する点です。正解が猫なのに、犬0.95、猫0.03と予測した場合、モデルは強い自信で誤分類しています。このような予測には大きな損失が与えられます。
この性質により、モデルは単に正解数を増やすだけでなく、正解クラスには高い確率を、誤ったクラスには低い確率を割り当てる方向へ学習しやすくなります。
| 正解 | モデルの予測 | 交差エントロピーの見方 |
|---|---|---|
| 猫 | 猫0.9、犬0.08、鳥0.02 | 正解クラスの確率が高く、損失は小さい |
| 猫 | 猫0.55、犬0.35、鳥0.10 | 正解だが迷いがあり、損失はやや大きい |
| 猫 | 猫0.03、犬0.95、鳥0.02 | 自信を持って誤分類しており、損失は大きい |
数式の読み方
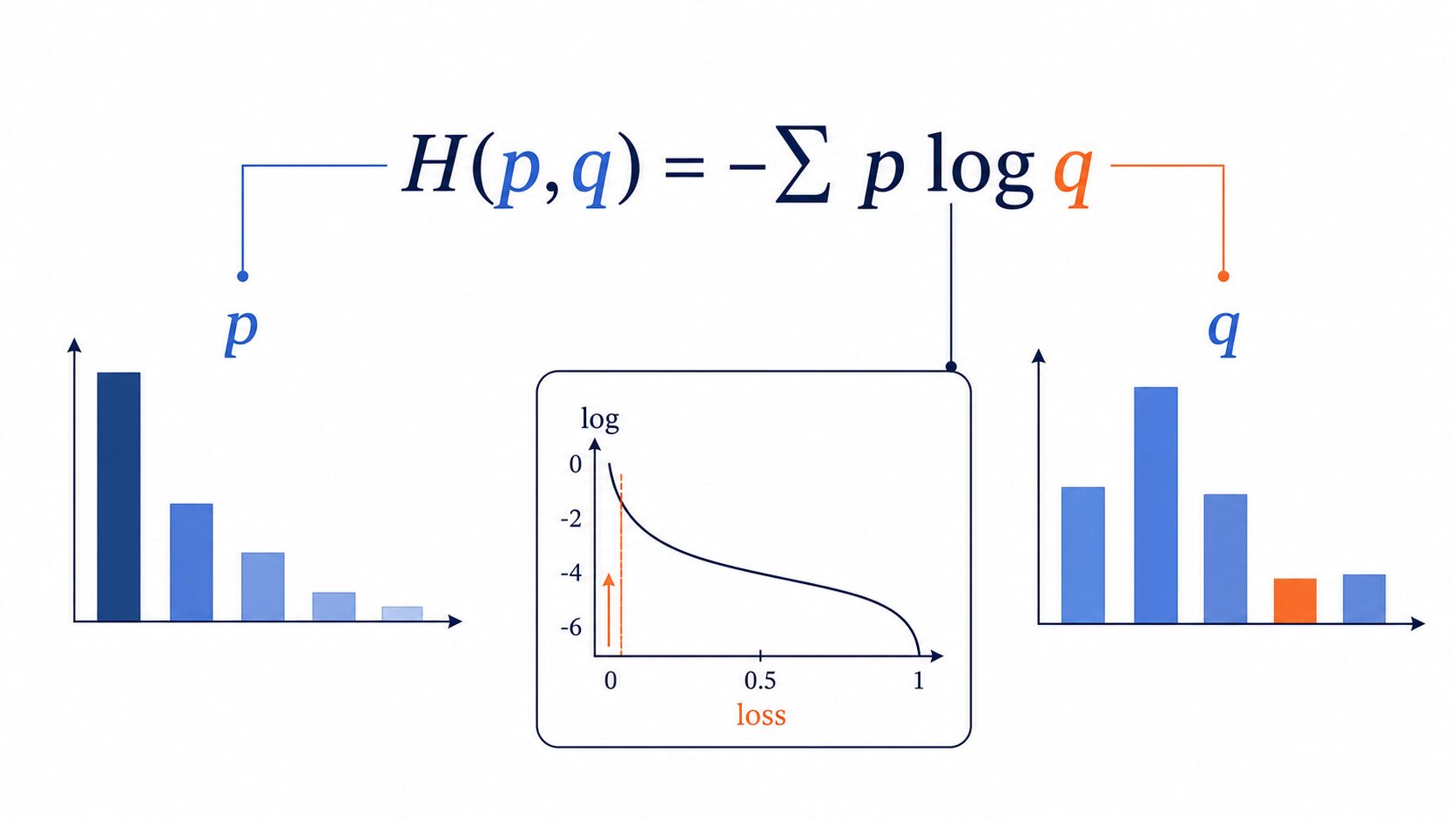
交差エントロピーは、一般に次のように表されます。
H(p, q) = – Σ p(x) log q(x)
この式を見ると難しく感じるかもしれませんが、分類問題で大切なのは「正解に対応する予測確率を見る」という点です。
p(x) は正解側の確率分布、q(x) はモデルの予測確率分布です。Σ は、すべてのクラスについて足し合わせるという意味です。ただし、正解ラベルが「猫1、犬0、鳥0」のような one-hot 表現であれば、p(x) が1になるのは正解クラスだけです。そのため、実際には正解クラスに対する q(x)、つまり予測確率が主に効いてきます。
正解クラスの予測確率を q とすると、交差エントロピーは大まかに「-log(q)」として読めます。q が1に近いほど -log(q) は0に近づき、q が0に近いほど大きな値になります。
交差エントロピーの数式は、正解クラスに低い確率を置いた予測ほど強く罰する仕組みだと捉えると理解しやすくなります。
| 記号 | 意味 | 初心者向けの読み方 |
|---|---|---|
