不均衡データとは?問題点と対策を初心者向けに解説

AIの初心者
「不均衡データ」ってなんですか?AIの勉強をしているとよく聞くのですが、どんな状態を指すのかまだよく分かりません。

AI専門家
不均衡データとは、データの中で特定の種類だけが他の種類に比べて極端に少ない状態のことです。例えば、クレジットカードの不正利用は、通常の利用に比べると件数がかなり少ないですよね。これが代表的な例です。
AIの初心者
つまり、データの数に偏りがあるということですね。でも、数が少ない種類があると、なぜAIの学習で問題になるのでしょうか?
AI専門家
偏りが大きいと、AIは数の多いデータの特徴ばかりを学習し、数の少ない重要なケースを見逃しやすくなります。不正利用検知でいえば、不正を正常な取引だと判断してしまう危険があるため、専用の対策が必要になります。
不均衡データとは。
機械学習では、データの数が均等にそろっているとは限りません。特に少数派のデータを正しく見つけたい場面では、データの偏りがモデルの性能に大きく影響します。
不均衡データとは
不均衡データとは、分類したいデータの中で、ある種類のデータが他の種類に比べて極端に少ない状態を指します。機械学習の分類問題では、それぞれの分類先を「クラス」と呼ぶため、「クラスの分布が偏っているデータ」と説明されることもあります。
分かりやすい例が、クレジットカードの不正利用検知です。日常的なカード利用のほとんどは正規の取引であり、不正利用はごく一部に限られます。このデータをそのまま学習に使うと、モデルは「ほとんどの取引は正常である」という傾向を強く学習しやすくなります。
同じ構造は、医療診断における希少疾患の判別、製造ラインでの不良品検出、ネットワークの不正アクセス検知などにも見られます。どの例でも、件数が少ない側のデータは珍しいだけでなく、実務上の重要度が高いことが多い点が特徴です。
| 分野 | 多数派の例 | 少数派の例 | 少数派を見逃した場合 |
|---|---|---|---|
| 決済 | 通常のカード利用 | 不正利用 | 損害や調査遅れにつながる |
| 医療 | 健康な人、一般的な症状 | 希少疾患の患者 | 治療開始が遅れる可能性がある |
| 製造 | 良品 | 不良品 | 品質問題や回収リスクが高まる |
不均衡データが問題になる理由
不均衡データが問題になるのは、モデルが多数派のパターンを学習するだけで、見かけ上は高い性能を出せてしまうからです。例えば、病気の人が1%、病気でない人が99%のデータで、すべてを「病気ではない」と予測するモデルを考えます。このモデルの正解率は99%になりますが、病気の人を一人も見つけられていません。
つまり、不均衡データでは正解率が高いことと、目的を達成できていることが一致しない場合があります。多数派を当てるだけで評価値が良く見えるため、少数派の検出性能を別の視点から確認する必要があります。
クレジットカード不正検知では、不正取引を正常と判断する見逃しが大きな問題になります。医療診断では、希少疾患の兆候を見逃すと治療の開始が遅れるかもしれません。製造業では、不良品を良品として通してしまうと、顧客への影響や追加対応のコストが発生します。
