
量子化とは?AIモデルを軽くする仕組みとメリットを解説

AIの初心者
「量子化」ってよく聞くんですけど、AIでは何をしているんですか?

AI専門家
簡単に言うと、AIモデルの中で使う数値を少ないビット数で表し、メモリ使用量や計算の負担を減らす技術だよ。
AIの初心者
数値を小さく表すだけで、どうしてAIモデルが軽くなるんですか?
AI専門家
たとえば32ビットで持っていた値を8ビットで扱えるようにすると、保存や転送に必要な量を大きく減らせる。うまく使えば推論も速くなるんだ。
量子化とは。
量子化は、AIモデルに含まれる重みや計算途中の値を、より少ないビット数で表現するモデル軽量化技術です。32ビット浮動小数点数を8ビット整数などに近似することで、モデルサイズ、メモリ使用量、推論時の計算負荷を下げられます。一方で、数値を粗く表すため精度が下がる場合もあり、用途に応じた検証が欠かせません。
量子化とは何か

AIにおける量子化とは、モデル内部の数値を少ない情報量で表す技術です。深層学習モデルは、多数の重み、バイアス、活性化値などの数値を使って計算します。通常は32ビット浮動小数点数のような高精度な形式で扱われますが、推論時にはそこまで細かい精度が不要な場合があります。
そこで、32ビットの値を8ビット整数などに変換し、近い値で代用します。写真を少し圧縮しても内容が分かるのと同じように、AIモデルでも数値表現を粗くしても予測性能を大きく損なわないケースがあります。この性質を利用して、モデルを小さく、速く、扱いやすくするのが量子化です。
ただし、量子化は「モデルの中身を適当に削る」処理ではありません。元の数値を限られた段階に写し替える処理であり、どの範囲をどの精度で表すかによって結果が変わります。だからこそ、量子化後の精度確認や実行環境での速度測定が重要になります。
量子化でAIモデルが軽くなる仕組み

コンピュータは数値を0と1の組み合わせで表します。この組み合わせの長さがビット数です。32ビットで表していた数値を8ビットで表せるようにすると、単純には保存に必要な容量を4分の1にできます。大きなモデルほど重みの数が多いため、この差はメモリ使用量や読み込み時間に大きく効いてきます。
量子化では、多くの場合、元の値の範囲を決め、その範囲を8ビットなら256段階の整数に対応させます。たとえば、ある層の重みが一定の最小値から最大値の間に収まると分かっていれば、その範囲を細かい目盛りに分け、元の値に最も近い目盛りへ丸めます。
考え方を式で表すと、元の値をスケールで割り、整数へ丸める処理になります。
