機械学習における繰り返し学習とは?イテレーションの意味と重要性を解説

AIの初心者
「イテレーション」という言葉をよく見かけます。機械学習では何を繰り返しているのですか?

AI専門家
イテレーションは、簡単にいうと「繰り返し」のことです。機械学習では、予測して、間違いを確認して、重みを少し直す流れを何度も行います。
AIの初心者
ただ繰り返すだけではなく、毎回モデルを少し改善しているのですね。
AI専門家
その通りです。回数が少なすぎると学習不足になり、多すぎると過学習になることもあるので、適切な回数を見極めることが大切です。
イテレーションとは。
人工知能に関わる言葉である「繰り返し」について説明します。機械学習では、モデルが予測、誤差の確認、重みの更新を行う一連の処理を繰り返すことを指します。
機械学習における繰り返し学習の重要性とは?
機械学習では、データから規則性やパターンを見つけ、未知のデータに対して予測できるモデルを作ります。ただし、最初から正確な判断ができるわけではありません。多くのモデルは、最初に適当な重みを持った状態から始まり、予測と修正を繰り返しながら少しずつ性能を高めていきます。
この学習の繰り返しが「繰り返し学習」であり、英語ではイテレーションと呼ばれます。機械学習におけるイテレーションは、単に同じ作業を何度も行うことではなく、予測結果と正解のずれをもとに、モデルの重みを更新する1回分の学習ステップとして理解すると分かりやすくなります。
たとえば犬と猫を見分けるモデルを作る場合、最初は耳の形、毛色、顔の輪郭などをうまく使えず、間違った予測をすることがあります。そこでモデルは、正解との違いを確認し、次はより正しく分類できるように内部の重みを調整します。この「予測する、間違いを測る、重みを直す」という流れを何度も回すことで、モデルはデータの特徴を捉えられるようになります。
つまり、繰り返し学習は機械学習モデルを成長させる中心的な仕組みです。一度の計算で完璧なルールを作るのではなく、試行錯誤を通じて誤差を減らしていくため、学習回数、学習率、評価指標などの調整が重要になります。
繰り返し学習とイテレーションの基本
イテレーションは「反復」や「繰り返し」を意味する言葉です。プログラミングではループ処理を指すこともありますが、機械学習では主に、データを使ってモデルのパラメータを更新する処理の単位として使われます。
モデルのパラメータとは、予測の結果を左右する調整つまみのようなものです。ニューラルネットワークでは重みやバイアスがこれにあたります。学習では、モデルが出した予測と正解を比べ、ずれが小さくなる方向へパラメータを少しずつ動かします。
1回のイテレーションでは、入力データの一部または全部を使って予測を行い、損失を計算し、その損失を減らすように重みを更新します。この更新が積み重なることで、モデルは最初よりも安定した予測を出せるようになります。
初心者が注意したいのは、イテレーションの回数がそのまま「賢さ」を表すわけではない点です。学習回数が増えれば一定の範囲では改善が期待できますが、データの質、モデルの複雑さ、学習率、評価方法が合っていなければ、何度繰り返しても期待した性能には届きません。
