REINFORCEとは?方策勾配法の仕組みをわかりやすく解説

AIの初心者
「REINFORCE」ってなんですか?強化学習の用語だとは聞いたのですが、仕組みがよくわかりません。

AI専門家
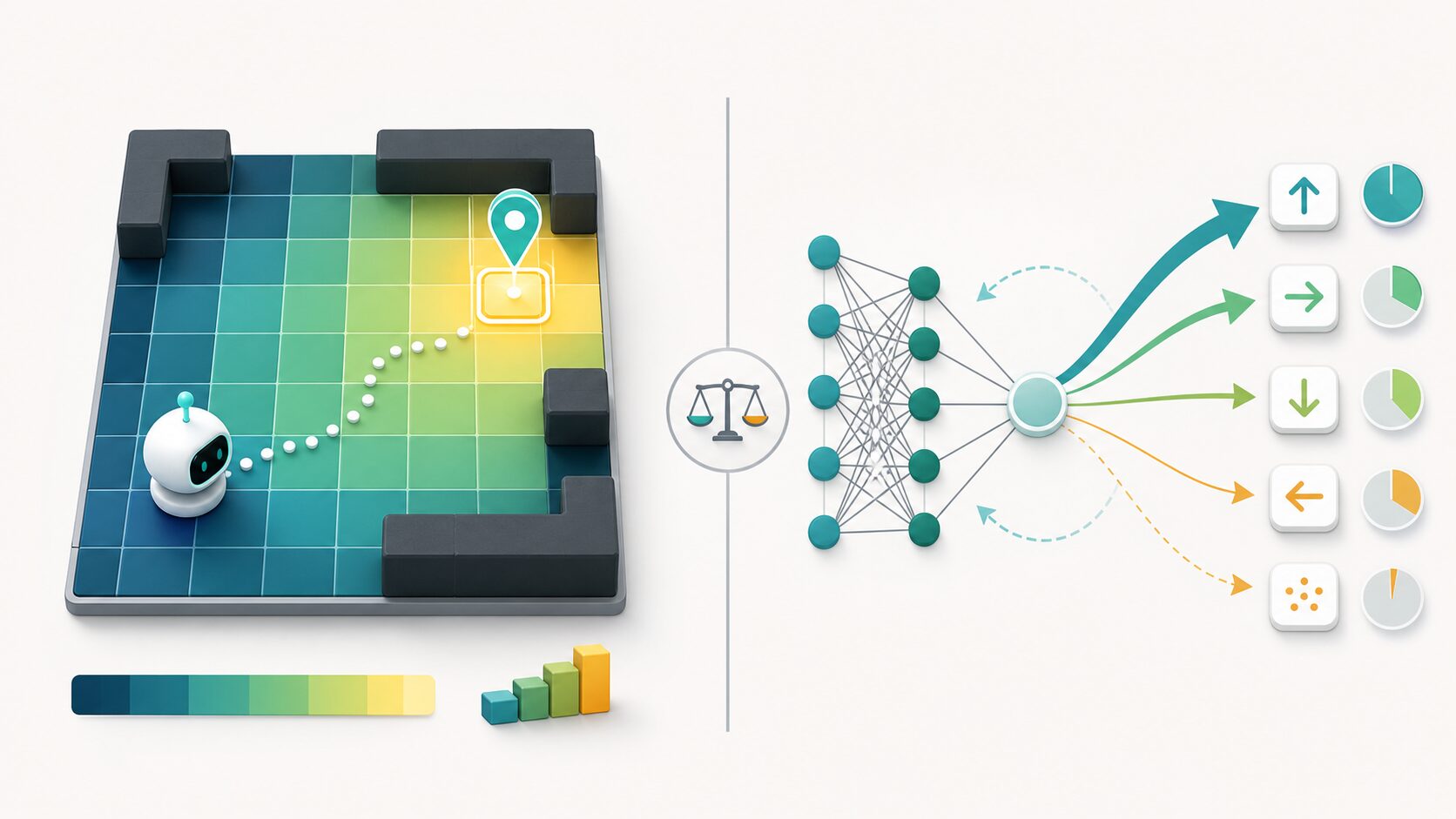
REINFORCEは、強化学習で使われる方策勾配法の基本的なアルゴリズムだよ。迷路を進むロボットのように、何度も試して得られた報酬を手がかりに、よい行動を選ぶ確率を少しずつ高めていく方法なんだ。
AIの初心者
他の強化学習の方法とは、どこが違うんですか?