| p | 真の確率分布 | 正解ラベル側の分布 |
| q | 予測確率分布 | モデルが出した各クラスの確率 |
| log | 対数 | 低い確率を強く目立たせる変換 |
| -Σ p(x) log q(x) | 交差エントロピー | 正解分布から見た予測分布のズレ |
損失関数としての役割
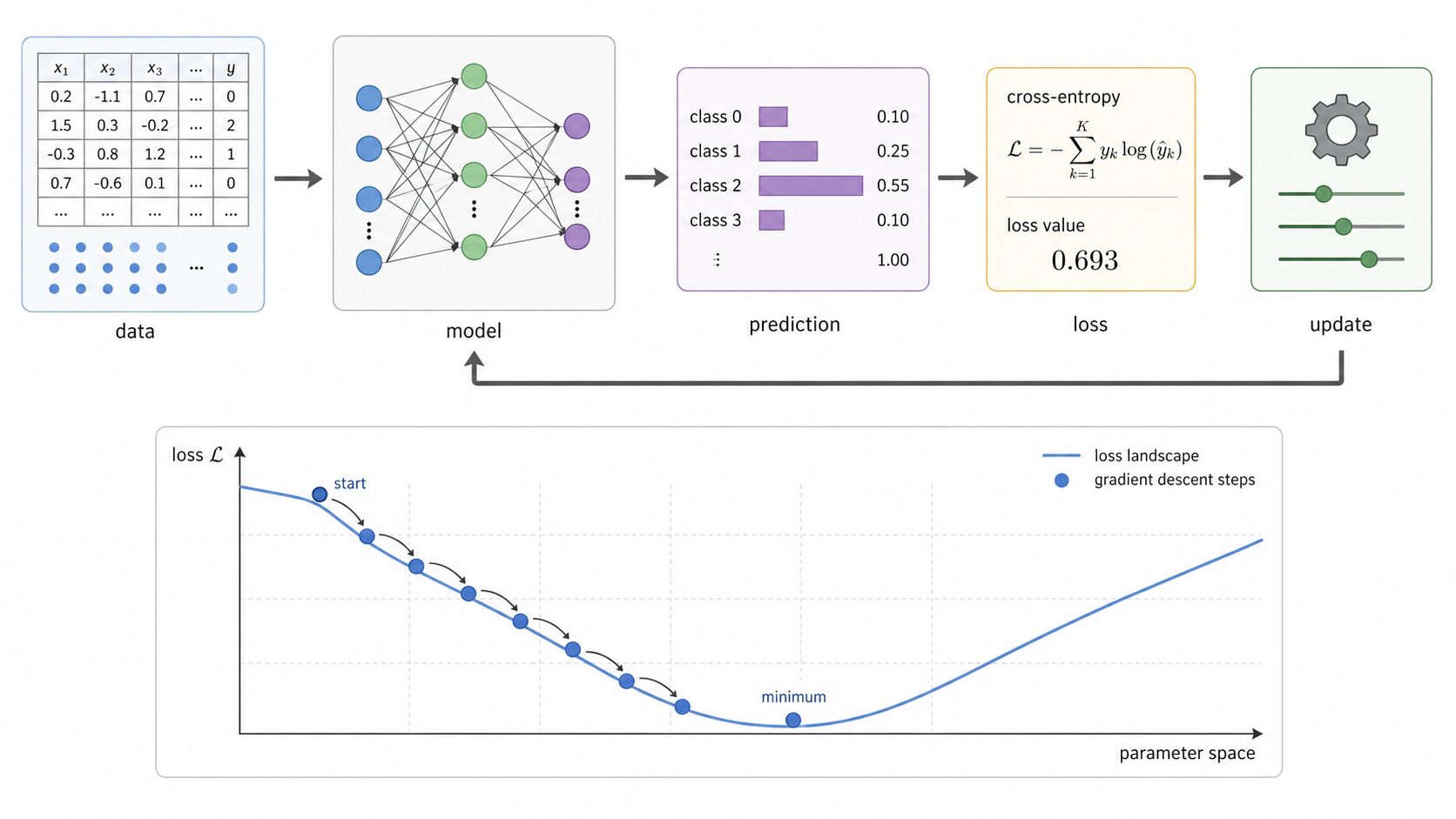
機械学習では、モデルの予測がどれくらい悪いかを数値で表す関数を損失関数と呼びます。学習の目的は、この損失を小さくすることです。
分類問題では、モデルが出した予測確率と正解ラベルを比べて、交差エントロピーを計算します。そして、その値が小さくなるようにモデル内部のパラメータを少しずつ更新します。
たとえば画像分類モデルなら、最初は猫の画像に対して「犬0.6、猫0.3、鳥0.1」のような予測をするかもしれません。このとき正解クラスである猫の確率が低いため、損失は大きくなります。学習が進むと「猫0.8、犬0.15、鳥0.05」のように、正解クラスへ高い確率を割り当てられるようになります。
この更新には、勾配降下法などの最適化手法が使われます。交差エントロピーは微分しやすく、ニューラルネットワークの出力層で使われる softmax や sigmoid と組み合わせやすいため、分類モデルの学習で広く利用されています。
| 学習の流れ | 内容 |
|---|---|
| 1. 予測する | モデルが各クラスの確率を出す |
| 2. 損失を計算する | 正解ラベルと予測確率から交差エントロピーを求める |
| 3. パラメータを更新する | 損失が小さくなる方向へモデルを調整する |
| 4. 繰り返す | 多くのデータで繰り返し、予測分布を正解分布に近づける |
分類問題で交差エントロピーを使う理由
