k分割交差検証とは?モデルの精度評価をわかりやすく解説

AIの初心者
k分割交差検証という言葉を見ました。データを何回も分けて評価する、と聞いたのですが、なぜそんなことをするのでしょうか?

AI専門家
一度だけ訓練用と検証用に分けると、たまたまの分け方で評価がぶれやすいからだよ。k分割交差検証では、データをk個に分け、検証に使う場所を入れ替えながらk回評価するんだ。
AIの初心者
つまり、全データを一度は検証用に使うことで、モデルの実力を安定して見られるということですか?
AI専門家
その通り。特にデータ数が限られているときや、モデル同士を公平に比較したいときに役立つ。この記事では、手順、kの決め方、他の検証方法との違い、実務での注意点を整理していこう。
k分割交差検証とは
k分割交差検証とは、データをk個のグループに分け、1つを検証用、残りを訓練用としてモデルを学習・評価し、この作業をk回繰り返す検証方法です。各グループが一度ずつ検証用データになるため、限られたデータを有効に使いながら、モデルの汎化性能をより安定して見積もれます。
k分割交差検証の基本的な仕組み
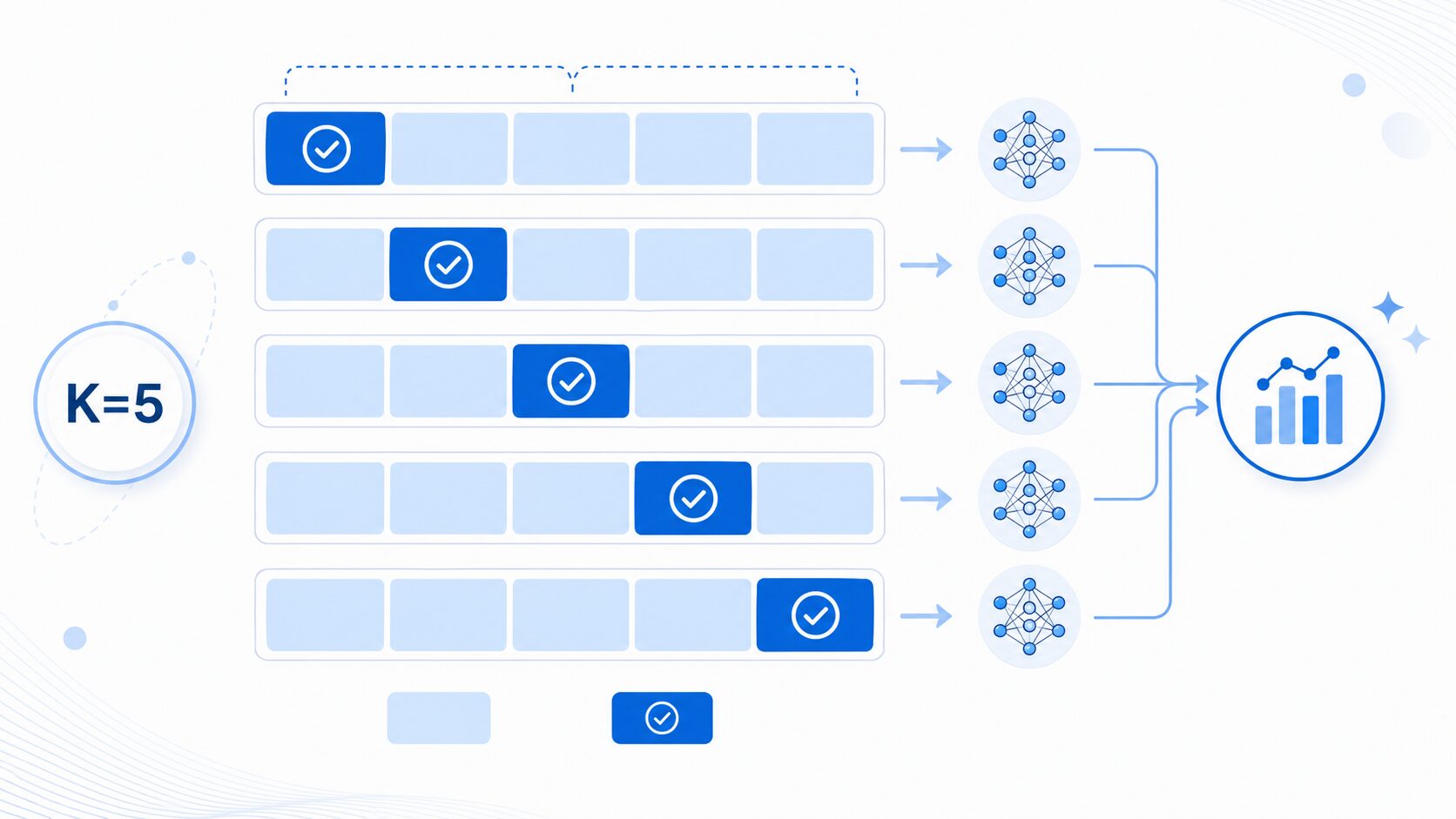
機械学習では、モデルを作ることだけでなく、そのモデルが未知のデータに対してどれくらい正しく予測できるかを確かめることが重要です。学習に使ったデータだけで高い精度が出ても、新しいデータで性能が落ちるなら、実用上は良いモデルとは言えません。
k分割交差検証では、まず手元のデータをほぼ同じ大きさのk個のグループに分けます。この1つ1つのグループを「fold」と呼びます。たとえば100件のデータでk=5なら、20件ずつの5グループを作ります。
次に、1つのfoldを検証用データにし、残りのk-1個のfoldを訓練用データにしてモデルを学習します。この評価を、検証用にするfoldを入れ替えながらk回繰り返します。最後に、k回分の評価指標を平均して、モデル全体の性能として見ます。
この方法のポイントは、すべてのデータが一度は検証用データとして使われることです。一度だけ分割する方法よりも、特定の分け方に依存しにくく、評価結果のばらつきを抑えやすくなります。
| 手順 | 内容 |
|---|---|
| 1 | データをk個のfoldに分ける。 |