このように、不均衡データ問題では「全体としてどれだけ当たったか」だけでなく、「少数派をどれだけ見つけられたか」「誤って見逃したときの損失はどの程度か」を考えることが重要です。
データレベルでの対策

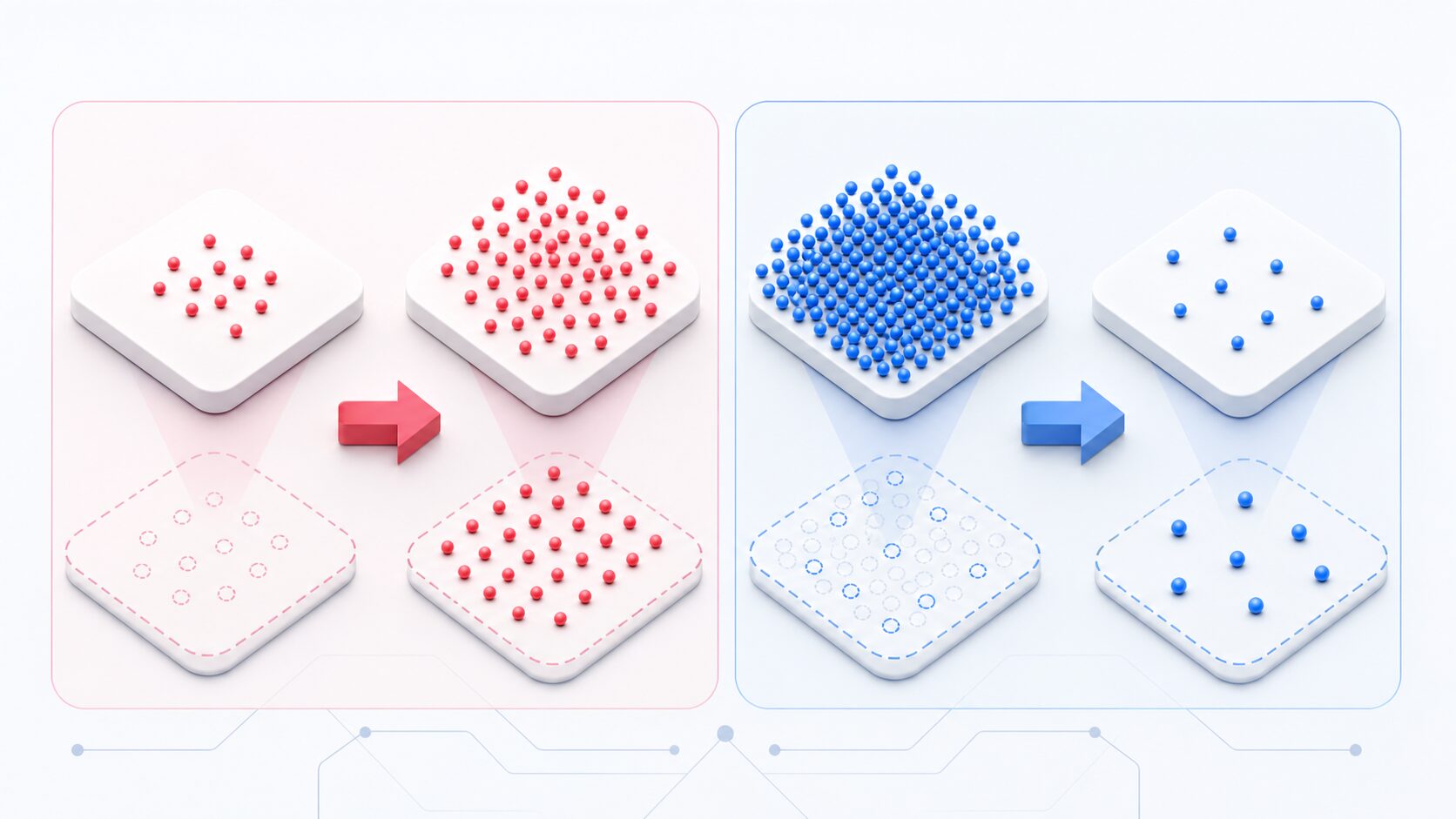
不均衡データへの代表的な対策の一つが、学習に使うデータの比率を調整する方法です。少数派を増やす方法をオーバーサンプリング、多数派を減らす方法をアンダーサンプリングと呼びます。
オーバーサンプリングでは、少数派のデータを複製したり、既存データをもとに似たデータを作ったりして、少数派の存在感を高めます。これにより、モデルが少数派の特徴を学習しやすくなります。ただし、単純に同じデータを何度も増やすだけだと、訓練データに過度に合わせ込む過学習が起きる可能性があります。
アンダーサンプリングでは、多数派のデータを間引いて、少数派とのバランスを取ります。データ量が減るため計算量を抑えやすい一方で、多数派の中に含まれていた重要なパターンまで削ってしまう危険があります。特に多数派のデータにも多様な傾向がある場合は、どのデータを残すかが性能に影響します。
| 手法 | 考え方 | 利点 | 注意点 |
|---|---|---|---|
| オーバーサンプリング | 少数派のデータを増やす | 少数派の特徴を学習させやすい | 単純な複製では過学習しやすい |
| アンダーサンプリング | 多数派のデータを減らす | 計算量を抑えやすい | 重要な多数派データを失う可能性がある |
どちらが適しているかは、データ量、少数派の件数、モデルの種類、見逃しと誤検知のどちらをより避けたいかによって変わります。最初から一つに決め打ちするのではなく、元データの分布を確認し、検証データで比較することが大切です。
アルゴリズムレベルでの対策

データそのものを増減させるのではなく、学習方法を工夫して少数派を重視する対策もあります。代表例が費用重視学習やクラス重み付けです。これは、少数派を誤分類したときの損失を大きく設定し、モデルが少数派の間違いを軽く扱わないようにする考え方です。
例えば、不正利用検知では「正常な取引を不正と疑う」誤検知も問題ですが、「不正取引を正常と判断する」見逃しの方が大きな損害につながる場合があります。このようなとき、少数派である不正取引に大きな重みを与えることで、モデルは不正の特徴により注意を向けるようになります。
この方法の利点は、データ量を直接変えなくても不均衡データに対応できることです。決定木、ロジスティック回帰、サポートベクターマシン、ニューラルネットワークなど、多くの手法でクラス重みの考え方を取り入れられます。
一方で、重みを大きくしすぎると少数派を過剰に疑うモデルになり、誤検知が増えることがあります。少数派を見逃したくないのか、誤検知を抑えたいのか、業務上の目的に合わせて重みを調整する必要があります。
評価指標レベルでの対策
不均衡データでは、モデルを評価する指標の選び方も重要です。正解率だけを見ると、多数派を当てる能力に引っ張られて、少数派の検出性能が見えにくくなります。そのため、精度、再現率、F値などを組み合わせて確認します。
精度は、モデルが「少数派である」と予測したもののうち、実際に少数派だった割合です。誤検知をどれだけ抑えられているかを確認しやすい指標です。