\(q = \mathrm{round}(x / s) + z\)ここで、\(x\) は元の数値、\(q\) は量子化後の整数、\(s\) は値の幅を調整するスケール、\(z\) はゼロ点と呼ばれる補正値です。実際の実装では、モデルの層ごと、チャネルごと、重みと活性化ごとに適した範囲を決めることがあります。
この変換により、メモリから読み込むデータ量が減り、対応するハードウェアでは整数演算を使って推論を高速化できます。ただし、丸めによる誤差は避けられないため、どれくらい精度に影響するかを確認する必要があります。
量子化の主な種類
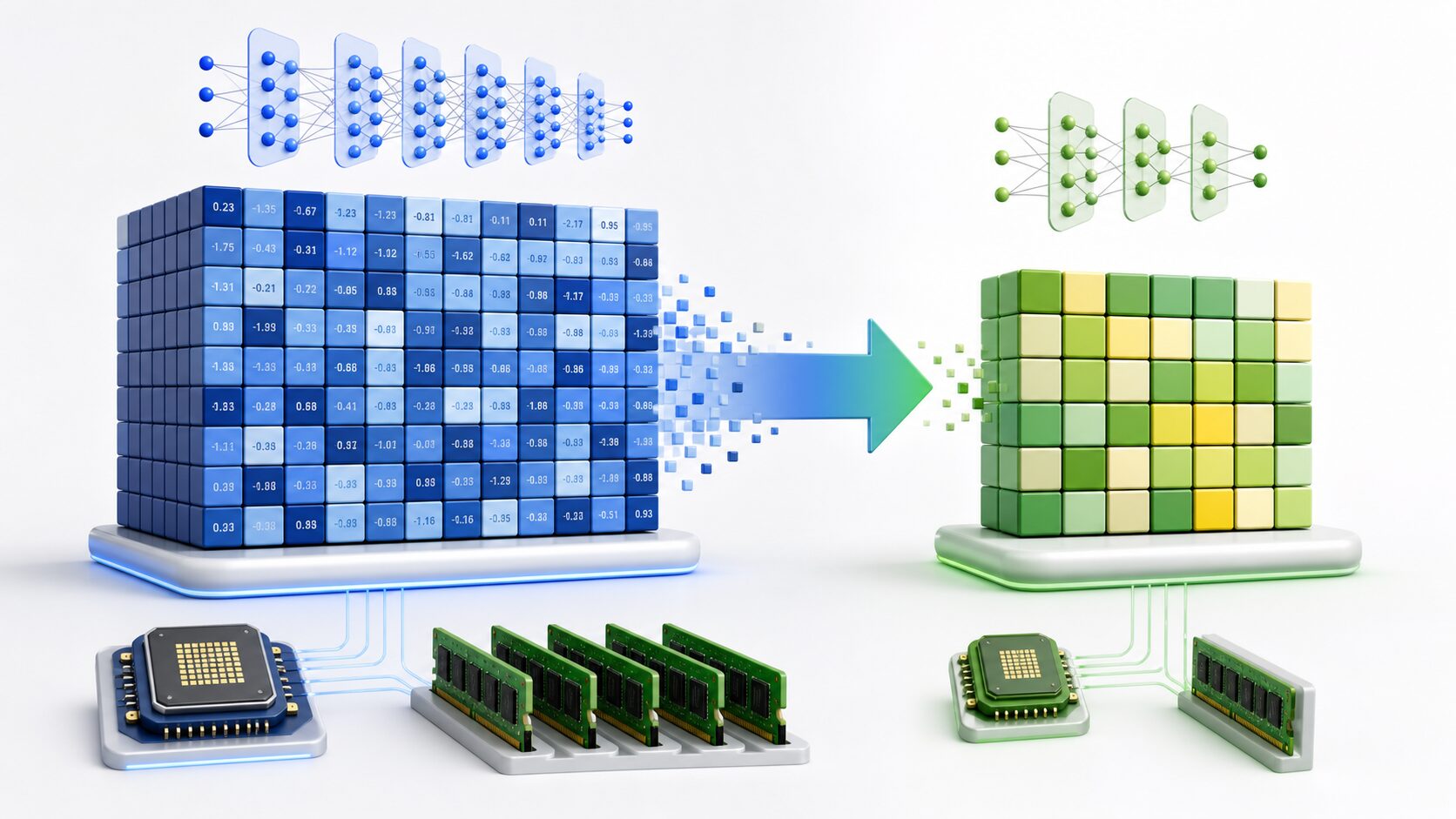
量子化には複数の方法があります。初心者がまず押さえるべきなのは、学習後量子化と量子化 aware trainingです。どちらもモデルを軽くする目的は同じですが、量子化を行うタイミングが異なります。
| 種類 | 概要 | 向いている場面 |
|---|---|---|
| 学習後量子化 | 学習済みモデルに対して後から量子化を適用する方法 | 短時間で軽量化を試したい場合、既存モデルを配布したい場合 |
| 量子化 aware training | 学習中から量子化の影響を模擬し、精度低下に慣らしながら学習する方法 | 精度をできるだけ保ちたい場合、重要な本番用途で使う場合 |
| 重み量子化 | モデルの重みを低ビットで表す方法 | モデルサイズやメモリ使用量を下げたい場合 |
| 活性化量子化 | 推論中に発生する中間値も低ビットで扱う方法 | 推論速度やメモリ帯域を改善したい場合 |
学習後量子化は導入しやすく、既に学習済みのモデルに適用できるのが利点です。一方で、モデルが量子化による丸め誤差に慣れていないため、タスクによっては精度が落ちやすくなります。
量子化 aware training は、学習中に量子化したときの誤差を疑似的に加えながら調整する方法です。手間は増えますが、精度を保ちやすい傾向があります。画像認識、音声認識、自然言語処理など、精度の要求が高い用途では候補になります。
量子化のメリット

量子化の代表的なメリットは、モデルサイズの縮小、推論速度の向上、消費電力の削減です。特にエッジAIやスマートフォン上のAI処理では、メモリ、処理能力、バッテリーに制約があるため、量子化の効果が分かりやすく現れます。
| メリット | 内容 | 具体例 |
|---|---|---|
| サイズ削減 | 重みを少ないビット数で保存し、モデルファイルを小さくする | 端末内にモデルを保存しやすくなる |
| 高速化 | 対応環境では低ビット整数演算を使って推論を速くできる | 画像分類や音声処理の応答が短くなる |
