マクロF1値とは?多クラス分類の評価方法と計算の考え方を解説

AIの初心者
「マクロF1」って、分類モデルの評価でよく見かけます。正解率とは何が違うんですか?

AI専門家
マクロF1は、複数の分類項目それぞれのF1値を同じ重みで平均する指標だよ。データ数が少ない分類項目も軽く扱わずに評価できるのが特徴なんだ。
AIの初心者
少ない分類項目も同じように見る、ということですね。どんな場面で重要になるのでしょうか?
AI専門家
例えば、犬・猫・鳥を分類するモデルで、犬の画像だけが多い場合を考えるとわかりやすいよ。正解率だけでは犬をよく当てるモデルが高く見えがちだけれど、マクロF1なら猫や鳥の分類性能も同じ重みで確認できるんだ。
macro-F1とは。
多クラス分類で、各クラスのF1値を同じ重みで平均してモデルの性能を評価する指標です。0から1の値を取り、1に近いほど各クラスをバランスよく分類できていると考えます。
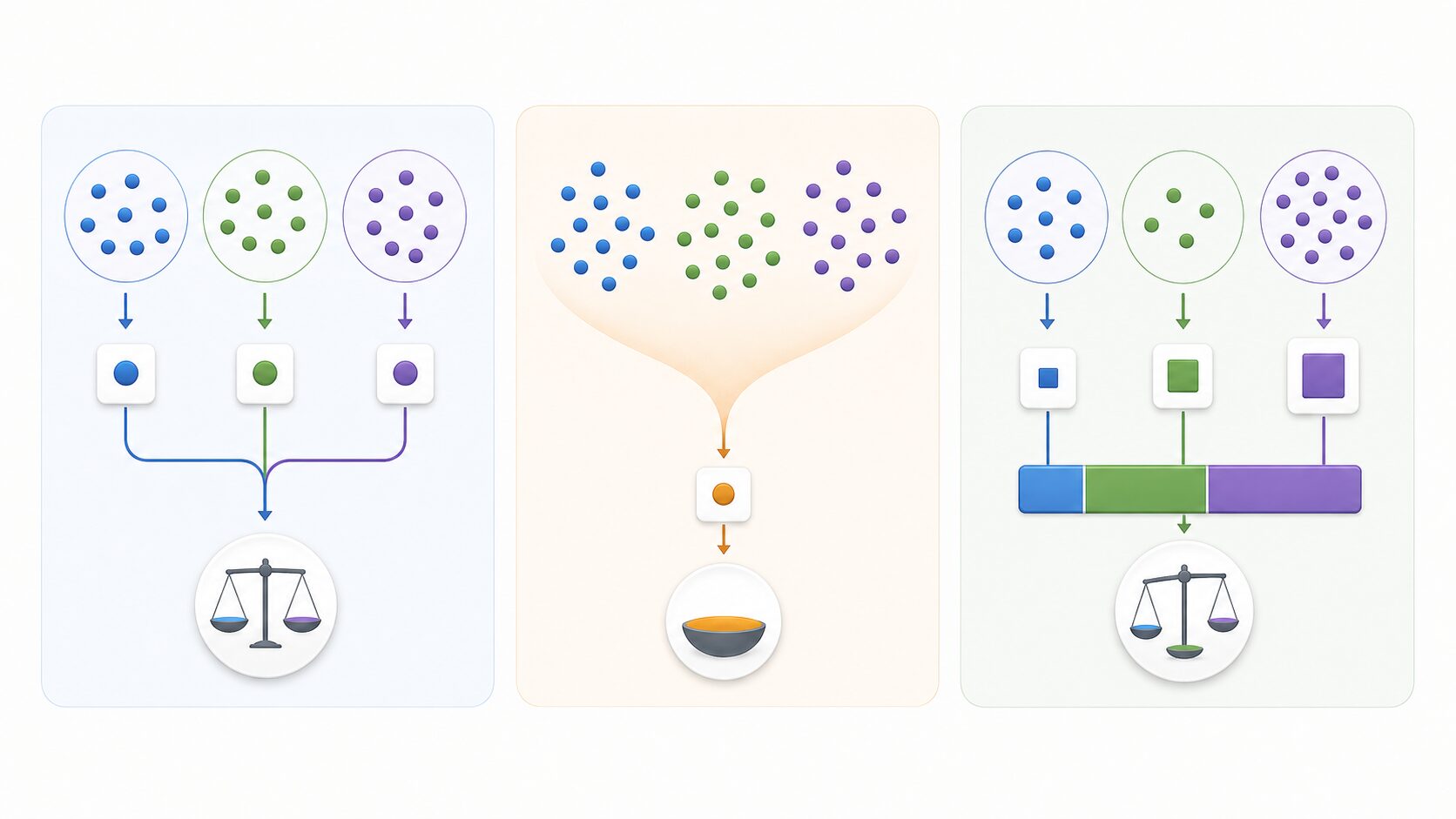
マクロF1値とは
マクロF1値とは、多クラス分類において、クラスごとに計算したF1値を単純平均した評価指標です。値は0から1の範囲で表され、1に近いほど分類モデルが各クラスをうまく識別できていることを示します。
多クラス分類とは、入力データを3種類以上のクラスに分ける問題です。たとえば、画像を「犬」「猫」「鳥」に分類する、ニュース記事を「政治」「経済」「スポーツ」に分類する、問い合わせ内容を「請求」「技術」「契約」に分類する、といったケースが該当します。
このような分類問題では、単純な正解率だけではモデルの実力を見誤ることがあります。あるクラスのデータが非常に多い場合、モデルがその多数派クラスをよく当てるだけで、全体の正解率が高く見えてしまうためです。少数派クラスをほとんど当てられていなくても、正解率だけでは問題が見えにくいことがあります。
マクロF1値は、各クラスを同じ重みで評価するため、データ数の少ないクラスの性能も確認しやすい指標です。クラス不均衡があるデータで、どの分類項目も同じように重要だと考える場合に特に役立ちます。
| 項目 | 内容 |
|---|---|
| 指標の目的 | 多クラス分類で各クラスの分類性能を平等に評価する |
