機械学習におけるバリデーションの役割とは?意味・仕組み・活用例をわかりやすく解説

AIの初心者
「バリデーション」って、AIをテストすることと同じなんですか?

AI専門家
似ているけれど、役割は少し違うよ。バリデーションは、AIが学習した内容を丸暗記しているだけでなく、未知のデータにも対応できるかを確かめるための工程なんだ。
AIの初心者
未知のデータに対応できるかを見る、ということですね。
AI専門家
その通り。例えば算数の問題をたくさん覚えたAIが、少し形の違う問題も解けるかを確認するようなものだよ。そこで結果を見ながら、モデルの作り方を調整していくんだ。
バリデーションとは。
バリデーションとは、機械学習モデルが学習に使っていないデータに対して、どの程度うまく予測できるかを確かめる検証工程です。学習データだけで良い結果が出ても、未知のデータで失敗するモデルは実用では使いにくいため、検証データを使って性能や過学習の兆候を確認します。
バリデーションとは何か
機械学習では、データからパターンを学び、未知の入力に対して分類や予測を行うモデルを作ります。しかし、学習データで高い正解率を出せることと、現実の新しいデータに強いことは同じではありません。学習データの特徴を覚えすぎたモデルは、見たことのある問題には強くても、少し条件が変わるだけで性能が落ちることがあります。
バリデーションは、モデルが学習データを丸暗記していないか、未知のデータにも対応できるかを確認するための手順です。学校の小テストに例えると、授業で解いた問題そのものではなく、同じ考え方で解ける別の問題を出して理解度を測るイメージです。
この確認によって、モデルの複雑さ、学習回数、特徴量の作り方、正則化の強さなどを調整できます。検証結果が悪い場合は、モデルの作り方やデータの準備を見直し、より汎化性能の高いモデルを目指します。汎化性能とは、まだ見ていないデータに対しても安定して良い予測を行える力のことです。
学習データ・検証データ・テストデータの違い
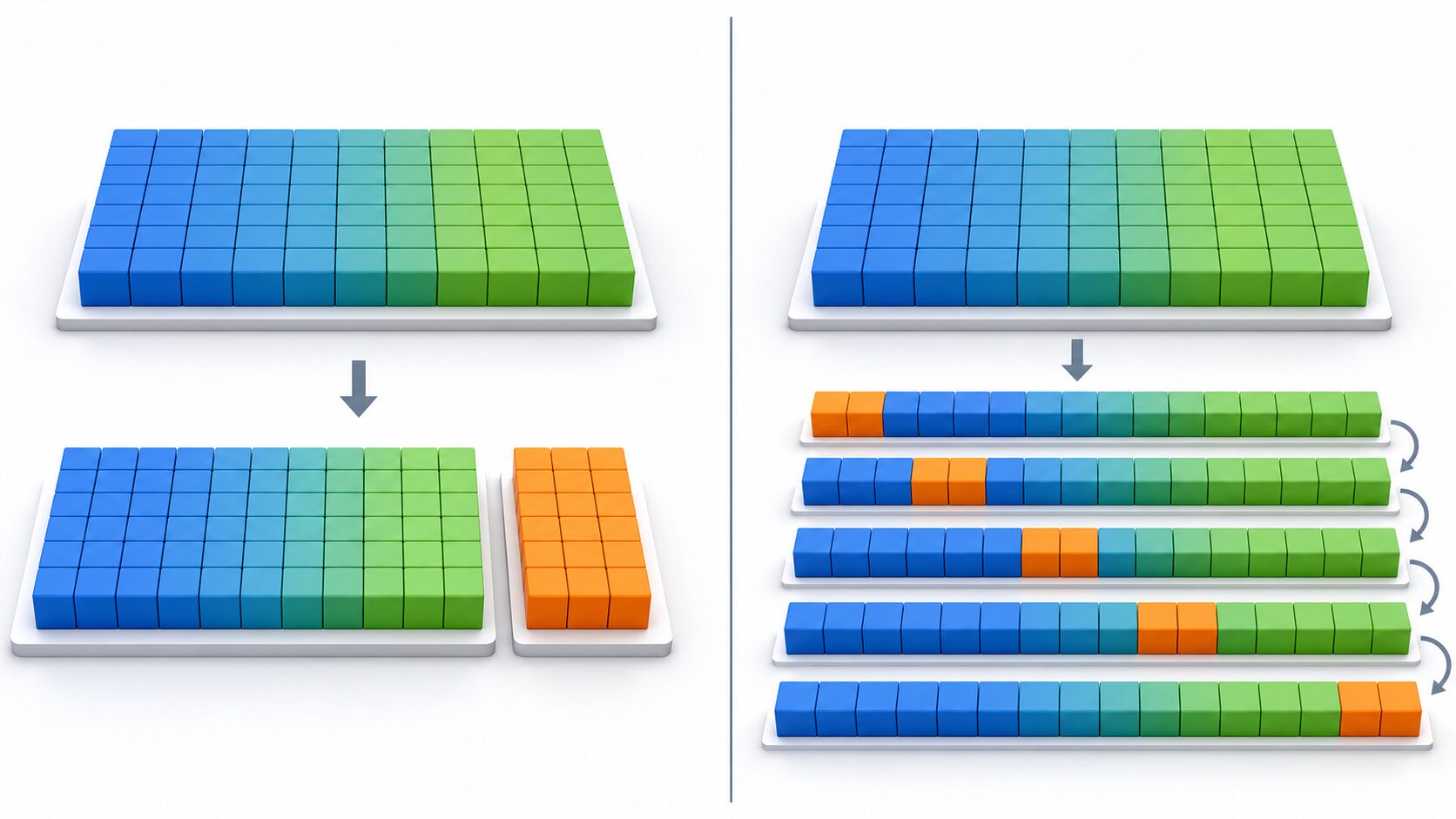