繰り返し学習がモデルを改善する仕組み
繰り返し学習の基本的な流れは、入力、予測、損失計算、重み更新の4段階で考えると整理しやすくなります。まず、モデルに学習データを入力します。次に、モデルは現在の重みに基づいて予測を出します。その予測と正解を比べ、どれくらい外れているかを損失として計算します。
損失が分かると、モデルは「どの重みをどの方向へ動かせば損失が小さくなるか」を計算します。このとき使われる代表的な考え方が勾配です。勾配は、損失を減らすための方向と大きさを示す手がかりになります。
重み更新は、簡略化すると次のように表せます。
\(\theta_{t+1} = \theta_t – \eta g_t\)ここで、\(\theta_t\) は現在のパラメータ、\(g_t\) は損失を減らす方向を示す勾配、\(\eta\) は学習率です。学習率は1回の更新でどれくらい大きく動くかを決める値で、大きすぎると最適な場所を通り過ぎ、小さすぎると学習がなかなか進みません。
この流れを何度も繰り返すことで、モデルは誤差の大きい状態から、よりよい予測ができる状態へ近づきます。重要なのは、1回の更新で劇的に変わるのではなく、小さな修正を積み重ねて精度を上げる点です。
繰り返し回数と精度の関係
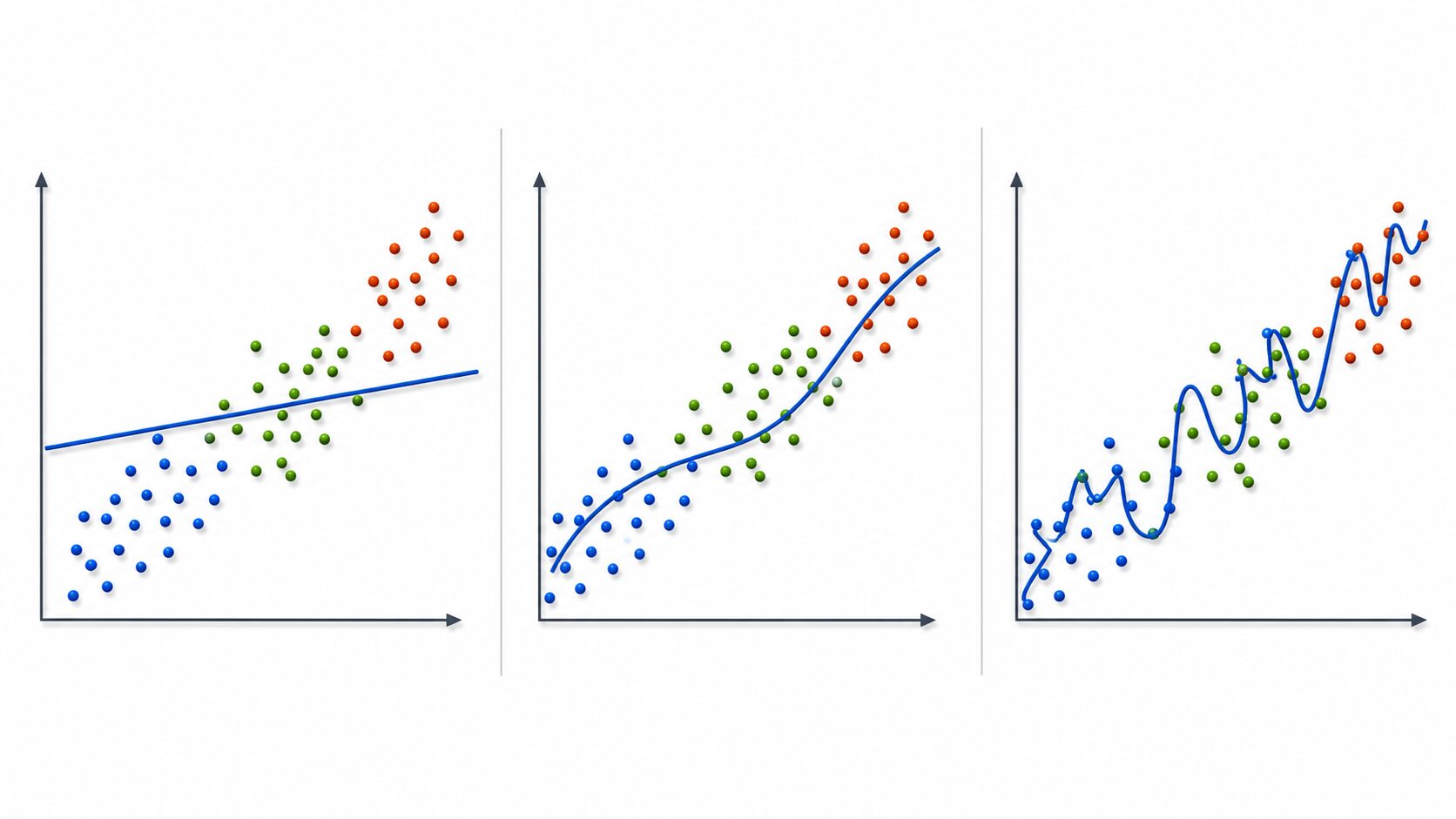
繰り返し回数は、モデルの精度に大きく関わります。回数が少なすぎると、モデルはデータに含まれる特徴を十分に学べません。この状態は学習不足と呼ばれ、訓練データに対しても検証データに対しても精度が低くなりやすいのが特徴です。
一方で、回数を増やしすぎると、モデルが学習データに過度に合わせ込んでしまうことがあります。これは過学習です。過学習したモデルは、訓練データでは高い精度を出しているように見えても、新しいデータでは性能が落ちることがあります。テスト範囲の答えだけを丸暗記し、少し形の違う問題に対応できない状態に近いと考えると分かりやすいでしょう。
そのため、繰り返し回数は多ければ多いほどよいわけではありません。実務や学習では、訓練データだけでなく検証データの損失や精度を確認し、性能が伸びなくなったところで学習を止めることがあります。この考え方は早期終了と呼ばれます。
| 繰り返し回数 | 状態 | 起きやすい問題 | 確認ポイント |
|---|---|---|---|
| 少なすぎる | 学習不足 | データの特徴を十分に捉えられない | 訓練データでも精度が低い |
| 適切 | 汎化しやすい | 訓練データと新しいデータの両方で安定しやすい | 検証データの性能も改善している |
| 多すぎる | 過学習 | 学習データに合わせ込みすぎる | 訓練精度は高いが検証精度が落ちる |
最適な回数は、データ量、データの複雑さ、モデルの種類、学習率によって変わります。画像、文章、時系列データのように複雑なデータでは多くの反復が必要になることがありますが、単純なデータでは少ない回数でも十分な場合があります。
