オープンデータセット:機械学習を加速する宝の山

AIの初心者
先生、「公開されたデータセット」って、誰でも使えるデータのことですよね?どんな種類のデータがあるんですか?

AI専門家
そうだね。誰でも使えるデータのことだよ。種類は様々で、例えば、手書きの数字の画像データや野球選手のデータ、文章データなど、色々な種類のデータがあるんだ。
AIの初心者
へえー、色々なデータがあるんですね。それって、どうやって使うんですか?
AI専門家
機械学習のプログラムに学習させるために使うことが多いね。例えば、手書き数字の画像データを学習させると、コンピューターが数字を認識できるようになるんだよ。もちろん、使うときは、データの出どころや使い方のルールを確認する必要があるよ。
オープンデータセットとは。
「人工知能」についての言葉である「公開データ群」について説明します。公開データ群とは、みんなの役に立つことや研究のために、広く公開されていて、誰でも無料で使えるデータの集まりのことです。特に、機械学習やデータ分析の取り組み、例えば大学の研究や教育などでよく使われています。有名なデータ群としては、手書きの数字画像を集めた「エムニスト」や、アメリカの野球リーグの選手データなどがあります。言語モデルに使えるデータ群としては、「ザ・パイル」や「レッドパジャマ」などがあります。誰でも使えるデータではありますが、データの出どころや信頼できるかどうかを確認することが大切です。また、それぞれ使い方のルールがあるものもあるので、それに従う必要があります。さらに、すべてのデータをそのまま使うのではなく、良い結果が得られるようなデータを選び、正しく学習できるように準備を整えることも大切です。
無料公開データ:活用の利点

誰もが自由に使えるように公開されたデータの集まり、いわゆる公開データは、機械学習やデータ分析などの分野で研究開発を大きく前進させる力強い味方となっています。その利点は、費用を抑えられるだけにとどまりません。質の高いデータに容易に手が届くことも大きな魅力です。
例えば、人の顔や物の形などを機械に認識させる画像認識の研究には、大量の画像データが欠かせません。公開データを使えば、データを集める手間と費用を大幅に減らすことができます。膨大な数の画像データを集めるのは大変な労力と費用がかかりますが、公開データは、その負担を軽減してくれるのです。さらに、多くの研究者によって既に綿密に調べられ、確かな品質と認められたデータを使うことで、研究の信頼性を高めることにもつながります。
公開データは公共の利益や研究のために公開されているため、様々な種類のデータが利用可能です。気象データや人口統計データ、地図情報など、多岐にわたるデータが入手できます。これらのデータを活用することで、新しい発見や技術革新を生み出す可能性が広がります。例えば、ある地域の人口動態と商業施設の分布を組み合わせることで、新たな出店計画のヒントが得られるかもしれません。また、気象データと農作物の生育状況を分析すれば、より効率的な農業を実現できる可能性も秘めています。
公開データは、誰もが利用できることから、情報共有や共同研究を促進する効果も期待できます。研究者同士がデータを共有し、互いの成果を参考にしながら研究を進めることで、より質の高い研究成果を生み出すことができるでしょう。また、企業や自治体も公開データを利用することで、地域社会の課題解決や新たなサービス開発に役立てることができます。このように、公開データは、様々な分野でイノベーションを促し、社会の発展に貢献する貴重な資源と言えるでしょう。
| 公開データのメリット | 詳細 | 具体例 |
|---|---|---|
| 低コスト | データ収集の手間と費用を大幅に削減 | 画像認識研究における大量の画像データ収集 |
| 高品質 | 綿密に調べられ、確かな品質と認められたデータ | 信頼性の高い研究に貢献 |
| 多様性 | 多岐にわたるデータが入手可能 | 気象データ、人口統計データ、地図情報など |
| イノベーション促進 | 新しい発見や技術革新の可能性を広げる | 人口動態と商業施設分布の組み合わせによる出店計画、気象データと農作物生育状況の分析による効率的な農業 |
| 情報共有・共同研究 | 誰もが利用できるため、情報共有や共同研究を促進 | 研究者間のデータ共有、企業や自治体による地域課題解決やサービス開発 |
著名なデータセット:種類と用途