| 2 | 1つのfoldを検証用、残りを訓練用にする。 |
| 3 | モデルを学習し、検証用foldで性能を測る。 |
| 4 | 検証用foldを入れ替えて、同じ作業をk回繰り返す。 |
| 5 | k回のスコアを平均し、必要に応じてばらつきも確認する。 |
なぜ一度だけの分割では不十分なのか
データを訓練用と検証用に一度だけ分ける方法は、ホールドアウト検証と呼ばれます。手軽で計算も速いため、最初の確認には便利です。しかし、データ数が少ない場合やデータに偏りがある場合、どのデータが検証側に入るかによって評価結果が大きく変わることがあります。
たとえば、病気の診断モデルを評価するとき、検証用データに軽症例ばかりが入ればスコアが高く見えるかもしれません。逆に、難しい症例ばかりが入れば、モデルが実際より悪く見える可能性があります。このような偶然の影響を減らすために、複数の分け方で評価する交差検証が使われます。
また、学習済みモデルを学習データそのもので評価するのは避けるべきです。モデルが学習データの細部やノイズまで覚えてしまうと、学習データ上では高精度でも、未知のデータでは精度が落ちます。これが過学習です。
k分割交差検証は、過学習を直接なくす手法ではなく、過学習していないかをより信頼して確認するための評価手法です。この違いを押さえておくと、モデル改善の議論がしやすくなります。
ホールドアウト検証・リーブワンアウトとの違い
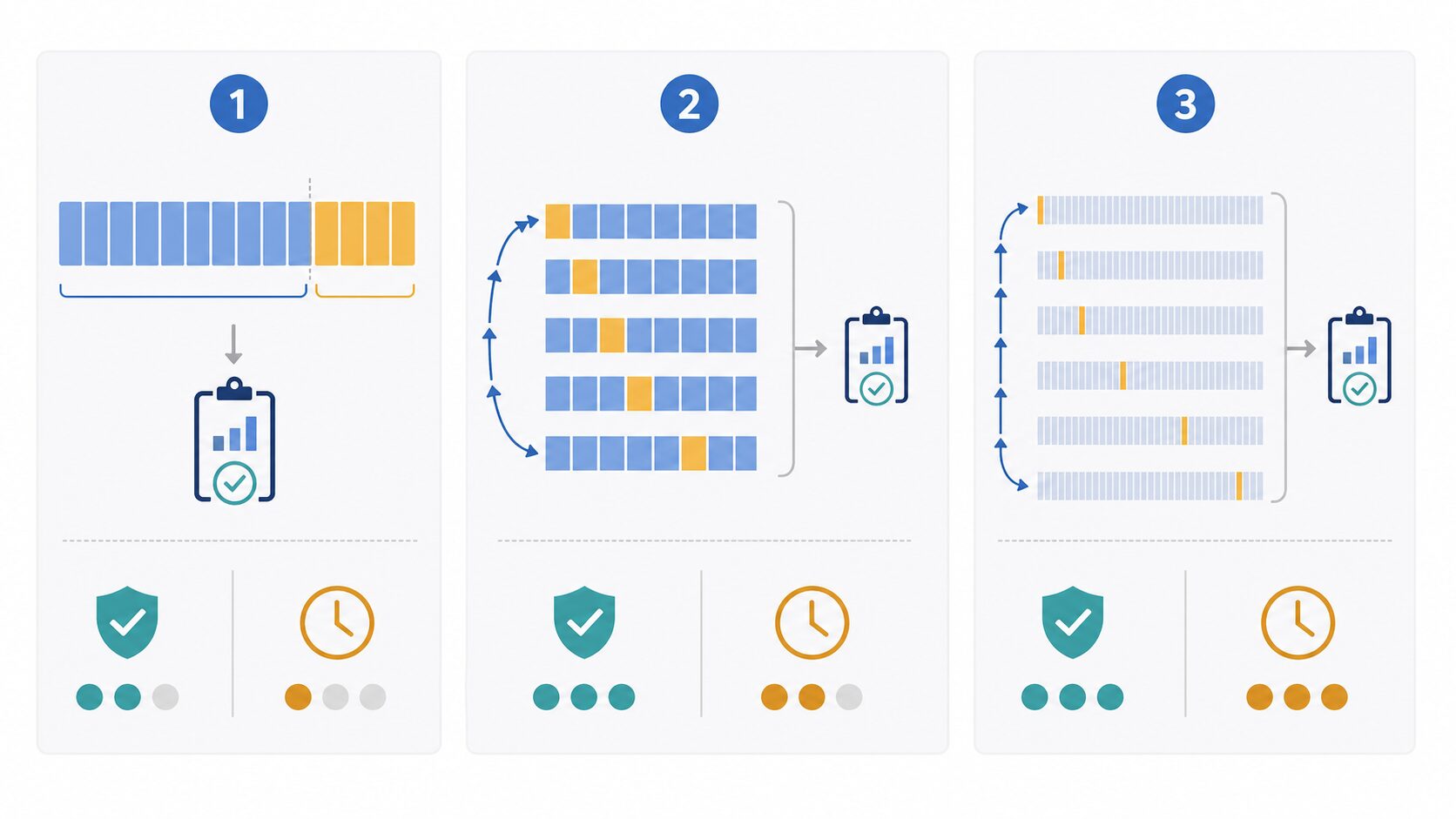
モデルの検証方法には、k分割交差検証以外にもいくつかの選択肢があります。代表的なのは、ホールドアウト検証、k分割交差検証、リーブワンアウト交差検証です。
ホールドアウト検証は、データを一度だけ訓練用と検証用に分けます。処理が速く、実装も簡単ですが、分け方による偶然の影響を受けやすいのが弱点です。データ数が十分に多く、分布も安定している場合には実用的です。
k分割交差検証は、分割と評価をk回繰り返します。計算量は増えますが、ホールドアウト検証よりも安定した評価を得やすくなります。実務ではk=5またはk=10がよく使われます。
リーブワンアウト交差検証は、データ数をnとしたときにk=nとする特殊な方法です。1件だけを検証用にし、残りすべてを訓練用にする評価をn回繰り返します。データを最大限に使えますが、計算回数が多く、データ数が増えると現実的でないことがあります。
