分類問題とは?機械学習での意味・種類・評価指標を解説

AIの初心者
「分類問題」って何ですか?動物の画像でいうと、どういうことですか?

AI専門家
分類問題は、画像や文章などのデータを見て、あらかじめ決まった種類のどれに当てはまるかを予測する問題だよ。動物の画像なら、犬、猫、鳥といったカテゴリを選ぶイメージだね。
AIの初心者
つまり、たくさんの動物画像に「犬」「猫」「鳥」のようなラベルを付けて学習させる感じですか?
AI専門家
その通り。ラベル付きのデータから特徴を学ぶことで、新しい画像を見たときにも、どの種類に近いかを判断できるようになるんだ。
分類問題とは。
分類問題は、機械学習でデータを決まったカテゴリへ振り分ける問題です。動物の写真、メール、文章、医療画像などを対象に、「どの種類に属するか」を予測します。
分類問題とは
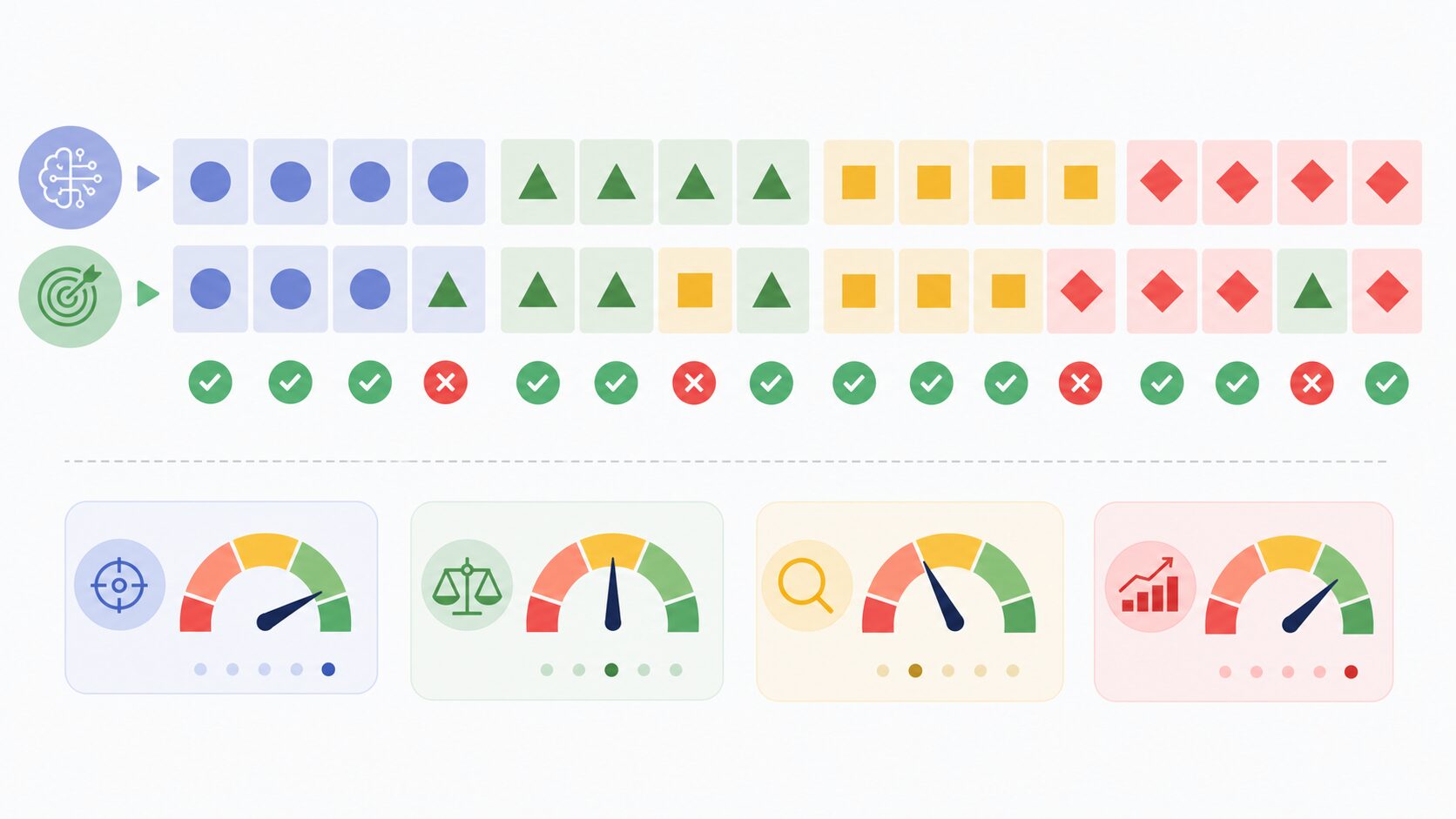
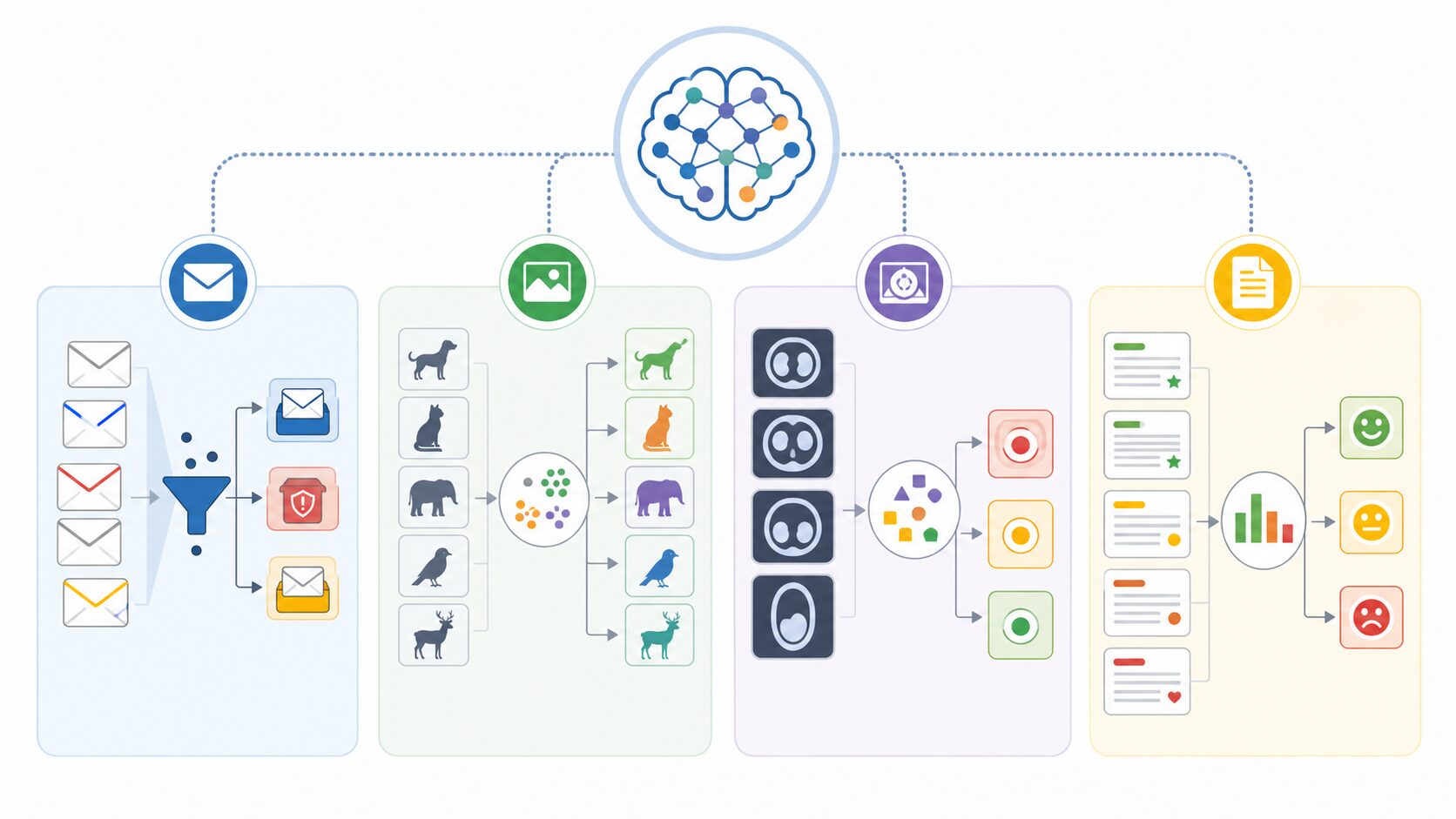
分類問題とは、入力されたデータがどのグループやカテゴリに属するかを予測する機械学習の問題です。画像を見て犬か猫かを判定する、メールを迷惑メールか通常メールかに分ける、文章をニュース・レビュー・問い合わせなどに分類する、といった処理が代表例です。
ここでいうカテゴリは、「クラス」や「ラベル」と呼ばれることもあります。たとえば動物画像の分類なら、犬、猫、鳥がクラスであり、各画像に付けられた正解名がラベルです。機械学習モデルは、過去のデータとラベルの対応関係を学び、新しいデータに対して最もありそうなラベルを予測します。
分類問題の大きな特徴は、予測したい値が連続的な数値ではなく、いくつかの選択肢の中のどれかである点です。身長や売上金額のように数値が連続して変化するものではなく、「犬」「猫」「鳥」、「合格」「不合格」、「危険」「安全」のように区切られた値を扱います。
| 項目 | 内容 |
|---|---|
| 分類問題 | データがどのカテゴリに属するかを予測する問題 |
| 入力データ | 画像、文章、数値データ、音声、センサー情報など |