| 値の範囲 | 0から1。1に近いほど良い |
| 計算の考え方 | クラスごとのF1値を計算し、それらを単純平均する |
| 向いている場面 | クラスごとのデータ数に偏りがあり、少数クラスも重視したい場面 |
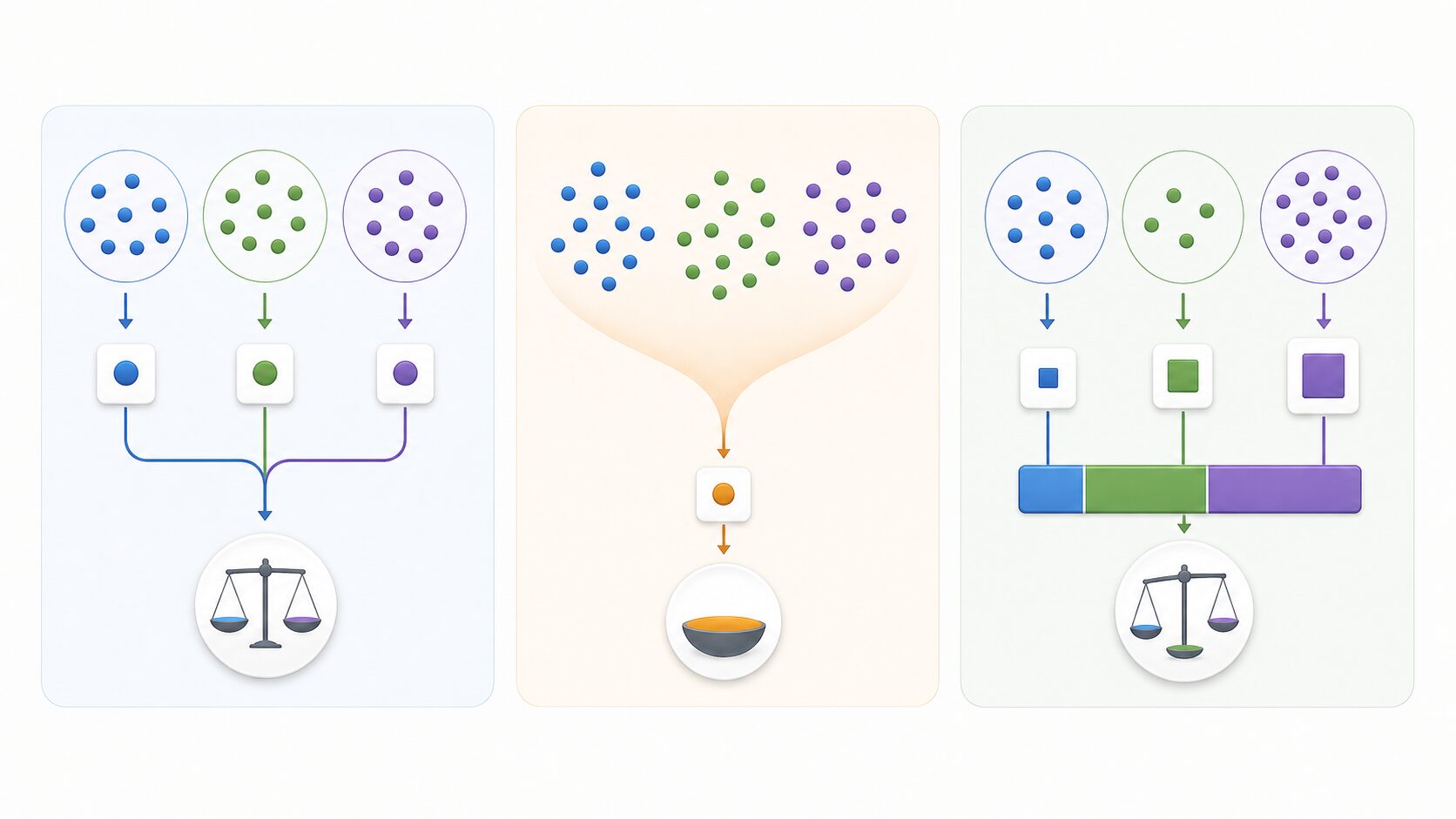
F1値を構成する適合率と再現率
マクロF1値を理解するには、まずF1値を構成する適合率と再現率を押さえる必要があります。F1値は、適合率と再現率の調和平均として計算されます。
適合率は、モデルがあるクラスだと予測したデータのうち、実際にそのクラスだった割合です。たとえば、モデルが20件を「陽性」と予測し、そのうち15件が本当に陽性だった場合、適合率は15÷20で0.75になります。予測した結果の正しさを見たいときに重要です。
再現率は、実際にそのクラスだったデータのうち、モデルが正しく見つけられた割合です。実際の陽性が30件あり、そのうち15件を陽性と予測できた場合、再現率は15÷30で0.5になります。見逃しをどれだけ減らせているかを見たいときに重要です。
F1値は、この2つのバランスを見るための指標です。適合率だけが高くても、再現率だけが高くても、F1値は高くなりにくい性質があります。つまり、正しく予測する力と、必要な対象を取りこぼさない力をまとめて見るための値です。
\(F1 = \frac{2 \times Precision \times Recall}{Precision + Recall}\)たとえば適合率が0.75、再現率が0.5の場合、F1値は 2 × 0.75 × 0.5 ÷ (0.75 + 0.5) = 0.6 です。初心者がつまずきやすい点は、F1値が単純な平均ではないことです。調和平均を使うため、片方の値が低いと全体の値も伸びにくくなります。
| 指標 | 見るもの | 例 |
|---|---|---|
| 適合率 | 予測したものがどれだけ正しかったか | 陽性と予測した20件中15件が正解なら0.75 |
| 再現率 | 実際の対象をどれだけ見つけられたか | 実際の陽性30件中15件を見つけたなら0.5 |
| F1値 | 適合率と再現率のバランス | 適合率0.75、再現率0.5なら0.6 |
