
VGGとは?画像認識を支えたCNNの仕組みをわかりやすく解説

AIの初心者
「VGG」って、画像認識でよく出てきますが、何を指す言葉ですか?

AI専門家
VGGは、画像認識で広く知られるCNNモデルの一つだよ。小さな3×3フィルターを何層も重ね、層が進むほど特徴マップを増やす構造が大きな特徴なんだ。
AIの初心者
小さなフィルターを重ねることや、特徴マップを増やすことにはどんな意味があるのでしょうか?
AI専門家
細かな模様から複雑な形まで段階的に学習しやすくなるんだ。VGGはその考え方をとても分かりやすい構造で示した、画像認識の重要なモデルなんだよ。
VGGとは。
VGGは、画像認識で使われる畳み込みニューラルネットワーク、つまりCNNの代表的なアーキテクチャです。画像の特徴を抽出する畳み込み層を深く重ね、すべての畳み込み層で3×3の小さなカーネルを使う点に特徴があります。プーリングで画像サイズを小さくした後は、次の畳み込み層で特徴マップの数を増やし、情報を圧縮しながら表現力を高めます。
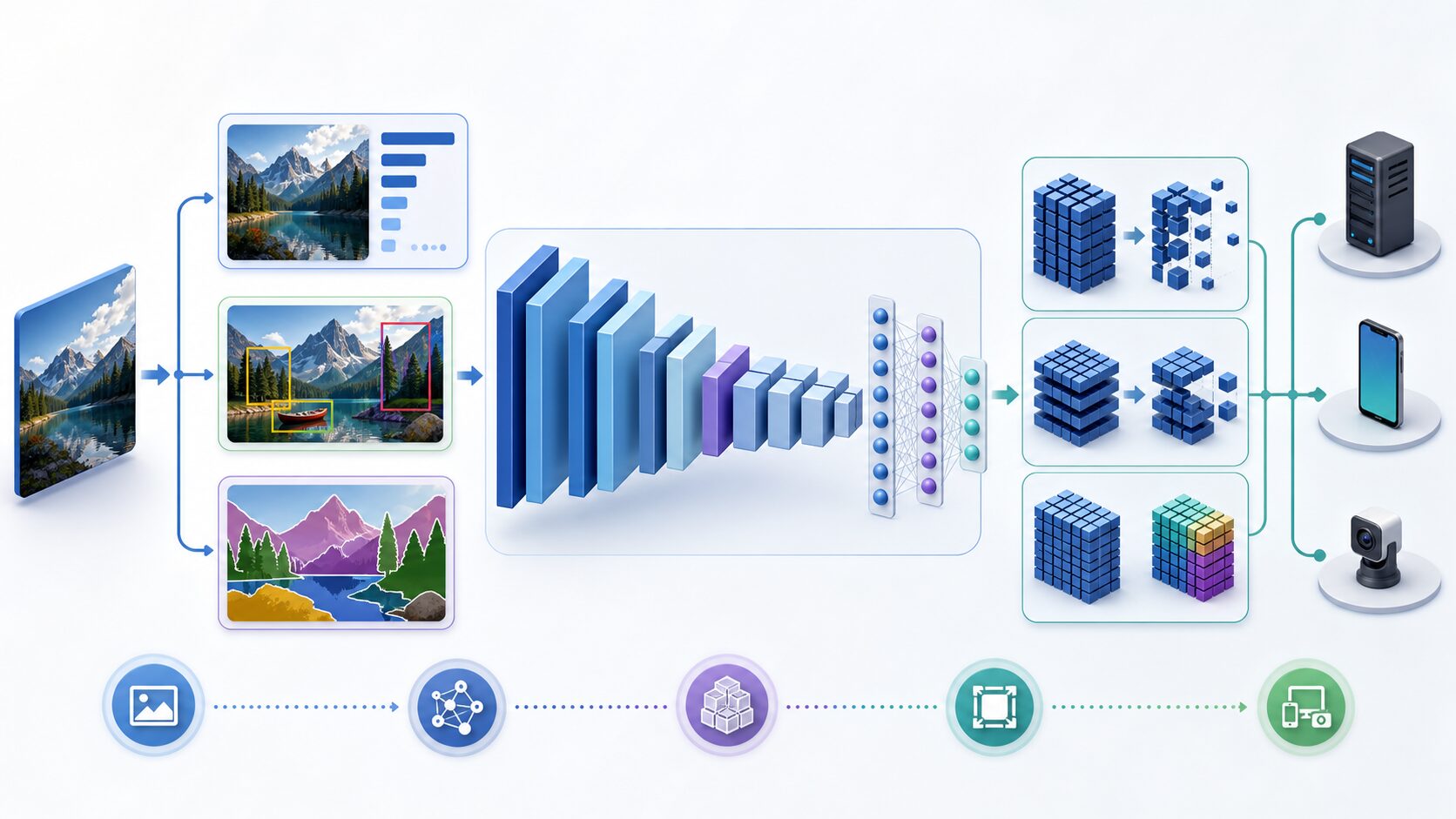
VGGとは何か
VGGは、オックスフォード大学のVisual Geometry Groupが提案した画像認識向けのCNNモデルです。名前のVGGは、この研究グループ名に由来します。代表的な構成には、重みを持つ層が16層あるVGG16、19層あるVGG19があります。
VGGが重要なのは、単に精度が高かったからではありません。「小さな畳み込みカーネルを深く積み重ねる」という設計方針を、分かりやすく強力な形で示した点にあります。画像認識では、画像の端や線、模様、部品、物体全体というように、特徴を段階的に捉える必要があります。VGGはこの階層的な処理を、比較的単純なルールで実現しました。
元記事で説明されていた通り、VGGの中心は畳み込み層とプーリング層です。畳み込み層は画像の局所的な特徴を見つける処理、プーリング層は画像の縦横サイズを小さくして計算量を抑える処理です。この2つを組み合わせることで、VGGは画像の細部と全体の意味を段階的に扱えるようになります。
| 項目 | 内容 |
|---|---|
| 名称 | VGG |
| 開発元 | オックスフォード大学 Visual Geometry Group |