数多くの公開されている情報群の中でも、特に広く知られ、活用されているものには様々な種類があります。その代表的な例として、手書き数字の画像情報群であるmnistと、野球選手の成績情報群が挙げられます。mnistは、0から9までの手書き数字の画像を大量に集めたもので、数字を自動で認識する技術の向上に大きく貢献してきました。機械学習の入門教材として広く利用されており、多くの学習者がこの情報群を使って数字認識の仕組みを学んでいます。学習の初期段階で用いられることが多く、比較的単純な構造を持つため、初心者でも扱いやすいという利点があります。
一方、野球選手の成績情報群は、選手の成績や年俸、出場試合数といった様々な情報を集めたものです。この情報群を活用することで、選手の能力評価や年俸の妥当性、チームの戦略分析など、様々な分析を行うことができます。スポーツ界における情報分析の発展に大きく寄与しており、チームの強化や選手の育成に役立っています。近年注目されている情報に基づいた選手評価や戦略立案も、この情報群のような質の高い情報があってこそ実現できるものです。
さらに、近年は言語モデルの学習に用いることができる巨大な情報群も登場しています。例えば、ThePileやRedPajamaといった情報群は、インターネット上の記事や書籍など、膨大な量の文章情報から構成されています。これらの情報群を用いることで、人間のように自然な文章を生成したり、質問に答えたりする高度な言語モデルを学習させることができます。これらの言語モデルは、文章の自動要約や翻訳、会話ロボットなど、様々な分野への応用が期待されています。このように、様々な種類の大規模情報群が公開されていることで、多くの分野における研究開発や情報に基づいた意思決定が促進されています。
| 情報群 | 内容 | 用途 | 特徴 |
|---|---|---|---|
| mnist | 0から9までの手書き数字の画像 | 数字の自動認識、機械学習入門教材 | 単純な構造で初心者向け |
| 野球選手の成績情報群 | 選手の成績、年俸、出場試合数など | 選手能力評価、年俸妥当性分析、チーム戦略分析 | スポーツ界の情報分析に貢献 |
| The Pile, RedPajama | インターネット上の記事、書籍など膨大な量の文章情報 | 高度な言語モデルの学習 | 自然な文章生成、質問応答、文章要約、翻訳、会話ロボットなどへの応用 |
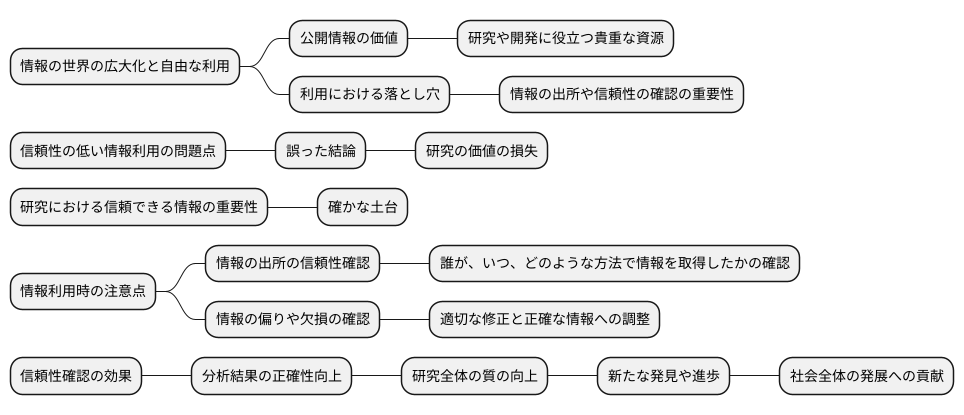
データの信頼性:確認の重要性

情報の世界は広大であり、誰もが様々な情報を自由に利用できるようになりました。特に、誰もが利用できる公開された情報のかたまりは、様々な研究や開発に役立つ貴重な資源となっています。しかし、その便利さの裏には、落とし穴も存在します。誰でも利用できるということは、情報の出所や信頼性をしっかり確認することが非常に大切になるのです。
もし、信頼性の低い情報を使って分析を行ってしまうと、どうなるでしょうか。結果は明白です。誤った結論に導かれ、せっかくの研究の価値を損ねてしまう可能性があります。家を建てる時、土台がしっかりしていなければ、どんなに立派な家を建てても、いずれ崩れてしまうのと同じです。研究においても、信頼できる情報こそが、確かな土台となるのです。
そのため、情報を使う際には、その情報の出所が信頼できるか、どのようにしてその情報が集められたのかを慎重に確認する必要があります。誰が、いつ、どのような方法でその情報を得たのかを知ることで、情報の信頼性を判断する材料となるのです。また、情報に偏りがないか、情報が欠けている部分がないかも注意深く確認する必要があります。もし、情報に偏りや欠損があれば、適切な修正を行い、より正確な情報へと整えることが重要です。
このように、情報の信頼性を丁寧に確認することで、分析結果の正確さが向上し、研究全体の質を高めることに繋がります。信頼できる情報を土台に築かれた研究は、新たな発見や進歩を生み出す力となり、社会全体の発展に貢献していくのです。
利用規約:遵守の必要性