| 省電力化 | データ転送量や演算負荷を減らし、消費電力を抑える | バッテリー駆動の機器で使いやすくなる |
近年は、大規模言語モデルの推論コストを下げる目的でも量子化が注目されています。大きなモデルほど重みの保存と読み込みに多くのメモリが必要になるため、低ビット化によって動かせる環境が広がる可能性があります。
ただし、量子化すれば必ず速くなるわけではありません。実際の速度は、CPU、GPU、NPUなどのハードウェアが低ビット演算をどれだけ効率よく扱えるか、使用するライブラリが最適化されているかにも左右されます。
量子化の課題と注意点
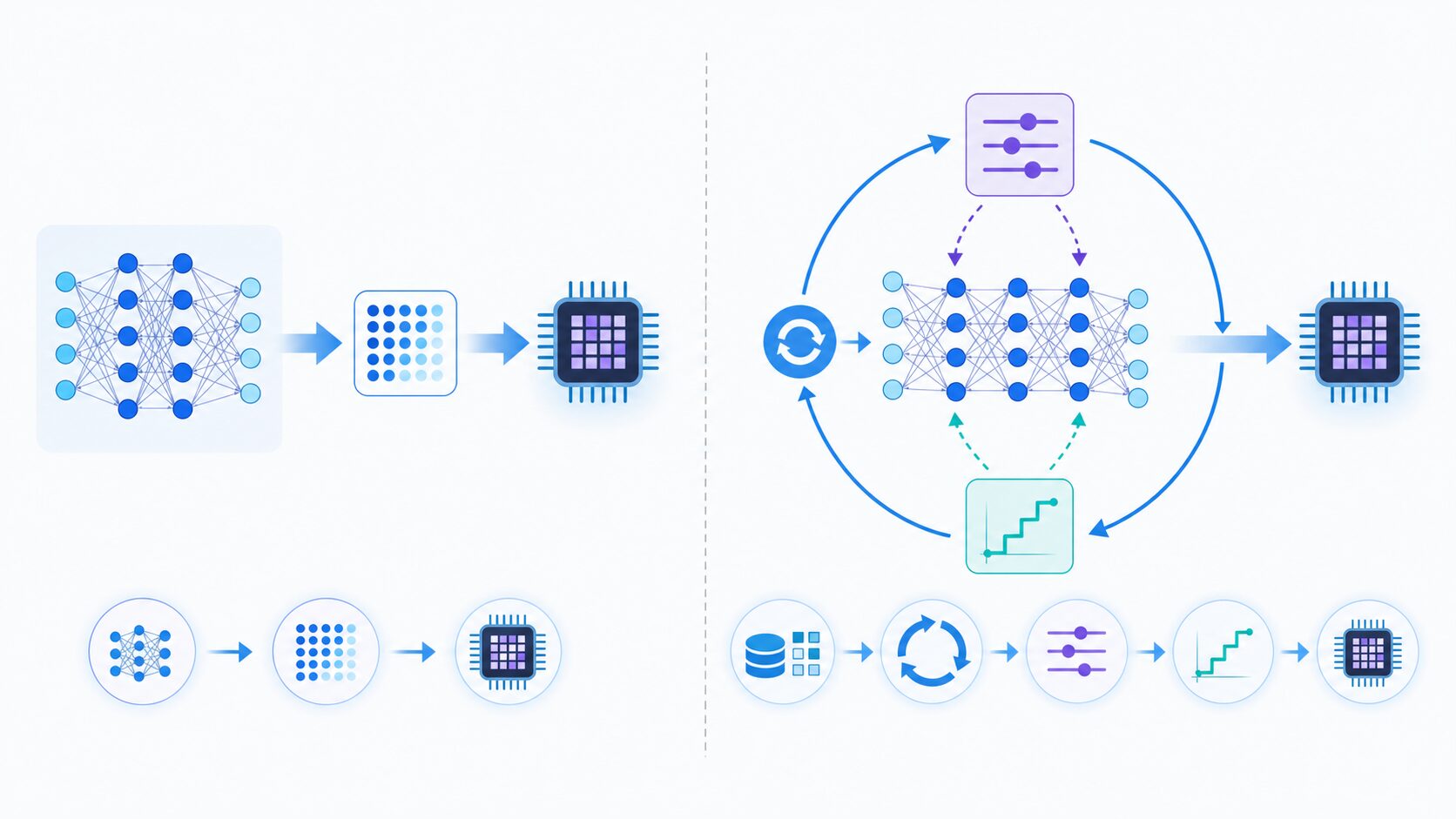
量子化の最大の課題は、数値を丸めることで情報が一部失われ、モデルの精度が下がる可能性があることです。色数を減らした画像では滑らかなグラデーションが段階的に見えるように、AIモデルでも細かい数値の違いが表しにくくなります。
特に、値の分布に外れ値が多いモデルや、微小な差が結果に大きく影響するタスクでは注意が必要です。全体の範囲を外れ値に合わせてしまうと、よく使われる値の周辺を十分に細かく表せなくなることがあります。この問題を抑えるために、層ごとやチャネルごとにスケールを変える方法が使われることもあります。
また、量子化後のモデルが実行環境で期待通りに動くかも確認しなければなりません。理論上は軽くなっても、対象のハードウェアや推論エンジンがその形式を効率よく扱えなければ、速度向上が小さい場合があります。導入時は、精度、レイテンシ、メモリ使用量、消費電力をセットで評価するのが現実的です。
量子化が使われる場面
量子化は、限られた計算資源でAIを動かしたい場面でよく使われます。代表例はスマートフォン、IoT機器、監視カメラ、車載機器、工場の小型端末などです。クラウドに毎回データを送らず、端末側で推論できれば、通信遅延や通信コスト、プライバシー面の課題を抑えやすくなります。
たとえば、カメラ映像から物体を検出するモデルを小型端末で動かす場合、大きな32ビットモデルのままではメモリに収まらなかったり、処理が追いつかなかったりします。量子化によってモデルを軽くできれば、より小さな機器でもリアルタイム処理に近づけます。
サーバー側でも、量子化は推論コストを抑える手段になります。多数のリクエストを処理するサービスでは、1回あたりの計算量やメモリ使用量を減らすことが運用コストに直結します。大規模モデルを扱うほど、この効果は無視できません。
ほかの軽量化手法との違い