バリデーションを理解するうえで重要なのが、データの分け方です。一般的には、手元のデータを学習データ、検証データ、テストデータに分けて扱います。すべてを学習に使ってしまうと、モデルが未知データに強いかどうかを公平に確かめられません。
学習データは、モデルがパターンや規則性を覚えるために使います。検証データは、学習中または学習後にモデルの状態を確認し、設定を調整するために使います。テストデータは、調整が終わったあとに最終的な性能を確認するためのデータで、モデル作成の途中では使わないのが基本です。
初心者が混同しやすいのは、検証データとテストデータの違いです。検証データは調整に使うデータ、テストデータは最後の成績確認に残すデータと考えると整理しやすくなります。検証データで何度も調整したモデルを、同じ検証データだけで評価すると、結果が実際より良く見えることがあります。
| データの種類 | 主な用途 | 使うタイミング |
|---|---|---|
| 学習データ | モデルにパターンや規則性を学ばせる | モデルを訓練するとき |
| 検証データ | 過学習の確認やハイパーパラメータ調整に使う | モデルを改善するとき |
| テストデータ | 完成したモデルの最終性能を評価する | 調整が終わったあと |
バリデーションの代表的な方法

バリデーションには複数の方法があります。代表的なのは、ホールドアウト検証とクロスバリデーションです。どちらも未知データへの対応力を測るための手法ですが、データの使い方と計算コストが異なります。
ホールドアウト検証は、データを学習用と検証用に一度だけ分ける方法です。手順が単純で、すぐに試せるため、データ量が十分にある場合や、まず全体の感触をつかみたい場合に向いています。一方で、たまたま偏った分け方をしてしまうと、評価結果が大きく変わることがあります。
クロスバリデーションは、データを複数のグループに分け、検証に使うグループを順番に入れ替えながら評価する方法です。各回の結果を平均するため、ホールドアウト検証よりも安定した評価を得やすく、限られたデータを有効に使えます。ただし、何度も学習を行うため、計算時間は長くなります。