AI専門家
多くの手法は行動の価値を推定してから行動を選ぶけれど、REINFORCEは方策そのものを直接調整する点が特徴だよ。成功した行動の確率を上げ、うまくいかなかった行動の確率を下げる、という考え方で理解すると入りやすいね。
REINFORCEは、強化学習で使われる方策勾配法の代表的な基本アルゴリズムです。エージェントが環境の中で行動し、得られた報酬をもとに「次にどの行動を選びやすくするか」を直接調整します。
この記事では、REINFORCEの意味、価値関数を使う手法との違い、学習の流れ、利点と欠点、関連する改善手法を、初学者向けに整理します。
REINFORCEとは
REINFORCEとは、強化学習において方策を直接改善するための手法です。ここでいう方策とは、ある状態でどの行動をどの確率で選ぶかを決めるルールのことです。
例えば、迷路を進むエージェントを考えます。現在地から「上へ進む」「右へ進む」「戻る」といった選択肢があるとき、方策はそれぞれの行動を選ぶ確率を出します。REINFORCEでは、ゴールに近づけた行動の確率を高め、よくない結果につながった行動の確率を下げるように方策を更新します。
名前の通り、よい結果につながった行動を強める考え方ですが、単に成功例を丸暗記するわけではありません。報酬という数値を使って、方策のパラメータを少しずつ動かし、長期的に得られる報酬が大きくなる方向を探します。
強化学習と方策の基本
強化学習は、エージェントが環境と相互作用しながら学習する枠組みです。エージェントは状態を観測し、行動を選び、その結果として報酬を受け取ります。目的は、目先の報酬だけでなく、将来まで含めた累積報酬を大きくすることです。
このとき重要になるのが方策です。方策は、状態を入力として行動、または行動の確率分布を出力します。決定的な方策なら「この状態では必ず右へ進む」と決めます。一方、確率的な方策なら「右へ進む確率は70%、上へ進む確率は20%、戻る確率は10%」のように表します。
REINFORCEが扱うのは主に確率的な方策です。確率を持たせることで、既に良さそうな行動を選びつつ、まだ試していない行動も探索できます。強化学習では、この探索と活用のバランスが学習の成否に大きく関わります。
価値関数ベースの手法との違い
強化学習には、大きく分けて価値関数を使う方法と、方策を直接最適化する方法があります。価値関数ベースの手法では、ある状態や行動が将来どれくらい良い結果につながるかを数値として推定します。Q学習のような手法は、この考え方に近い代表例です。
価値関数を使う場合、エージェントは「価値が高い行動」を選ぶことで良い行動を見つけます。つまり、まず行動の良さを評価し、その評価をもとに行動を決める流れです。
一方、方策勾配法では、方策そのものをパラメータ付きの関数として表し、報酬が大きくなる方向へパラメータを更新します。REINFORCEはこの方策勾配法の基本形であり、価値関数を経由せずに行動確率を直接調整する点が特徴です。
| 観点 | 価値関数ベース | REINFORCE |
|---|---|---|
| 学習対象 | 状態や行動の価値 | 行動を選ぶ方策 |
| 行動の選び方 | 価値が高い行動を選ぶ | 報酬が高くなるよう行動確率を変える |
| 特徴 | 価値の推定が重要 | 方策を直接最適化できる |
REINFORCEの仕組み

REINFORCEは、モンテカルロ法に基づく手法です。モンテカルロ法とは、何度も試行を行い、その結果から期待値や傾向を推定する考え方です。REINFORCEでは、エピソードと呼ばれる一連の行動が終わったあと、そのエピソードで得られた報酬を使って方策を更新します。
基本的な流れは次の通りです。まず、現在の方策に従って行動を選びます。次に、環境から報酬を受け取りながらエピソードの終了まで進みます。最後に、エピソード全体の報酬をもとに、選ばれた行動の確率が上がる方向、または下がる方向へ方策のパラメータを更新します。
迷路の例なら、ゴールに到達した経路で選ばれた行動は、次回以降も選ばれやすくなります。反対に、遠回りや失敗につながった行動は選ばれにくくなります。ただし、1回の成功や失敗だけで方策を大きく変えすぎると学習が不安定になるため、学習率を使って少しずつ調整します。
数式で見るREINFORCEの更新
\(J(\theta)=\mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)]
\)
REINFORCEでは、方策をパラメータθで表したものをπθとし、その方策で得られる期待報酬J(θ)を大きくすることを目指します。直感的には「今の方策で行動したとき、平均してどれくらい良い結果になるか」を最大化します。
\(\nabla_\theta J(\theta) \approx \sum_t \nabla_\theta \log \pi_\theta(a_t|s_t) G_t
\)
この式では、ある時点tで状態s_tから行動a_tを選んだ確率の対数を使い、その行動後に得られる報酬の合計G_tを掛けています。報酬が大きければ、その行動を選ぶ確率を上げる方向に更新されます。報酬が小さい、または悪い結果なら、その行動を選びにくくする方向に働きます。