| 出力 | 犬、猫、迷惑メール、正常、異常などのラベル |
| 主な用途 | 画像認識、自然言語処理、医療診断、異常検知、推薦など |
分類問題と回帰問題の違い
分類問題を理解するときは、回帰問題との違いを押さえると整理しやすくなります。分類問題はカテゴリを予測するのに対し、回帰問題は数値を予測します。たとえば、住宅の情報から「価格はいくらか」を予測するなら回帰問題であり、「高価格帯か中価格帯か低価格帯か」を予測するなら分類問題です。
気温を何度と予測する、来月の売上金額を予測する、商品の需要数を予測する、といったタスクは回帰問題です。一方、レビュー文が好意的か否定的かを判定する、検査画像が正常か異常かを判定する、問い合わせ内容を担当部署ごとに振り分ける、といったタスクは分類問題です。
どちらを選ぶかは、最終的に知りたい答えが「数値」なのか「種類」なのかで決まります。同じデータでも目的が変われば、分類問題として扱うことも、回帰問題として扱うこともあります。たとえば顧客の購買金額を予測したいなら回帰、購入する可能性が高いか低いかを判定したいなら分類です。
| 比較項目 | 分類問題 | 回帰問題 |
|---|---|---|
| 予測するもの | カテゴリ、ラベル、クラス | 連続的な数値 |
| 例 | 迷惑メールか通常メールか | 来月の売上はいくらか |
| 評価の観点 | 正しく分類できたか、見逃しが少ないか | 予測値と実測値の差が小さいか |
分類問題の主な種類
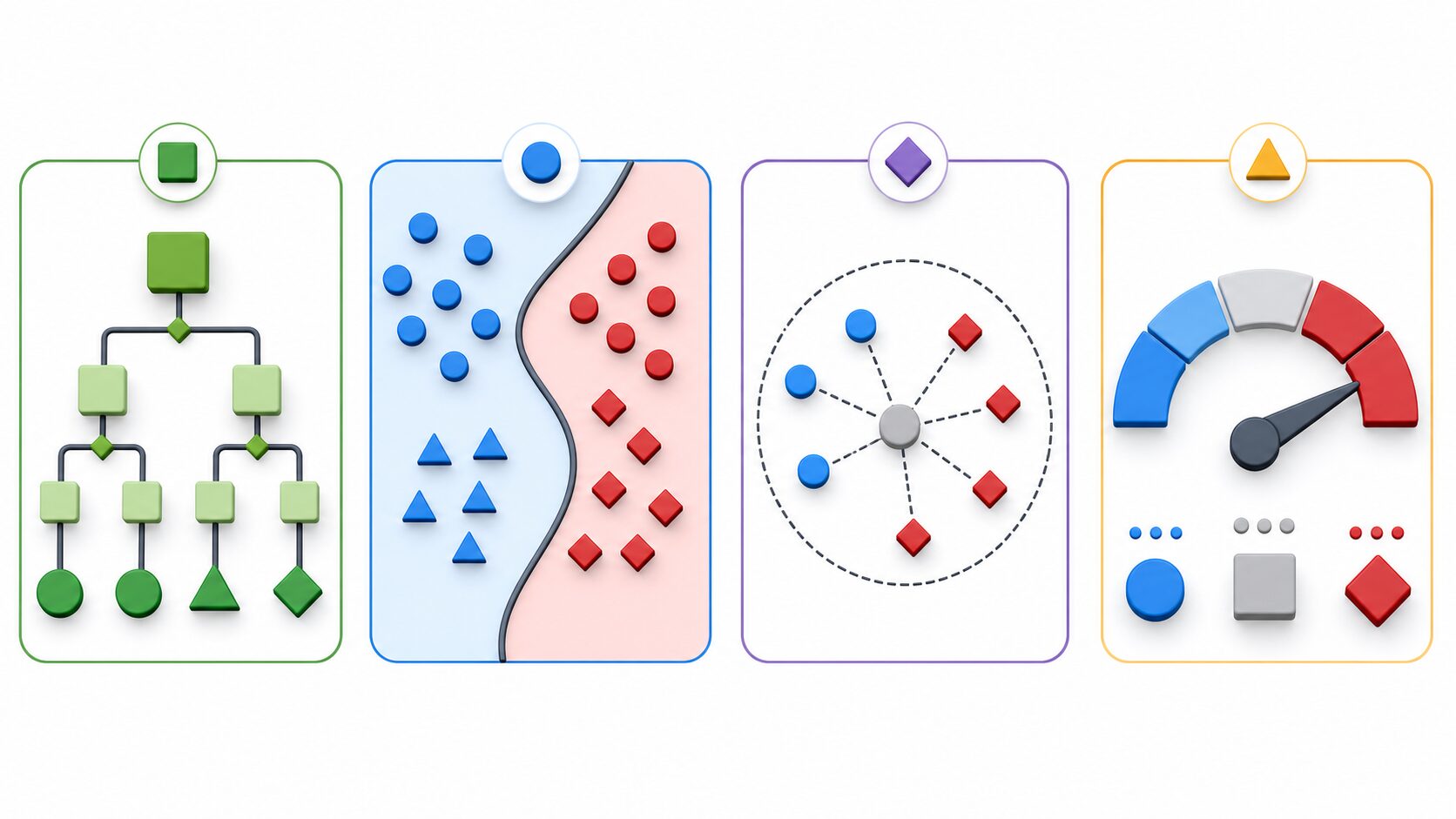
分類問題は、分けたいカテゴリの数や構造によっていくつかに分けられます。もっとも基本的なのは、二値分類と多クラス分類です。学習を始めたばかりの段階では、この二つを区別できるだけでも、多くの分類タスクを理解しやすくなります。
二値分類は、対象を二つのカテゴリのどちらかに分ける問題です。迷惑メールか通常メールか、病気の可能性があるかないか、不良品か良品か、といった「はい」「いいえ」に近い判断が該当します。実務では、片方の見逃しが大きな損失につながることもあるため、単に正答率を見るだけでは不十分な場合があります。