再現率は、実際に少数派だったデータのうち、モデルが正しく少数派として見つけられた割合です。見逃しをどれだけ減らせているかを確認するときに重要です。
F値は、精度と再現率のバランスを見るための指標です。代表的なF1値は次の式で表されます。
\(F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall}\)ここで、\(Precision\)は精度、\(Recall\)は再現率を表します。精度だけが高くても、再現率だけが高くても、F1値は高くなりにくいため、両方をほどよく満たしているかを確認できます。
| 指標 | 見るもの | 重視したい場面 |
|---|---|---|
| 正解率 | 全体の予測がどれだけ当たったか | クラスの偏りが小さい場合 |
| 精度 | 少数派と予測したものの信頼性 | 誤検知を減らしたい場合 |
| 再現率 | 実際の少数派をどれだけ見つけたか | 見逃しを減らしたい場合 |
| F値 | 精度と再現率のバランス | 両方を総合的に比較したい場合 |
不均衡データ対策を選ぶときの注意点
不均衡データへの対策は、一つの方法だけで必ず解決するものではありません。データを増やす、減らす、重みを付ける、評価指標を変えるといった方法を、問題の目的に合わせて組み合わせることが多くあります。
まず確認したいのは、少数派を見逃すことと、多数派を誤って少数派と判断することのどちらがより大きな問題になるかです。不正検知や病気のスクリーニングでは見逃しを減らすことが重視されやすく、不要な確認作業のコストが大きい業務では誤検知を抑えることも重要になります。
次に、検証方法にも注意が必要です。オーバーサンプリングで増やしたデータが、検証データやテストデータに混ざると、実際より性能が高く見える可能性があります。対策は訓練データ側に適用し、未知のデータでどれだけ通用するかを検証することが基本です。
また、不均衡データは単に「比率が偏っているから悪い」という話ではありません。少数派の件数が少なすぎる場合は、追加データの収集、特徴量の見直し、専門家によるラベル確認など、モデル以外の工程が重要になることもあります。
まとめ
不均衡データとは、分類対象のうち一部のクラスだけが極端に少ないデータのことです。機械学習では、多数派のデータが多いほどモデルがその傾向に引っ張られ、少数派の重要なケースを見逃しやすくなります。
対策には、少数派を増やすオーバーサンプリング、多数派を減らすアンダーサンプリング、少数派の誤分類を重く扱う費用重視学習やクラス重み付けがあります。さらに、正解率だけでなく、精度、再現率、F値などを使って少数派の検出性能を確認することが欠かせません。
重要なのは、データの偏りそのものだけでなく、何を見逃すと困るのか、どの誤りを許容できないのかを明確にすることです。目的に合った対策と評価指標を選ぶことで、不均衡データを含む現実的なデータでも、より信頼できる機械学習モデルに近づけられます。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年6月20日 | 評価指標と対策の使い分けを補い、少数派検出の観点を追記 |