イテレーション、エポック、バッチの違い
繰り返し学習を理解するときは、イテレーション、エポック、バッチの違いも押さえておくと混乱しにくくなります。どれも学習回数に関係する言葉ですが、指している単位が異なります。
バッチは、1回の計算でモデルに渡すデータのまとまりです。データ全体を一度に使うこともありますが、量が多い場合は小さなまとまりに分けて学習します。この小さなまとまりをミニバッチと呼ぶことがあります。
イテレーションは、1つのバッチを使って予測、損失計算、重み更新を行う1回分の処理です。エポックは、学習データ全体を一通り使い終えることを意味します。たとえば1000件のデータを100件ずつのバッチに分けると、1エポックには10回のイテレーションが含まれます。
| 用語 | 意味 | 例 |
|---|---|---|
| バッチ | 1回の計算に使うデータのまとまり | 100件ずつ学習に使う |
| イテレーション | 1つのバッチで重みを更新する1回の処理 | 100件を使って1回更新する |
| エポック | 学習データ全体を1周すること | 1000件をすべて使い終える |
この違いを知っておくと、学習ログに表示される「epoch」や「iteration」の数字を読み取りやすくなります。特に深層学習では、エポック数だけでなく、バッチサイズによってイテレーション数が変わる点に注意が必要です。
学習手法ごとに見る反復処理の役割
繰り返し学習は、特定のモデルだけで使われる考え方ではありません。ニューラルネットワーク、最適化手法、強化学習など、機械学習の多くの場面で反復処理が重要な役割を持ちます。
ニューラルネットワークでは、誤差逆伝播法によって出力と正解のずれを各層へ伝え、重みを少しずつ調整します。画像分類や自然言語処理で使われる大きなモデルも、この反復的な重み更新の積み重ねによって性能を高めています。
最適化手法では、損失が小さくなる方向を探しながら、パラメータを少しずつ移動させます。坂を下るように損失の低い場所へ近づくイメージで、確率的勾配降下法、Momentum、Adamなどの手法がよく使われます。
強化学習では、行動を試し、その結果として得られる報酬や失敗をもとに方策を更新します。ゲーム、ロボット制御、推薦システムなどでは、試行錯誤を繰り返しながら、より良い行動を選べるように学習します。
| 学習手法 | 反復処理の内容 | 目的 |
|---|---|---|
| ニューラルネットワーク | 誤差逆伝播法で重みを更新する | 予測と正解のずれを小さくする |
| 最適化手法 | 損失が小さくなる方向へパラメータを動かす | より良いパラメータを見つける |
| 強化学習 | 行動、結果、報酬をもとに方策を更新する | 長期的に良い行動を選ぶ |
このように、反復処理は機械学習の土台にある考え方です。アルゴリズムが変わっても、「結果を見て、次の状態を少し改善する」という構造は共通しています。
効率よく繰り返し学習するための工夫