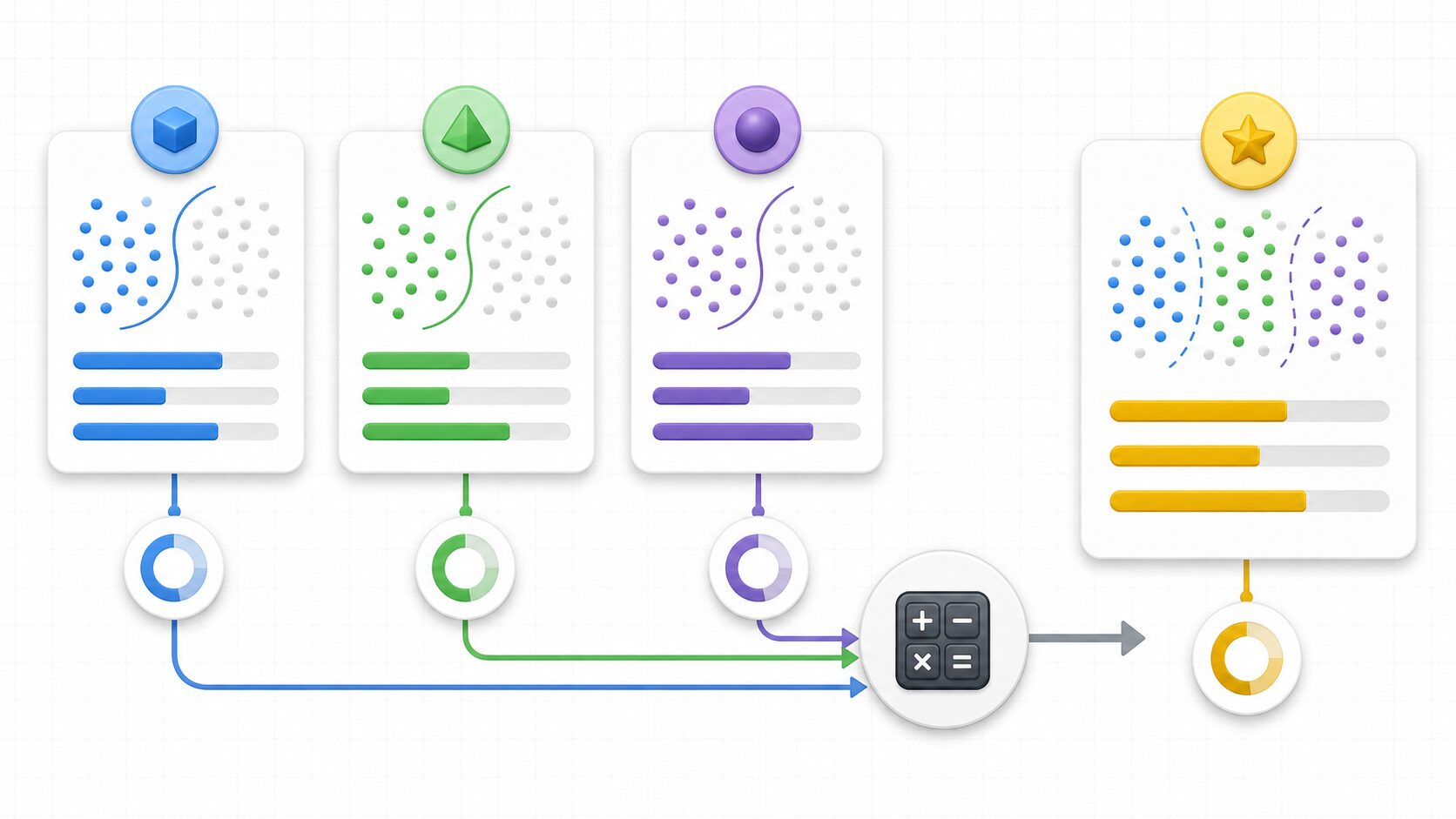
マクロF1値の計算方法
マクロF1値は、各クラスを1つずつ「注目するクラス」として扱い、それぞれのF1値を計算してから平均します。犬・猫・鳥の3クラス分類であれば、犬のF1値、猫のF1値、鳥のF1値をそれぞれ求め、その3つを足して3で割ります。
\(Macro\ F1 = \frac{F1_1 + F1_2 + \cdots + F1_K}{K}\)ここでKはクラス数です。犬のF1値が0.90、猫のF1値が0.70、鳥のF1値が0.50なら、マクロF1値は (0.90 + 0.70 + 0.50) ÷ 3 = 0.70 になります。
この計算方法の重要な点は、各クラスのデータ数を重みに使わないことです。犬の画像が1000枚、猫が100枚、鳥が20枚であっても、犬・猫・鳥のF1値は同じ1クラス分として平均されます。したがって、少数クラスの性能が低ければ、マクロF1値にも反映されやすくなります。
一方で、クラスごとの重要度が本当に同じかは、業務や研究の目的によって変わります。すべてのクラスを公平に見たいのか、データ数の多いクラスの影響も含めて全体性能を見たいのかを決めたうえで、マクロF1を使うことが大切です。
マクロ平均・マイクロ平均・重み付け平均の違い
F1値の平均方法には、マクロ平均のほかにマイクロ平均と重み付け平均があります。どれも分類モデルを評価するために使われますが、何を重視するかが異なります。
マクロ平均は、各クラスのF1値を同じ重みで平均します。クラスごとのデータ数に左右されにくいため、少数クラスも含めて均等に評価したい場合に向いています。
マイクロ平均は、全クラスの予測結果をまとめてから適合率と再現率を計算します。データ数の多いクラスの影響が大きくなるため、サンプル全体としての性能を見たい場合に使いやすい方法です。
重み付け平均は、各クラスのF1値に、そのクラスのデータ数などに応じた重みを付けて平均します。少数クラスを完全に同じ重みで扱うのではなく、データ分布をある程度反映したい場合に使われます。
| 平均方法 | 計算の考え方 | 特徴 | 向いている場面 |
|---|---|---|---|