AIモデルを軽くする方法は量子化だけではありません。代表的な関連手法には、枝刈り、知識蒸留、モデル圧縮があります。量子化との違いを押さえると、どの手法を選べばよいか判断しやすくなります。
| 手法 | 何を減らすか | 量子化との違い |
|---|---|---|
| 量子化 | 数値を表すビット数 | 重みや活性化の表現精度を下げる |
| 枝刈り | 重要度の低い重みや接続 | モデル構造の一部を削る |
| 知識蒸留 | 大きなモデルの振る舞いを小さなモデルへ移す | 別の小型モデルを学習する |
| モデル圧縮 | 保存形式や冗長性 | 広い意味では量子化を含む場合がある |
実務では、これらを組み合わせることもあります。たとえば、小型モデルを知識蒸留で学習し、さらに量子化して端末に載せる、といった使い方です。ただし、手法を重ねるほど精度や実装の検証項目も増えるため、目的に合わせて段階的に試すのが安全です。
量子化を学ぶときのポイント
量子化を理解するうえで大切なのは、「低ビット化すれば必ず良い」と考えないことです。8ビット、4ビット、さらに低いビット数へ進むほどモデルは軽くなりやすい一方、精度低下や実装上の制約も大きくなります。どこまで下げられるかは、モデル、データ、用途、実行環境によって変わります。
まずは、32ビット浮動小数点数と8ビット整数の違い、学習後量子化と量子化 aware training の違い、重み量子化と活性化量子化の違いを押さえると理解しやすくなります。そのうえで、実際のモデルでは量子化前後の精度、推論時間、メモリ使用量を比較すると、技術の効果を具体的に確認できます。
初心者の場合は、量子化を「AIモデルの数値を粗く近似し、実用上許せる範囲で軽くする技術」と捉えるとよいでしょう。完全に情報を保つ魔法ではなく、軽量化と精度のバランスを取るための調整技術です。
まとめ
量子化は、AIモデルの重みや中間値を少ないビット数で表し、モデルサイズや推論負荷を減らす技術です。32ビットの値を8ビットなどで扱えるようにすると、メモリ使用量やデータ転送量を削減でき、対応環境では推論速度や消費電力の面でも効果が期待できます。
一方で、数値を丸めるため精度低下のリスクがあります。学習後量子化は導入しやすく、量子化 aware training は精度を保ちやすいなど、それぞれに特徴があります。AIモデルを実際に使う場面では、軽さだけでなく、精度、速度、消費電力、実行環境との相性を合わせて評価することが重要です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月21日 | 量子化方式の比較と精度検証の観点を追記 |