| 方法 | 特徴 | 利点 | 注意点 |
|---|---|---|---|
| ホールドアウト検証 | データを一度だけ学習用と検証用に分ける | 手順が簡単で計算が速い | 分割の偏りに結果が左右されやすい |
| クロスバリデーション | 検証用データを入れ替えながら複数回評価する | 評価が安定しやすく、データを有効活用できる | 学習を複数回行うため時間がかかる |
どちらを選ぶかは、データ量、モデルの重さ、求める評価の厳密さによって変わります。大量データがあり学習コストも高い場合はホールドアウト検証で十分なことがあります。データが少なく、分割の影響を抑えたい場合はクロスバリデーションが候補になります。
過学習を見つけるためのバリデーション
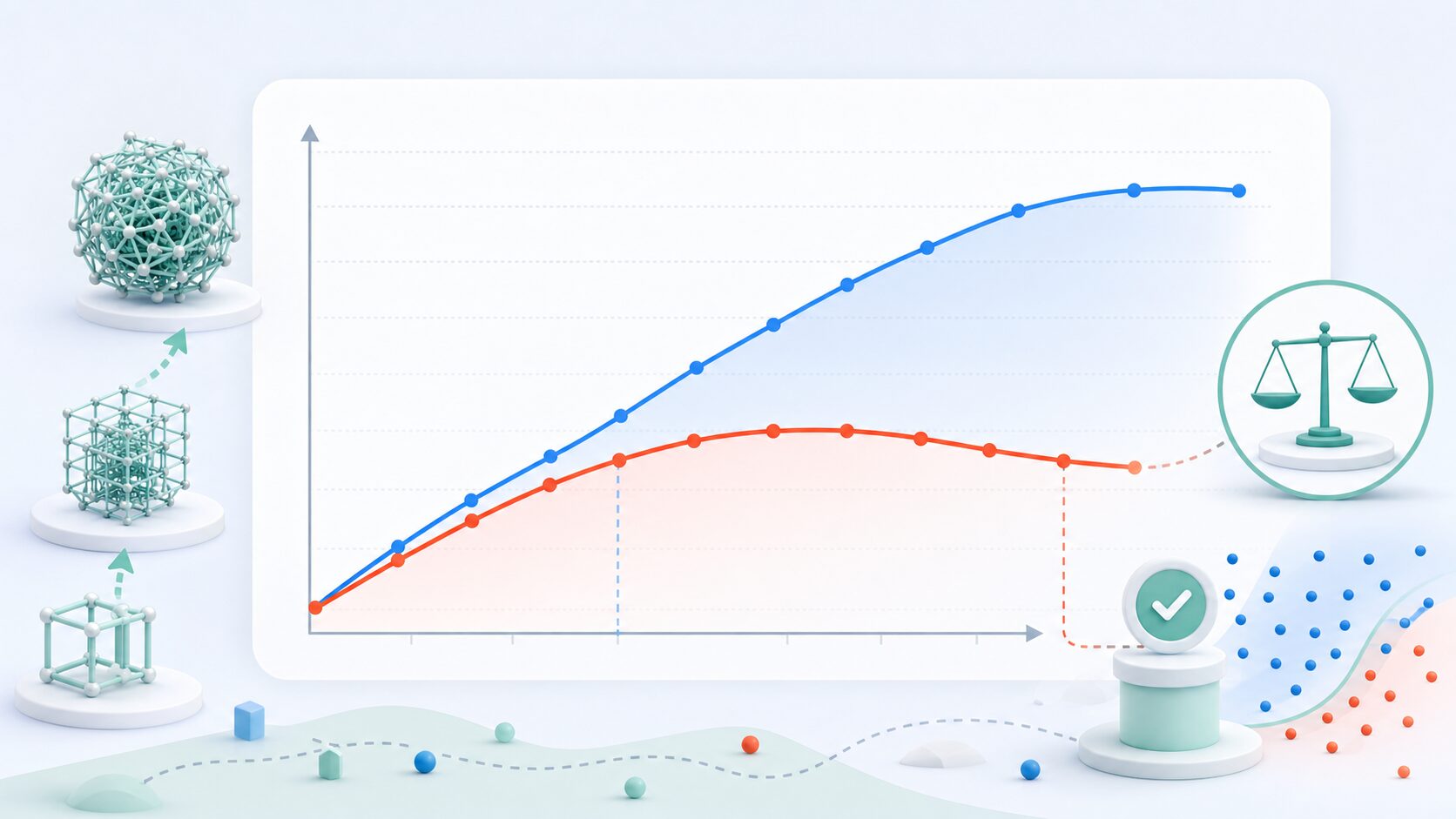
バリデーションが特に重要になるのは、過学習を見つける場面です。過学習とは、モデルが学習データに適合しすぎて、学習データに含まれる偶然のノイズや偏りまで覚えてしまう状態です。受験勉強で過去問の答えだけを暗記し、少し形の違う問題に対応できなくなる状態に似ています。
過学習が起きると、学習データでの性能は高いのに、検証データでの性能が伸びない、または途中から悪化します。つまり、モデルは学習データの中ではうまく見えても、未知データに対する汎化性能を失っている可能性があります。
学習データの性能だけで判断せず、検証データの性能を合わせて見ることが過学習対策の第一歩です。検証結果が悪化している場合は、モデルを単純にする、学習回数を調整する、正則化を使う、データを増やす、特徴量を見直すといった対応を検討します。
ただし、検証データに合わせて調整を繰り返しすぎると、今度は検証データに対して都合の良いモデルになってしまうことがあります。そのため、最後にテストデータを残しておき、調整に使っていないデータで最終確認を行うことが大切です。
実務での活用例と注意点
