アルゴリズム
アルゴリズム 人工知能を動かす指示:アルゴリズム
あらゆる人工知能は、指示が必要です。この指示は、人間の指示とは少し違います。人間への指示は、具体的な行動を一つ一つ伝えるものですが、人工知能への指示は、考え方の道筋を示すものです。ちょうど、料理のレシピのようなものです。レシピには、材料や調理手順が細かく書かれています。しかし、レシピ通りに作ったとしても、料理人の腕前や使う道具によって、味は変わってきます。人工知能も同じで、指示は、どのような手順で物事を考え、判断するかという基本的な枠組みを与えるものです。
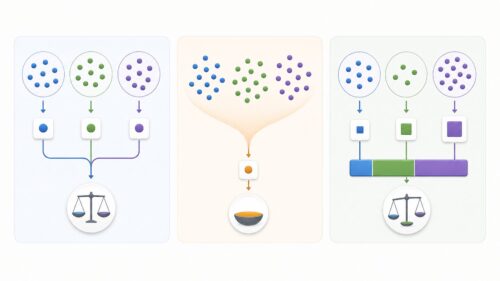
この指示を、私たちは「算法」と呼びます。算法は、人工知能のふるまいを決める設計図のようなものです。人工知能は、この設計図に基づいて、大量の情報を学び、自ら考え、判断する力を身につけていきます。例えば、猫の画像を見分ける人工知能を作るとします。人間は、猫の特徴を言葉で説明することはできますが、人工知能にはそれが理解できません。そこで、大量の猫の画像と、猫ではない画像を人工知能に学習させます。この学習の際に、「算法」が重要な役割を果たします。算法は、画像の中から、猫の特徴を見つけ出す方法を人工知能に教えます。どの部分に着目すればいいのか、どのような計算をすればいいのか、といったことを細かく指示するのです。
人工知能は、この算法に従って学習を続け、次第に猫を見分ける能力を高めていきます。そして、最終的には、初めて見る猫の画像でも、それが猫であると正しく判断できるようになるのです。このように、人工知能は、人間が作った算法という設計図に基づいて学習し、成長していくのです。人工知能の性能は、この算法の良し悪しに大きく左右されます。より精度の高い、より効率の良い算法を開発することが、人工知能研究の重要な課題の一つとなっています。