| 検証方法 | 特徴 | 向いている場面 | 注意点 |
|---|---|---|---|
| ホールドアウト検証 | 一度だけ訓練用と検証用に分ける。 | データが多く、まず素早く確認したい場合。 | 分け方によってスコアがぶれやすい。 |
| k分割交差検証 | k個のfoldを順番に検証用にして平均する。 | モデル比較やハイパーパラメータ調整。 | k回学習するため計算時間が増える。 |
| リーブワンアウト交差検証 | 1件ずつ検証用にして、データ数分だけ繰り返す。 | データ数が非常に少ない場合。 | 計算コストが大きく、ばらつきの解釈にも注意が必要。 |
kの値はどう決めるか
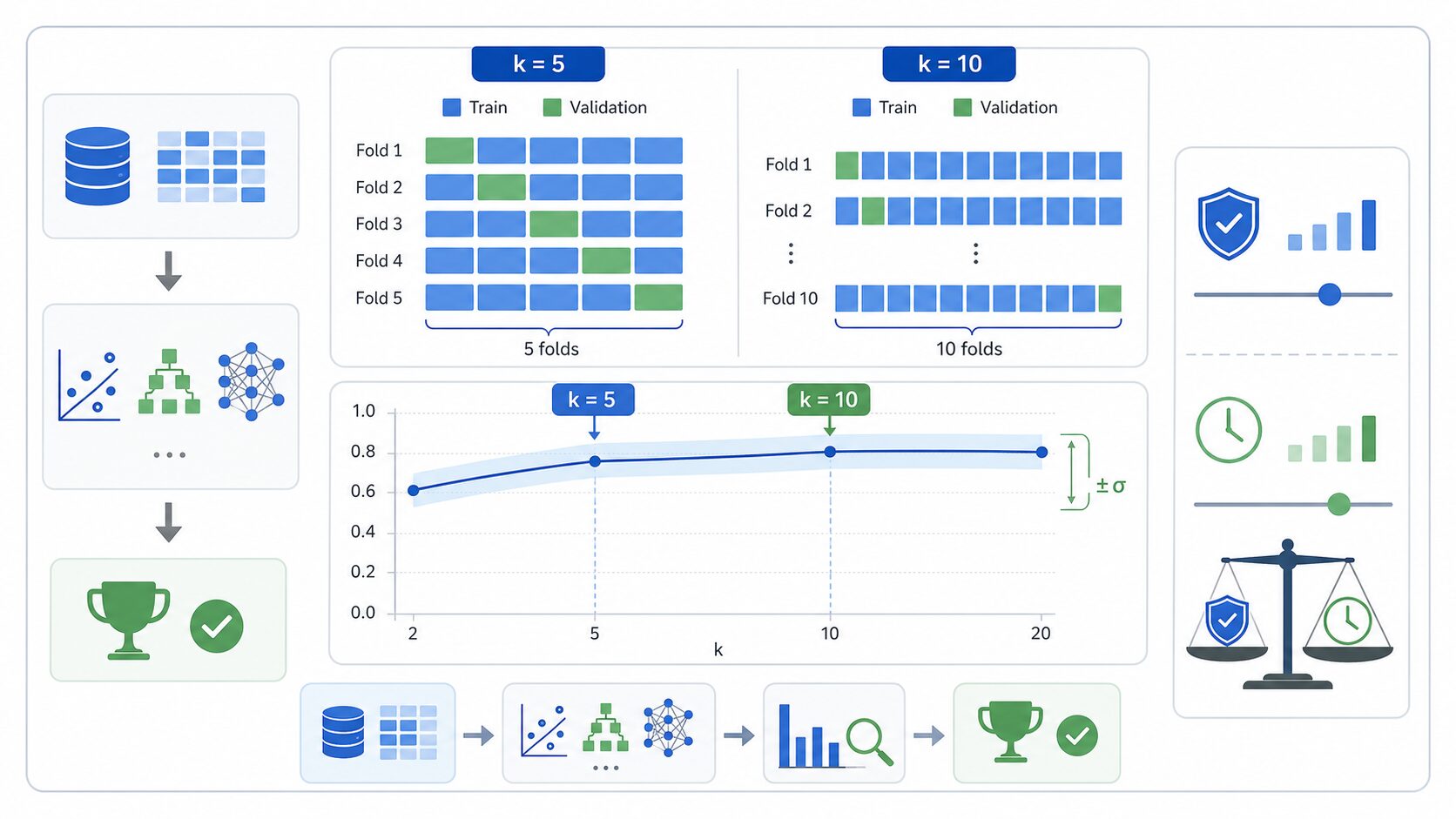
kの値は、評価の安定性と計算時間のバランスで決めます。一般的にはk=5またはk=10がよく使われます。多くの場面で、評価の安定性と計算量のバランスが取りやすいからです。
kが小さい場合、たとえばk=2やk=3では、1回あたりの検証データが大きくなり、訓練データが少なくなります。計算は速くなりますが、学習に使えるデータが減り、評価のばらつきも大きくなりやすいです。
kが大きい場合、1回あたりの訓練データは多くなりますが、学習と評価の回数も増えます。k=10なら10回、リーブワンアウトならデータ数と同じ回数だけ学習が必要です。モデルが重い場合やデータが大きい場合は、計算コストが無視できません。
実務では、まずk=5で試し、評価スコアの平均と標準偏差を確認するのが扱いやすい進め方です。データ数が少なく、スコアが不安定ならk=10も検討します。逆に、学習に時間がかかるモデルではkを小さめにし、別の検証セットや再分割で確認するほうが現実的なこともあります。
| kの値 | 特徴 | 使いどころ |
|---|---|---|
| k=3 | 計算は軽いが、評価のばらつきはやや大きくなりやすい。 | 重いモデルを素早く比較したい場合。 |
| k=5 | 計算量と安定性のバランスがよい。 | 最初に試す標準的な選択肢。 |
| k=10 | より細かく検証できるが、計算は増える。 | データが少なめ、または評価をより安定させたい場合。 |
