アルゴリズム
アルゴリズム ランダムフォレスト入門
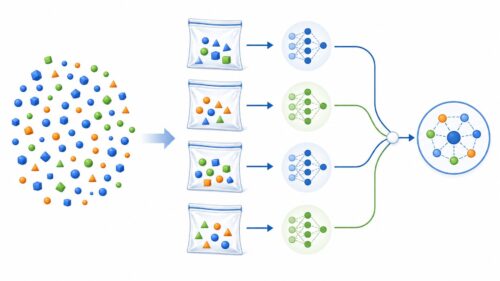
たくさんの木々が茂る森を思い浮かべてみてください。ランダムフォレストは、まさにその名の通り、決定木と呼ばれる予測モデルがたくさん集まった森のようなものです。個々の木は、データの特徴に基づいて判断を下します。そして、最終的な判断は、森全体の木々の意見をまとめることで決定されます。これが、ランダムフォレストの基本的な考え方です。
ランダムフォレストは、機械学習の中でもアンサンブル学習と呼ばれる手法の一種です。アンサンブル学習とは、複数のモデルを組み合わせて、全体的な性能を向上させることを目指す手法です。まるで、様々な専門家がそれぞれの知識を出し合って、より良い結論を導き出す会議のようなものです。ランダムフォレストでは、たくさんの決定木を並列に学習させ、それぞれの予測結果を集約することで、単体の決定木よりも高い精度と安定した予測を実現します。
ランダムフォレストの大きな特徴は、予測の際に使用するデータをランダムに選択することです。そして、それぞれの木を学習させる際にも、データの特徴をランダムに選びます。このようにランダム性を導入することで、個々の木に多様性を持たせ、森全体の予測能力を高めています。例えるなら、様々な分野の専門家を集めることで、より多角的な視点からの判断が可能になるようなものです。
ランダムフォレストは、物事をグループ分けする分類問題と、数値を予測する回帰問題の両方に適用できます。そのため、様々な分野で広く活用されています。例えば、病気の診断や顧客の行動予測、商品の需要予測など、データに基づいて判断や予測を行う必要がある場面で、ランダムフォレストは力を発揮します。ランダムフォレストは、複雑な計算を必要とせず、比較的簡単に利用できるという点も大きな利点です。