多クラス分類は、三つ以上のカテゴリから一つを選ぶ問題です。手書き数字を0から9までのどれかに分類する、ニュース記事を政治・経済・スポーツ・文化などに分ける、問い合わせを部署ごとに振り分ける、といった例があります。クラスが増えるほど、似たカテゴリ同士を区別するための特徴が重要になります。
さらに、複数のラベルが同時に付く多ラベル分類や、上位カテゴリと下位カテゴリを持つ階層分類もあります。たとえば一つの記事に「AI」と「教育」の両方のタグを付ける場合は多ラベル分類、生物を動物、哺乳類、犬のように段階的に分ける場合は階層分類です。
身近な分類問題の例

分類問題は、専門的な研究だけでなく、日常のサービスにも多く使われています。たとえばメールサービスの迷惑メール判定では、件名、本文、送信元、リンクの有無などをもとに、受信したメールを迷惑メールか通常メールかに分けます。不要なメールを自動で避けられるのは、分類問題が実用化されている分かりやすい例です。
画像認識も代表的な分類問題です。スマートフォンの写真整理、工場での不良品検出、医療画像の確認支援などでは、画像に含まれる特徴から対象物や状態を推定します。医療のような重要な分野では、AIの判定結果をそのまま結論にするのではなく、医師の確認や追加検査と組み合わせて使うことが前提になります。
自然言語処理では、文章の種類や感情を分類します。レビュー文が肯定的か否定的かを判断する感情分析、問い合わせ内容を担当部署へ振り分ける分類、ニュース記事のジャンル分類などが該当します。ECサイトの商品推薦でも、ユーザーの行動履歴や商品の特徴を分類し、好みに合う候補を表示する仕組みが使われます。
| 分野 | 分類の例 | 目的 |
|---|---|---|
| メール | 迷惑メールと通常メール | 不要な情報を減らし、重要な連絡を見つけやすくする |
| 画像認識 | 犬、猫、鳥、不良品、正常品など | 大量の画像を効率よく判定する |
| 医療 | 正常、要注意、異常の可能性など | 診断支援や早期発見の手がかりにする |
| 文章処理 | 肯定、否定、問い合わせ種別、記事ジャンル | 文章を整理し、対応や分析を効率化する |