交差エントロピーが分類問題で使われる主な理由は、分類モデルの出力が確率分布として扱いやすいからです。猫、犬、鳥のような多クラス分類では softmax により各クラスの確率を出し、迷惑メール判定のような二値分類では sigmoid により片方のクラスである確率を出すことがよくあります。
このとき交差エントロピーを使うと、モデルが「正解クラスにどれくらい確率を置けたか」を直接評価できます。平均二乗誤差のように数値の差を測る損失関数もありますが、分類では予測の確信度を自然に扱える交差エントロピーの方が適している場面が多くあります。
また、正解率だけでは学習の細かな改善を見落とすことがあります。たとえば、正解が猫で「猫0.51」と「猫0.95」はどちらも分類結果としては正解です。しかし、予測確率としては後者の方が自信を持って正解できています。交差エントロピーは、この違いを損失の差として表せます。
分類モデルを実務で扱うときは、正解率だけでなく、損失や予測確率の出方も一緒に確認することが重要です。
よくある誤解と注意点
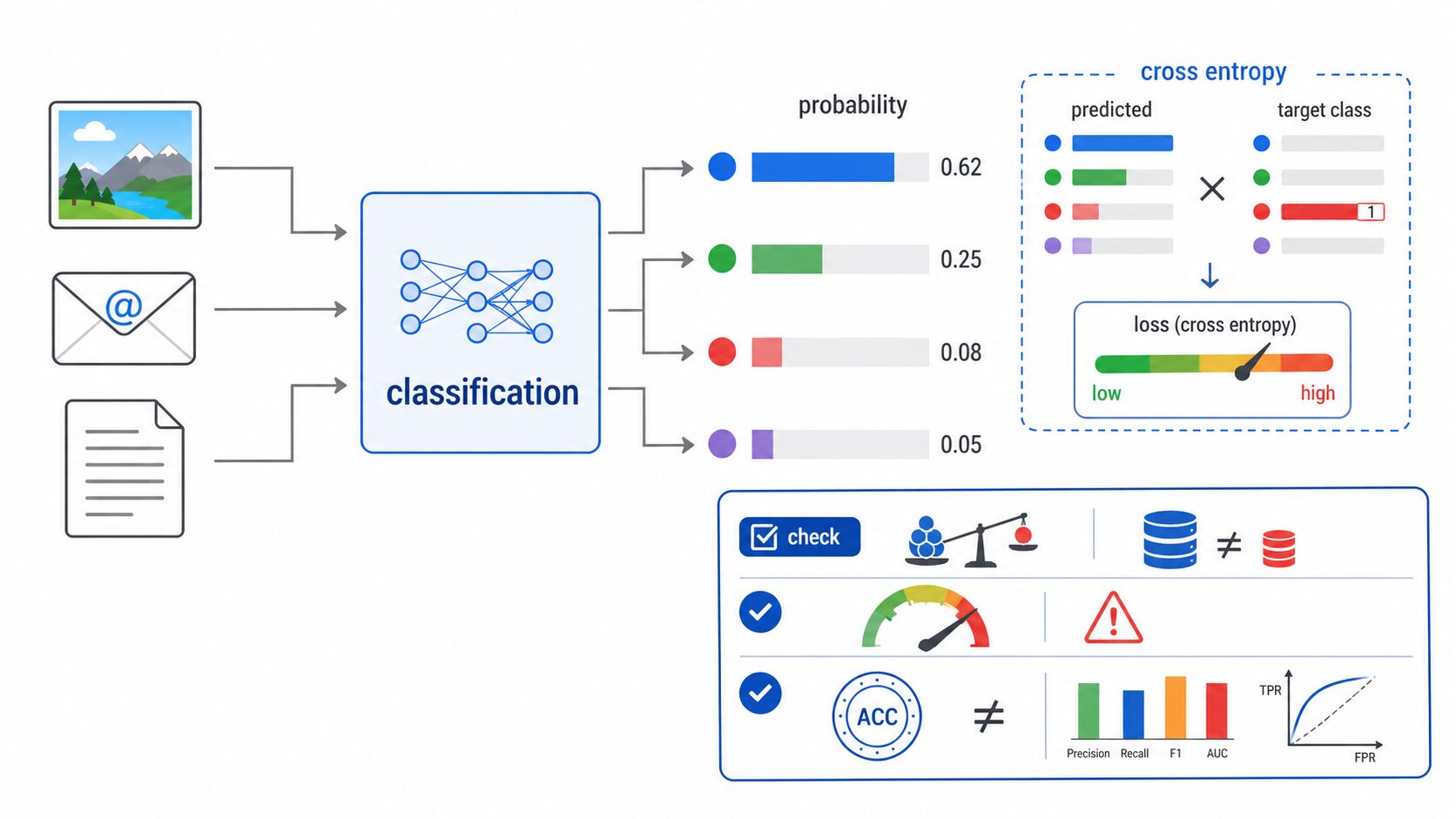
交差エントロピーは便利な指標ですが、いくつか注意点があります。まず、交差エントロピーは「相関」を見る指標ではありません。正解分布と予測分布のズレを測るものです。2つの変数が同じ方向に動くかを見る相関係数とは、目的も読み方も異なります。
次に、値そのものを単独で見すぎないことも大切です。交差エントロピーは、データセット、クラス数、ラベルの作り方、モデルの出力形式によって値の見え方が変わります。別のタスク同士で「損失が0.3だから良い」「1.2だから悪い」と単純に比べるのは危険です。
さらに、損失が小さければ常に実用上よいモデルとは限りません。クラスの偏りが大きいデータでは、多数派クラスに寄った予測でも一見よく見えることがあります。実務では、正解率、適合率、再現率、F1スコア、混同行列なども合わせて確認します。