| 種類 | 画像認識向けの畳み込みニューラルネットワーク |
| 主な特徴 | 3×3カーネルを使う深い畳み込み層 |
| 代表例 | VGG16、VGG19 |
VGGの基本構造
VGGは、入力画像をそのまま一度に判定するのではなく、畳み込み層、活性化関数、プーリング層を重ねながら特徴を抽出します。前半の層では画像の輪郭や角のような単純な特徴を捉え、後半の層ではそれらを組み合わせて、顔、車輪、建物の窓のような具体的な部品や物体の手がかりを扱います。
基本的な流れは、畳み込みで特徴を取り出し、活性化関数で非線形性を加え、プーリングで解像度を下げる、という繰り返しです。最後は全結合層などで分類結果に変換します。現在のCNNでは全結合層を小さくした設計も多くありますが、VGGは初期の深いCNNとして、層を積み重ねる効果を理解しやすいモデルです。
初心者が混同しやすい点として、カーネル、フィルター、特徴マップの関係があります。カーネルやフィルターは画像の一部を見る小さな窓のような重みで、特徴マップはそのフィルターが画像内のどこに反応したかを表す結果です。VGGでは、プーリングで空間サイズを下げながら、後段に進むほど特徴マップの数を増やします。
3×3カーネルを重ねる理由
VGGの最も有名な特徴は、すべての畳み込み層で3×3の小さなカーネルを使うことです。以前のCNNでは5×5や7×7のような大きめのフィルターも使われていました。大きなフィルターは広い範囲を一度に見られますが、パラメータ数が増えやすく、細かな特徴を段階的に扱う柔軟性も下がります。
3×3カーネルを複数重ねると、大きなカーネルに近い範囲を見ながら、パラメータ数を抑えられます。例えば、3×3を2層重ねると、おおよそ5×5の範囲に相当する情報を扱えます。5×5を1層だけ使う場合は25個の重みが必要ですが、3×3を2層なら9個ずつで合計18個です。実際には入力チャネル数と出力チャネル数も関係しますが、考え方としては小さな部品を積み重ねる方が効率的になります。
さらに、3×3を重ねると活性化関数を通る回数も増えます。活性化関数は、ニューラルネットワークが直線的な変換だけでなく複雑な関係を学習できるようにする処理です。つまり、VGGは小さなカーネルを使うことで、計算効率だけでなく表現力も高めています。

