 学習
学習 モデル学習の重要性とは?意味・仕組み・活用例をわかりやすく解説
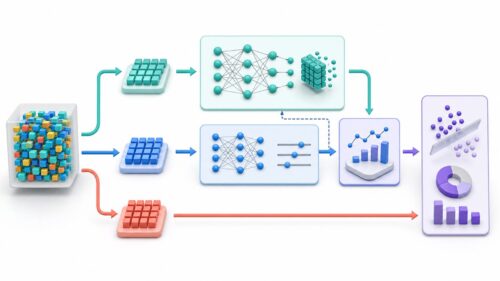
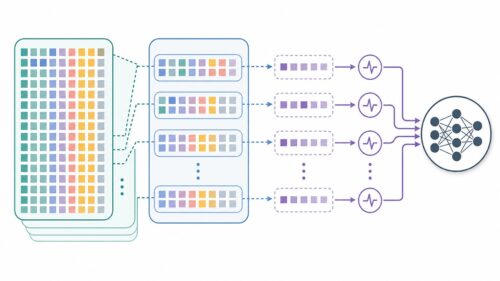
人工知能を作る上で、学習はとても大切なことです。まるで人間が学ぶように、人工知能もたくさんのことを教え込まなければ、うまく動くことができません。この学習のことを、専門的に「モデル学習」と呼びます。
良い人工知能を作るためには、質の高い教材が必要です。人間で言えば、教科書や参考書のようなものです。人工知能の場合、この教材に当たるのが「データ」です。データの質が悪かったり、間違っていたりすると、人工知能はきちんと学習できません。そして、教材と学習内容のつながりも大切です。例えば、算数を学ぶのに歴史の教科書を使っても、うまく理解できません。人工知能も同じで、学習させる内容に合ったデータを選ばなければ、正しい知識を身につけることができません。
さらに、解答例も重要です。問題を解いて、答え合わせをすることで、どこが間違っていたのか、どうすれば正しく解けるのかを学ぶことができます。人工知能も、正しい解答例を与えられて初めて、自分の出した答えが正しいかどうかを判断し、より正確な答えを出せるように学習していくのです。
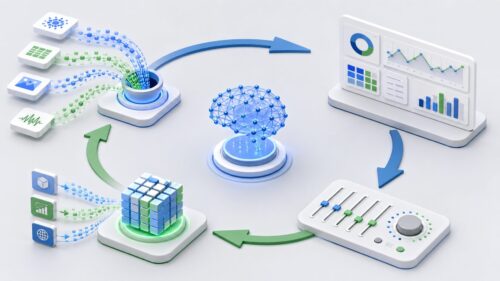
このように、質の高いデータ、適切な関連性、正確な解答例を揃えて、人工知能を学習させることで、人工知能は様々な仕事を効率よくこなし、正確な予測をすることができるようになります。このモデル学習こそが、高性能で信頼できる人工知能を作るための、なくてはならない工程なのです。このことから、これから述べるように、モデル学習の大切さについて詳しく説明していきます。