公開されているデータの集まりには、使い方に関する決まりが定められていることがよくあります。この決まり事を利用規約と呼びます。利用規約には、データを使って何ができるのか、どこまで使っていいのか、作った人の権利はどうなっているのかといった大切なことが書かれています。ですから、データを使う時は、必ず利用規約をよく読んで、その内容を守ることが必要です。
もし規約に反してデータを使ってしまうと、法律に抵触するなどの問題が起こるかもしれません。例えば、許可されていない商用利用や、データの改ざん、再配布などは、規約で禁止されていることが多いです。また、データを提供してくれた人への感謝の気持ちを忘れないことも大切です。データは誰かが時間と労力をかけて作ってくれたものです。そのことを忘れずに、大切に扱うべきです。
利用規約を守ることは、データを提供してくれた人との信頼関係を築く上でとても重要です。信頼関係が築かれることで、より多くのデータが公開されるようになり、データを使う私たちにも多くの利益がもたらされます。また、利用規約をきちんと守ることで、データの質が保たれ、安心してデータを使うことができます。これは、データの世界をより良くしていくことに繋がります。みんなで気持ちよくデータを使えるように、利用規約は必ず守りましょう。データの公開と利用が活発になれば、様々な分野で新しい発見や発展が期待できます。そのためにも、利用規約を遵守することは、私たち一人ひとりの責任と言えるでしょう。
| 公開データの利用規約 |
|---|
| データの使い方に関する決まり事 |
|
| 利用規約を遵守する重要性 |
|
| 利用規約遵守は利用者の責任 |
データの前処理:適切な処理

多くの公開された情報をうまく活用するには、準備段階がとても大切です。集めたままの情報をそのまま使うのではなく、目的とする解析に役立つ情報を選び出し、使い方に合わせた準備をする必要があるのです。この準備段階を適切に行うことで、解析結果の正しさを高めたり、解析にかかる時間を短縮したりすることができます。
例えば、集めた情報の中に誤りや異常な値が混ざっていると、解析結果に悪影響を与える可能性があります。このような不要な情報を取り除いたり、情報が足りない部分を補ったりすることで、解析の精度を向上させることができます。情報の質を高めることは、建物を建てる前に土台をしっかりと固めるようなものです。
また、情報の形式を揃えることも重要です。住所の書き方がバラバラだったり、日付の表記が統一されていなかったりすると、機械は情報を正しく理解することができません。情報を整理し、同じ形式に揃えることで、機械がスムーズに情報を処理できるようになり、解析の効率を高めることができます。これは、図書館の本を整理して、誰でも簡単に目的の本を見つけられるようにするのと似ています。
さらに、数値の範囲を調整する作業も有効です。例えば、ある数値が0から100までの範囲で、別の数値が10000から1000000までの範囲だと、数値の大小関係が分かりにくく、解析に悪影響を及ぼす可能性があります。数値の範囲を調整することで、それぞれの数値の重要度を適切に反映させ、より正確な解析結果を得ることができます。これは、音量の異なる楽器を演奏する際に、それぞれの音量バランスを調整するようなものです。
このように、情報の種類や解析の目的に合わせて適切な準備を行うことは、公開されている情報の価値を最大限に引き出し、より良い結果を得るために欠かせません。
| 準備段階の作業 | 作業内容 | 効果 | 例え |
|---|---|---|---|
| 情報の取捨選択と補完 | 誤りや異常値の除去、不足情報の補完 | 解析精度の向上 | 建物の土台を固める |
| 情報の形式の統一 | 住所、日付などの表記を統一 | 機械による処理効率の向上 | 図書館の本の整理 |
| 数値範囲の調整 | 数値の範囲を調整し、重要度を適切に反映 | 解析結果の精度向上 | 楽器の音量バランス調整 |