バリデーションは、画像認識、需要予測、医療診断、金融予測など、さまざまな機械学習の現場で使われます。例えば、画像認識で猫を判定するモデルを作る場合、学習データに晴れた屋外の猫画像ばかりが含まれていると、モデルが「屋外」や「明るい背景」を猫の特徴として誤って覚えることがあります。
このような偏りは、検証データで確認できます。屋内、暗い場所、異なる角度など、学習データとは条件が異なるデータで性能が落ちるなら、データの集め方や前処理、モデルの作り方を見直す必要があります。需要予測でも同じで、過去の特定期間だけに強いモデルは、季節変化やキャンペーン、外部要因が変わったときに外れる可能性があります。
実務では、精度の数字だけでなく、評価指標が目的に合っているかも確認します。分類なら正解率だけでなく、見逃しを減らしたいのか、誤検知を減らしたいのかによって重視する指標が変わります。時系列データでは、未来の情報が学習側に混ざると不正確な評価になるため、時間の順序を守った検証が必要です。
バリデーションは、単に点数を出す作業ではなく、モデルを現実の利用条件に近づけるための判断材料です。検証結果を見て、データ、モデル、評価方法のどこを直すべきかを考えることで、信頼できる機械学習モデルに近づけます。
まとめ
機械学習におけるバリデーションは、モデルが学習データだけに強いのではなく、未知のデータにも対応できるかを確認する重要な工程です。検証データを使うことで、過学習の兆候を見つけ、モデルの設定やデータの扱いを改善できます。
学習データ、検証データ、テストデータを分けて考えると、モデル評価の流れが整理しやすくなります。ホールドアウト検証は手軽で速く、クロスバリデーションはより安定した評価を得やすい方法です。目的やデータ量に合わせて使い分けましょう。
最終的には、バリデーションの結果を「良いモデルかどうか」の判定だけに使うのではなく、どこを改善すれば実用に近づくかを考える材料にすることが大切です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月16日 | 検証データとテストデータの違い、過学習の見方を補強 |