確率の校正にも注意が必要です。交差エントロピーを小さくして学習したモデルでも、出力確率が現実の発生確率としてそのまま信頼できるとは限りません。重要な判定に使う場合は、検証データで確率の信頼性を確認する必要があります。
| 誤解・注意点 | 正しい見方 |
|---|---|
| 相関を測る指標だと思う | 交差エントロピーは確率分布のズレを測る指標 |
| 値だけでモデルを判断する | 同じタスク、同じ条件で比較することが大切 |
| 損失が小さければ実務で十分だと思う | 正解率やF1スコア、混同行列も確認する |
| 出力確率をそのまま信頼する | 必要に応じて確率の校正や検証を行う |
まとめ
交差エントロピーは、正解の確率分布とモデルの予測確率分布のズレを測る指標です。分類問題では、正解クラスに高い確率を割り当てられているほど値が小さくなり、正解クラスの確率が低いほど値が大きくなります。
数式では H(p, q) = – Σ p(x) log q(x) と表されますが、初心者はまず「正解クラスに置いた予測確率が高いほど損失は小さい」と理解するとよいでしょう。特に、自信を持って誤分類した予測には大きなペナルティが与えられます。
交差エントロピーは、分類モデルの損失関数として広く使われます。学習では、この値が小さくなるようにパラメータを更新し、予測分布を正解分布に近づけていきます。ただし、相関を測る指標ではなく、値の大小もタスク条件と合わせて読む必要があります。
実務では、交差エントロピーだけでなく、正解率、再現率、適合率、F1スコア、混同行列などを組み合わせて、モデルが目的に合った判断をしているか確認することが重要です。
更新履歴
| 日付 | 更新内容 |
|---|---|
| 2026年4月27日 | 記事全体をリライトし、交差エントロピーを確率分布のズレとして説明する構成に変更。数式、損失関数としての役割、分類問題で使う理由、注意点を整理し、画像5点の差し込み位置とalt文を追加。 |
| 2025年2月2日 | 初版公開。 |