繰り返し学習では、ただ回数を増やすだけでなく、効率よく改善するための工夫が重要です。代表的な工夫の一つが学習率の調整です。学習率が大きすぎると損失が安定せず、小さすぎると学習に時間がかかります。適切な学習率を選ぶことで、少ない回数でも性能を伸ばしやすくなります。
次に、最適化アルゴリズムの選択があります。単純な勾配降下法だけでなく、MomentumやAdamのように過去の勾配の情報を使って更新を安定させる手法があります。これらは、損失の地形が複雑な場合でも、より効率よく良いパラメータへ近づくために使われます。
ミニバッチ学習も重要です。全データを一度に使うと計算が重くなり、1件ずつ使うと更新が不安定になることがあります。そこで、データを適度な大きさに分けて学習することで、計算効率と安定性のバランスを取りやすくなります。
さらに、過学習を防ぐためには、早期終了、正則化、データ拡張なども使われます。これらは、訓練データだけに合わせ込みすぎず、新しいデータにも対応しやすいモデルを作るための工夫です。
初心者がつまずきやすい注意点
機械学習を学び始めた段階では、「繰り返し回数を増やせば精度が上がる」と考えがちです。しかし、実際には学習データに対する精度だけを見ていると、過学習を見逃すことがあります。訓練データ、検証データ、テストデータを分けて評価する考え方を早い段階で押さえておくと、安全にモデルを確認できます。
また、損失が下がっているのに目的の指標が良くならないこともあります。たとえば分類問題では、損失、正解率、適合率、再現率、F値など、目的に応じて見る指標が変わります。繰り返し学習の良し悪しは、何を改善したいのかに合った評価指標で判断することが大切です。
もう一つの注意点は、データの前処理や品質です。ラベルに誤りが多い、データの偏りが大きい、入力値のスケールがそろっていないと、反復学習を何度行っても安定しません。モデルや回数だけでなく、データそのものを見直す視点も必要です。
まとめ
機械学習における繰り返し学習は、モデルが予測、誤差の確認、重みの更新を繰り返しながら性能を高める仕組みです。1回分の更新処理はイテレーションと呼ばれ、ニューラルネットワークや最適化、強化学習など幅広い場面で使われます。
繰り返し学習が重要なのは、一度で正しい規則を見つけるのが難しいからです。モデルは小さな修正を積み重ねることで、データに含まれる特徴を捉え、よりよい予測ができるようになります。
ただし、回数が少なすぎれば学習不足になり、多すぎれば過学習になる可能性があります。エポック、バッチ、イテレーションの違いを理解し、検証データや評価指標を見ながら、適切な学習回数を判断することが大切です。
学習率、最適化アルゴリズム、ミニバッチ学習、早期終了などの工夫を組み合わせることで、限られた計算資源の中でも効率よくモデルを改善できます。イテレーションは、機械学習の仕組みを理解するうえで欠かせない基本概念です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年5月18日 | 反復更新の流れと回数調整の判断材料を追記 |