分類問題で使われる代表的な手法
分類問題を解く方法は一つではありません。データの量、特徴の数、説明しやすさ、必要な精度、計算コストによって適した手法が変わります。ここでは、分類問題の学習でよく登場する代表的な手法を整理します。
決定木は、条件分岐をたどりながら分類する手法です。「この特徴が一定以上なら右、そうでなければ左」のように枝分かれしていくため、判断の流れを人間が理解しやすいという利点があります。業務で説明責任が求められる場面では、結果だけでなく理由を追いやすいことが強みになります。
サポートベクターマシンは、データを分ける境界を見つける手法です。点の集まりをうまく分離する線や面を考え、カテゴリ間の余裕が大きくなるように境界を引きます。特徴量の作り方が適切であれば、比較的少ないデータでも高い性能を出せることがあります。
ロジスティック回帰は、分類したいカテゴリに属する確率を推定する手法です。名前に「回帰」とありますが、二値分類でよく使われます。たとえば「病気である確率が70%」「購入する確率が30%」のように、結果を確率として扱いやすい点が特徴です。
k近傍法は、分類したいデータの近くにある学習データを見て、多数決でラベルを決める手法です。考え方は直感的で分かりやすいものの、データ量が大きい場合は計算が重くなることがあります。また、どの特徴を使って「近い」と判断するかが結果に大きく影響します。
| 手法 | 考え方 | 向いている場面 |
|---|---|---|
| 決定木 | 条件分岐をたどって分類する | 判断理由を説明しやすくしたい場合 |
| サポートベクターマシン | カテゴリを分ける境界を見つける | 特徴量が整理され、境界で分けやすい場合 |
| ロジスティック回帰 | カテゴリに属する確率を推定する | 二値分類で確率も確認したい場合 |
| k近傍法 | 近いデータの多数決で分類する | 仕組みを直感的に理解したい場合 |
分類問題の評価指標
分類モデルを作ったら、どれくらいうまく分類できているかを評価する必要があります。よく使われる指標は、正答率、適合率、再現率、F値です。どれも分類の正しさを測る指標ですが、見ている観点が異なります。