初心者が押さえるべき点は、式の細部よりも、「行動を選んだ確率」と「その後の報酬」を結び付けて方策を更新するという構造です。この考え方が、方策勾配法の基本になります。
REINFORCEの利点
REINFORCEの利点は、まず仕組みが比較的わかりやすいことです。価値関数を別に学習しなくても、エピソードから得られた報酬を使って方策を更新できます。そのため、方策勾配法の考え方を学ぶ入口として適しています。
また、確率的な方策を自然に扱える点も重要です。ゲームAIのように相手に行動を読まれたくない場合や、ロボット制御のように連続的な動作を調整したい場合、行動を確率分布として扱えることは大きな意味を持ちます。
さらに、REINFORCEを理解すると、Actor-Criticなどの発展手法も学びやすくなります。多くの実用的な強化学習手法は、REINFORCEの考え方をそのまま使うというより、弱点を補う形で発展しています。基礎としての価値が高い手法だと言えます。
| 利点 | 内容 |
|---|---|
| 構造が単純 | エピソードの報酬を使って方策を直接更新するため、考え方を追いやすい。 |
| 確率的な行動を扱える | 行動を確率で選ぶため、探索やランダム性を含む問題に向いている。 |
| 発展手法の基礎になる | 方策勾配法やActor-Criticを理解するための土台になる。 |
REINFORCEの欠点と注意点
REINFORCEの大きな欠点は、学習が不安定になりやすいことです。エピソード全体の報酬をもとに更新するため、たまたま高い報酬が出た行動を過大評価したり、偶然悪い結果になった行動を過小評価したりすることがあります。
特に、報酬のばらつきが大きい問題では、方策勾配の推定値の分散も大きくなります。分散が大きいとは、更新方向が試行ごとにぶれやすいという意味です。これにより、学習がなかなか収束しなかったり、良い方策に近づくまで多くの試行が必要になったりします。
もう一つの注意点は、エピソードが終わるまで更新できないことです。ゴールまで長い手順が必要なタスクでは、報酬が得られるまで時間がかかり、どの行動が本当に良かったのかを判断しにくくなります。REINFORCEを実務でそのまま使う場面が限られるのは、この学習効率の問題が大きいためです。
改良手法と関連概念
REINFORCEの弱点を補うために、いくつかの改善方法が使われます。代表的なのがベースラインの導入です。ベースラインは、報酬から基準値を引くことで、更新方向のばらつきを抑える考え方です。報酬そのものではなく「期待よりどれくらい良かったか」を見ることで、学習を安定させやすくなります。
割引報酬和も重要です。将来の報酬を現在の判断にどれくらい反映するかを調整することで、短期的な結果と長期的な結果のバランスを取ります。学習率の調整も欠かせません。学習率が大きすぎると方策が急に変わり、小さすぎると学習が進みにくくなります。
関連する発展手法としては、Actor-Criticがあります。Actorは方策を担当し、Criticは価値を推定します。つまり、REINFORCEのような方策更新に、価値推定を組み合わせて安定性を高める考え方です。REINFORCEを理解しておくと、このような発展手法の役割も見通しやすくなります。
REINFORCEを学ぶときの確認ポイント
REINFORCEを学ぶときは、まず「方策」「報酬」「エピソード」「勾配上昇」の関係を整理すると理解しやすくなります。方策が行動確率を出し、エージェントが行動し、報酬を受け取り、その結果で方策を更新する、という流れです。
次に、価値関数を使う手法との違いを確認しましょう。REINFORCEは価値関数を使わないから報酬を見ない、という意味ではありません。報酬は使いますが、行動価値を別に推定するのではなく、報酬をもとに方策を直接調整します。
最後に、REINFORCEは基礎として重要ですが、万能な手法ではない点も押さえておく必要があります。学習が不安定になりやすいため、実際の応用ではベースラインやActor-Criticなど、分散を下げる工夫と一緒に考えられることが多くあります。
まとめ
REINFORCEは、強化学習における方策勾配法の基本手法です。価値関数を先に学習するのではなく、エピソードで得られた報酬をもとに、行動を選ぶ確率を直接更新します。
仕組みが比較的単純で、確率的な方策を理解する入口として役立ちます。一方で、報酬のばらつきに弱く、勾配推定の分散が大きくなりやすいという課題があります。
そのため、REINFORCEは単体で実用する手法というより、方策勾配法やActor-Criticなどの発展手法を理解するための土台として重要です。強化学習を学ぶ際は、定義だけでなく、価値関数ベース手法との違いと、学習が不安定になる理由まで合わせて押さえておくと理解が深まります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月10日 | 価値関数との違い、更新式、分散対策を追記 |