| k=データ数 | リーブワンアウト交差検証になる。 | 小規模データで、計算時間を許容できる場合。 |
k分割交差検証のメリットとデメリット
k分割交差検証の大きなメリットは、限られたデータを効率よく使えることです。データを一度だけ検証用に取り分けると、その分だけ学習に使えるデータが減ります。k分割交差検証では、各データが訓練にも検証にも使われるため、データ数が少ない場面で特に有効です。
もう一つのメリットは、評価結果を平均だけでなく、ばらつきとしても見られることです。たとえば5回の評価スコアがほぼ同じなら、モデルの性能は比較的安定していると考えられます。一方で、foldごとのスコア差が大きい場合は、データの偏り、特徴量の不足、モデルの不安定さを疑うきっかけになります。
デメリットは、計算時間が増えることです。k=5なら基本的に5回、k=10なら10回モデルを学習します。深層学習のように1回の学習が重いモデルでは、交差検証をそのまま行うと時間やコストが大きくなります。
また、交差検証を使えば必ず正しい評価になるわけではありません。時系列データのように順序が重要なデータをランダムに分けると、未来の情報を使って過去を予測するような不自然な評価になることがあります。分類問題でクラスの偏りが大きい場合は、各foldのクラス比率を保つ層化k分割を使うことも重要です。
| 観点 | メリット | 注意点 |
|---|---|---|
| データ活用 | 全データを訓練と検証の両方に活用できる。 | 前処理を全データに先にかけると情報漏えいが起きる。 |
| 評価の安定性 | 一度だけの分割より、偶然の影響を抑えやすい。 | fold間のスコア差が大きい場合は原因確認が必要。 |
| 計算量 | モデル比較に使いやすい。 | k回学習するため、重いモデルでは時間がかかる。 |
実務で使うときの注意点
k分割交差検証を実務で使うときは、まずデータ漏えいに注意します。たとえば、標準化、欠損値補完、特徴量選択などを全データに対して先に行ってからfoldに分けると、検証用データの情報が訓練工程に混ざる可能性があります。前処理は、各foldの訓練データだけで学習し、検証データへ適用する流れにする必要があります。