正答率は、全体のうち正しく分類できた割合です。100件中80件を正しく分類できたなら、正答率は80%です。直感的で分かりやすい一方、データに偏りがある場合は注意が必要です。たとえば99%が正常なデータなら、すべてを正常と予測しても正答率は高く見えてしまいます。
適合率は、あるカテゴリだと予測したもののうち、実際にそのカテゴリだった割合です。たとえば「異常」と判定したものの中で本当に異常だった割合を見ます。誤って陽性と判断する偽陽性を減らしたい場面で重視されます。
再現率は、実際にそのカテゴリであるもののうち、どれだけ見つけられたかを示します。病気の見逃しや不正取引の見逃しを避けたい場合は、再現率が重要になります。適合率を上げようとすると再現率が下がることもあり、両者のバランスを見るためにF値が使われます。
分類問題では、目的に合わせて評価指標を選ぶことが重要です。迷惑メール判定なら通常メールを誤って迷惑メールにしないことも大切ですし、医療診断支援なら危険な見逃しを減らすことが大切です。モデルの良し悪しは、単純な正答率だけで決めないようにしましょう。
| 指標 | 意味 | 重視する場面 |
|---|---|---|
| 正答率 | 全体のうち正しく分類できた割合 | データの偏りが小さく、全体性能を見たい場合 |
| 適合率 | そのカテゴリだと予測したものが本当に正しかった割合 | 誤検出を減らしたい場合 |
| 再現率 | 実際にそのカテゴリのものをどれだけ見つけられたか | 見逃しを減らしたい場合 |
| F値 | 適合率と再現率のバランスを見る指標 | 誤検出と見逃しの両方を考えたい場合 |
分類問題を学ぶときの注意点
分類問題は分かりやすいテーマですが、実際にモデルを作るときにはいくつか注意点があります。まず、学習データに偏りがあると、モデルの判断にも偏りが出ます。犬の画像ばかりで猫の画像が少ないデータを使えば、猫の判定が苦手になる可能性があります。