| マクロ平均 | クラス別F1値を単純平均する | 各クラスを平等に見る | 少数クラスも重視したい場合 |
| マイクロ平均 | 全クラスの結果を合算してからF1値を出す | データ数の多いクラスの影響が強い | 全サンプルでの総合性能を見たい場合 |
| 重み付け平均 | クラスの件数などで重みを付けて平均する | データ分布を反映しやすい | クラス不均衡を考慮しつつ全体像も見たい場合 |
初心者は、まず「マクロ平均はクラスを平等に見る」「マイクロ平均はデータ全体を見る」「重み付け平均はクラスの件数を反映する」と整理すると理解しやすくなります。
マクロF1値が役立つ場面
マクロF1値は、クラスごとのデータ数に偏りがあり、少数クラスの分類性能も重要な場面で役立ちます。たとえば、医療診断では患者数が少ない病気の見逃しが問題になることがあります。問い合わせ分類では、件数の少ない重大トラブルのカテゴリを正しく拾えるかが重要になることがあります。
ニュース分類でも、政治や経済の記事が多く、科学や地域ニュースの記事が少ないデータでは、正解率だけでは少数カテゴリの弱さに気づきにくい場合があります。画像分類でも、よく写る物体とまれにしか写らない物体が混在していると、多数派クラスに強いモデルが高く評価されやすくなります。
このようなとき、マクロF1値を見ることで、モデルが各クラスをどれだけバランスよく扱えているかを確認できます。モデル選定や改善の場面では、マクロF1が低いクラスを調べることで、データ追加、ラベル見直し、特徴量改善、しきい値調整などの具体的な対策につなげやすくなります。
マクロF1値を見るときの注意点
マクロF1値は便利ですが、これだけでモデルの良し悪しを判断するのは危険です。各クラスを同じ重みで扱うため、業務上はそれほど重要でない少数クラスの変動が評価に強く出ることがあります。逆に、件数が多く影響範囲の大きいクラスの問題が、目的によっては軽く見えてしまうこともあります。
また、F1値は適合率と再現率をもとにした指標であり、真陰性を直接重視する指標ではありません。問題によっては、陰性を正しく陰性と判断できたか、誤検知のコストがどれくらいか、見逃しのコストがどれくらいかを別に考える必要があります。