| 比較 | 利点 | 注意点 |
|---|---|---|
| 大きなカーネル | 広い範囲を一度に見られる | パラメータ数が増えやすい |
| 3×3カーネルの積み重ね | 表現力を保ちながら重みを抑えやすい | 層が深くなるため学習設計が重要 |
プーリング後にチャネル数を増やす理由
VGGでは、プーリング層によって画像の縦横サイズを小さくした後、次の畳み込み層で特徴マップの数を増やします。これは、元記事で説明されていた「画像情報を縮小した後に、カーネル数を増やす」という考え方です。
プーリングによって空間サイズを小さくすると、計算量は下がります。例えば、縦横を半分にすると、特徴マップ上の位置数はおおよそ4分の1になります。しかし、単に小さくするだけでは細かな情報が失われます。そこで、後段のチャネル数を増やし、より多くの種類の特徴を同時に表現できるようにします。
空間方向の情報を圧縮し、チャネル方向の表現を厚くするのがVGGの基本的な流れです。これは現在の多くのCNNにも見られる考え方で、画像のサイズを小さくしながら、特徴の種類を増やして高次の情報を扱いやすくします。

層を深くする効果
VGGが画像認識で高い性能を示した理由の一つは、畳み込み層を深く積み重ねたことです。浅い層では、縦線、横線、斜め線、角、色の変化といった単純な特徴が抽出されます。中間の層では、それらが組み合わさって模様や部品のような特徴になります。さらに深い層では、顔の一部、車輪、建物の窓など、物体を見分けるための具体的な手がかりに近づきます。
このような処理は、人間が画像を理解するときの流れにも似ています。最初から「これは猫だ」と判断するのではなく、輪郭、耳、目、毛並み、全体の形といった手がかりを組み合わせて意味を理解します。VGGはこの階層的な特徴抽出を深いCNNとして実現し、画像認識における深さの重要性を示しました。
ただし、深くすれば必ずよいわけではありません。層が深くなるほど計算量は増え、学習も難しくなります。後に登場したResNetは、より深いネットワークを学習しやすくするために残差接続を導入しました。つまりVGGは、深いCNNの有効性を示した一方で、さらに深いモデルを作るための課題も明確にしたモデルだと言えます。

| 層の位置 | 捉えやすい特徴 | 例 |
|---|---|---|
| 浅い層 | 単純な形や明暗の変化 | 線、角、輪郭 |
| 中間の層 | 複数の特徴の組み合わせ | 模様、部品、質感 |
| 深い層 | 物体を判別する手がかり | 顔のパーツ、車輪、窓 |
画像認識での貢献と使いどころ
VGGは、画像分類、物体検出、画像分割など、さまざまな画像認識タスクに影響を与えました。特にILSVRC 2014で高い成績を収めたことで、深いCNNの有効性が広く知られるきっかけになりました。VGGは1位ではありませんでしたが、単純で再利用しやすい構造と高い性能により、その後の研究や実装で広く参照されました。
実務や学習では、VGGをゼロから大規模に学習するよりも、学習済みモデルを特徴抽出器として使う場面が多くあります。例えば、画像の類似度を比べたり、分類モデルのベースラインを作ったり、転移学習の教材として使ったりする用途です。構造が分かりやすいため、CNNの仕組みを学ぶモデルとしても適しています。
また、VGGの設計思想はResNetやGoogLeNetなどの後続モデルにも影響を与えました。ResNetはより深い層を学習しやすくし、GoogLeNetは複数サイズの畳み込みを組み合わせて効率化を進めました。VGGは現在最先端の軽量モデルではありませんが、CNNの基礎を理解する上では今でも重要な位置にあります。

VGGの注意点と現在の位置づけ
VGGの弱点は、計算量とパラメータ数が多いことです。特に全結合層を含む古典的なVGGはモデルサイズが大きく、推論にも多くのメモリと計算資源を使います。そのため、スマートフォン、組み込み機器、リアルタイム動画処理のような環境では、そのまま使いにくい場合があります。
この課題に対しては、枝刈り、量子化、モデル圧縮、蒸留などの軽量化手法が使われます。枝刈りは重要度の低い重みや接続を削る方法、量子化は重みや計算を少ないビット数で扱う方法、モデル圧縮や蒸留は大きなモデルの知識を小さなモデルへ移す考え方です。
現在の画像認識では、ResNet、EfficientNet、Vision Transformer系のモデルなど、VGGより効率や精度に優れた選択肢も多くあります。それでもVGGは、CNNがどのように特徴を階層的に学習するのかを理解するための基準モデルとして価値があります。初学者は、VGGを通じて畳み込み、プーリング、チャネル数、深さ、過学習、転移学習の関係を整理すると、その後のモデルも理解しやすくなります。
| 観点 | VGGの特徴 | 補足 |
|---|---|---|
| 長所 | 構造が単純で理解しやすい | CNN学習の教材やベースラインに向く |
| 長所 | 学習済みモデルを使いやすい | 特徴抽出や転移学習で利用される |
| 短所 | 計算量とモデルサイズが大きい | 軽量化や別モデルの検討が必要 |
| 現在の位置づけ | 歴史的にも教育的にも重要なCNN | 最新用途では効率のよいモデルと比較する |
まとめ
VGGは、画像認識で大きな役割を果たしたCNNアーキテクチャです。3×3の小さなカーネルを重ねること、プーリング後に特徴マップ数を増やすこと、層を深くして階層的に特徴を抽出することが主な特徴です。
この設計により、VGGは画像分類をはじめとする画像認識タスクで高い性能を示し、その後のCNN研究にも大きな影響を与えました。一方で、計算量やモデルサイズが大きいため、現在の実務では軽量化や別モデルとの比較が重要です。VGGを理解すると、CNNの基本構造だけでなく、現代の画像認識モデルがなぜ改良されてきたのかも見えやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年6月10日 | VGG16や軽量化の観点を補い、CNNの流れを追える形に更新 |