次に、ラベルの品質も重要です。正解ラベルが間違っていたり、人によって判断基準が違ったりすると、モデルは不安定な対応関係を学んでしまいます。分類問題では、モデルの手法だけでなく、データの集め方、ラベル付けの基準、評価用データの分け方が性能を左右します。
また、分類結果はあくまで学習データから推定した結果です。確率が高いからといって、常に正しいとは限りません。特に医療、金融、採用、セキュリティのように判断の影響が大きい場面では、人間の確認、説明可能性、運用後の監視が欠かせません。
深層学習と説明可能AIによる広がり
近年は深層学習の発展により、分類問題の精度と活用範囲が大きく広がっています。画像認識では畳み込みニューラルネットワーク、文章処理ではTransformerなどのモデルが使われ、従来より複雑な特徴を自動的に捉えられるようになりました。
一方で、高精度なモデルほど判断の理由が分かりにくくなることがあります。分類結果を業務で使う場合、「なぜその分類になったのか」を説明できないと、利用者が結果を信頼しにくくなります。そのため、説明可能AIの研究も重要になっています。
説明可能AIは、モデルが注目した特徴や判断に影響した要素を人間が理解しやすい形で示す考え方です。医療画像診断支援、金融の審査、工場の品質管理などでは、分類精度だけでなく、説明しやすさや運用上の安全性も合わせて考える必要があります。
まとめ
分類問題は、データを見て決まったカテゴリのどれに属するかを予測する、機械学習の基本的な問題です。動物画像の判定、迷惑メール判定、文章分類、医療診断支援など、身近なサービスから専門的な業務まで幅広く使われています。
学習を進めるときは、分類問題と回帰問題の違い、二値分類と多クラス分類の違い、代表的な手法、評価指標の使い分けを順番に押さえると理解しやすくなります。特に実務では、正答率だけでなく、適合率、再現率、F値を目的に合わせて確認することが大切です。
分類問題は「種類を当てる」だけに見えますが、データの偏り、ラベルの品質、説明可能性まで含めて考えることで、より信頼できるAI活用につながります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月31日 | 回帰との違い、評価指標、運用時の注意点を補って再編集 |