特に実務では、マクロF1値に加えて、クラス別の適合率・再現率・F1値、混同行列、正解率、ROC-AUCやPR-AUCなどを組み合わせて確認します。分類ミスの種類を見なければ、どのクラスで何が起きているのかはわかりません。
マクロF1値が高くても、すべての用途で十分とは限りません。医療、金融、不正検知、品質検査のようにミスの重さがクラスごとに大きく違う場合は、評価指標を選ぶ前に「何を間違えると困るのか」を明確にすることが重要です。
より良いモデル評価につなげる考え方
マクロF1値を使う目的は、単に1つの数字を高くすることではありません。モデルがどのクラスに弱いのか、データの偏りがどの程度あるのか、目的に合った性能が出ているのかを確認し、改善につなげることが大切です。
もしマクロF1値が低い場合は、少数クラスのデータが不足していないか、ラベルの付け方に揺れがないか、似たクラス同士を混同していないかを確認します。必要に応じて、データの追加、データ拡張、クラス重みの調整、損失関数の見直し、しきい値の調整などを検討します。
一方で、マクロF1値だけを上げるために、実際の利用目的から外れた調整をするのは避けるべきです。たとえば、少数クラスの再現率を上げるために誤検知が大きく増えると、運用上の負担が増える可能性があります。評価指標は、モデルを使う場面のリスクやコストと合わせて選びます。
まとめ
マクロF1値は、多クラス分類で各クラスのF1値を同じ重みで平均する評価指標です。データ数の多いクラスだけに評価が引っ張られにくく、少数クラスも含めて分類性能を確認したいときに役立ちます。
理解のポイントは、F1値が適合率と再現率のバランスを表すこと、マクロ平均がクラスを平等に扱うこと、そしてマイクロ平均や重み付け平均とは評価の見え方が違うことです。正解率だけでは見えない弱点を把握するために、マクロF1値は有効な手がかりになります。
ただし、マクロF1値は万能ではありません。クラス別指標や混同行列と合わせて確認し、モデルを使う目的に応じて適切な評価指標を選ぶことが、より良いAIモデルの構築につながります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年5月16日 | 平均方法の違いと評価時の見落としやすい点を追記 |