分類問題で正例と負例の比率が偏っている場合は、単純にランダム分割すると、あるfoldに正例がほとんど入らないことがあります。この場合は、各foldでクラス比率をなるべく保つ層化k分割を使います。特に不正検知、医療診断、退会予測のような不均衡データでは重要です。
時系列データでは、通常のランダムなk分割は適さないことがあります。売上予測や株価予測のように時間の順序が意味を持つ場合、過去データで学習し、未来データで検証する形にしなければなりません。この場合は、時系列分割やウォークフォワード検証を検討します。
ハイパーパラメータ調整に使う場合は、検証結果を見てモデルを選んだあと、最終的な性能確認用のテストデータを別に残しておくと安心です。交差検証のスコアに合わせて何度も調整すると、その検証手順に対して過度に最適化されることがあるからです。
まとめ
k分割交差検証は、データをk個に分け、検証用データを入れ替えながらk回評価する方法です。一度だけの分割よりも評価のぶれを抑えやすく、限られたデータを有効に使えるため、モデル評価やモデル比較で広く使われます。
一般的にはk=5またはk=10が扱いやすい選択肢です。ただし、最適なkはデータ数、モデルの学習時間、評価の目的によって変わります。平均スコアだけでなくfoldごとのばらつきも確認し、モデルが安定しているかを見ることが大切です。
一方で、交差検証は万能ではありません。前処理による情報漏えい、クラス不均衡、時系列データの扱いを誤ると、現実よりも良く見える評価になることがあります。k分割交差検証は、正しく設計して使うことで、モデルの汎化性能をより信頼して判断するための強力な手法になります。
| 項目 | 要点 |
|---|---|
| 目的 | 未知のデータに対するモデル性能を安定して見積もる。 |
| 基本手順 | データをk個に分け、1つを検証用、残りを訓練用にしてk回評価する。 |
| よく使うk | まずはk=5またはk=10を検討する。 |
| 注意点 | 前処理の情報漏えい、クラス不均衡、時系列データの順序に注意する。 |
更新履歴
| 日付 | 内容 |
|---|---|
| 2026年4月26日 | k分割交差検証の手順、ホールドアウト検証やリーブワンアウトとの違い、kの値の決め方、実務上の注意点を整理し、図解画像を3点追加しました。 |