バギングとランダムフォレストとは?意味・仕組み・活用例をわかりやすく解説

AIの初心者
「バギング」は複数のモデルを使うそうですが、どのような仕組みなんですか?

AI専門家
元のデータから重複を許して標本を何組も作り、それぞれでモデルを学習させるんだ。くじ引きに似た「ブートストラップサンプリング」を使うよ。
AIの初心者
少しずつ違うデータで学ぶんですね。各モデルの予測はどうまとめるのでしょうか?
AI専門家
分類なら多数決、回帰なら平均でまとめることが多いよ。ランダムフォレストは決定木を使い、特徴量の選び方にもランダム性を加えた代表例なんだ。
バギングとランダムフォレストの違い
バギングは、異なる標本で学習した複数モデルの予測を統合するアンサンブル学習です。ランダムフォレストはその考え方を決定木に適用し、さらに各分岐で検討する特徴量もランダムに絞ります。データと特徴量の二つに変化を与えることで、木同士が似すぎるのを防ぎます。
バギングとは
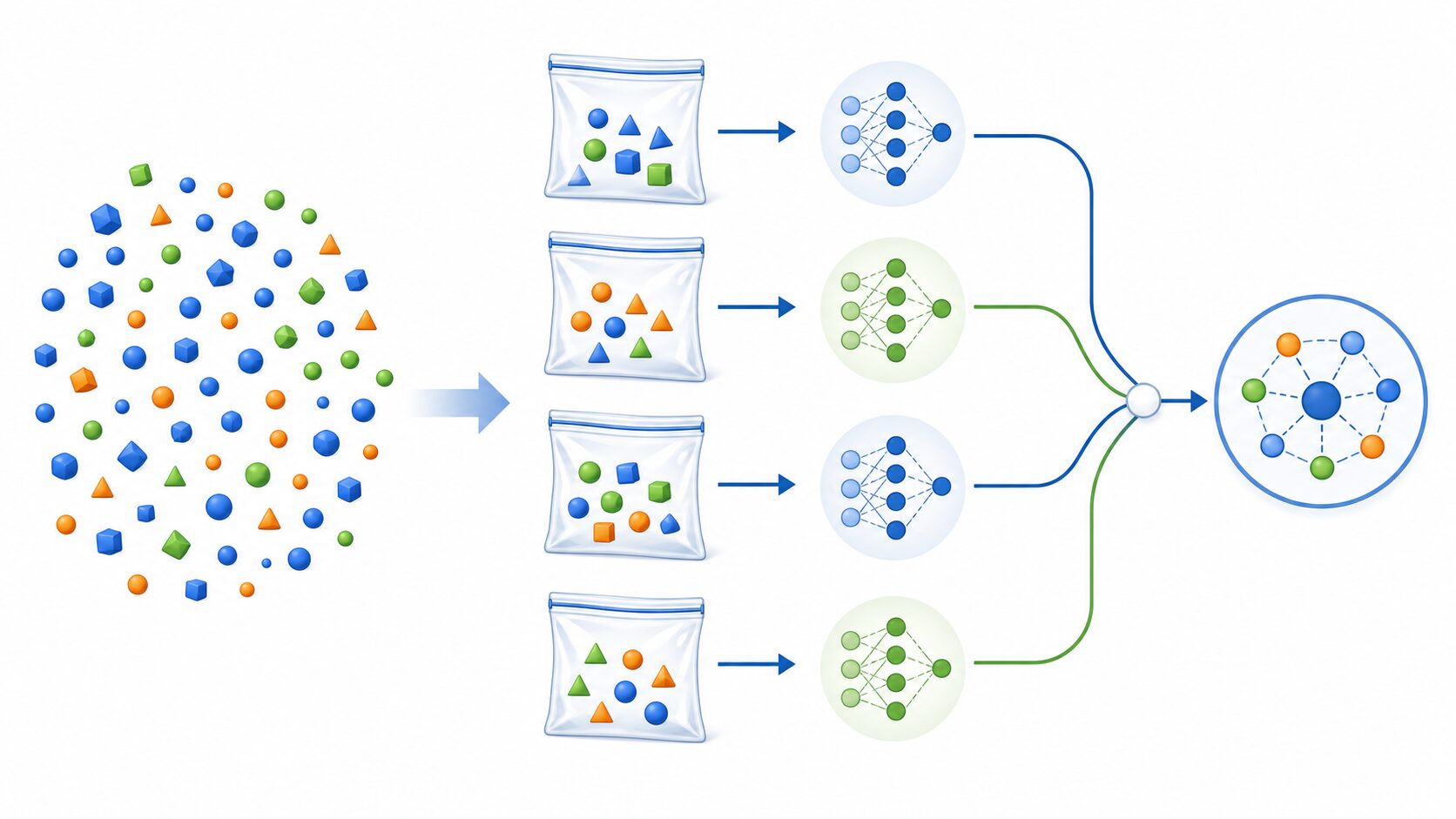
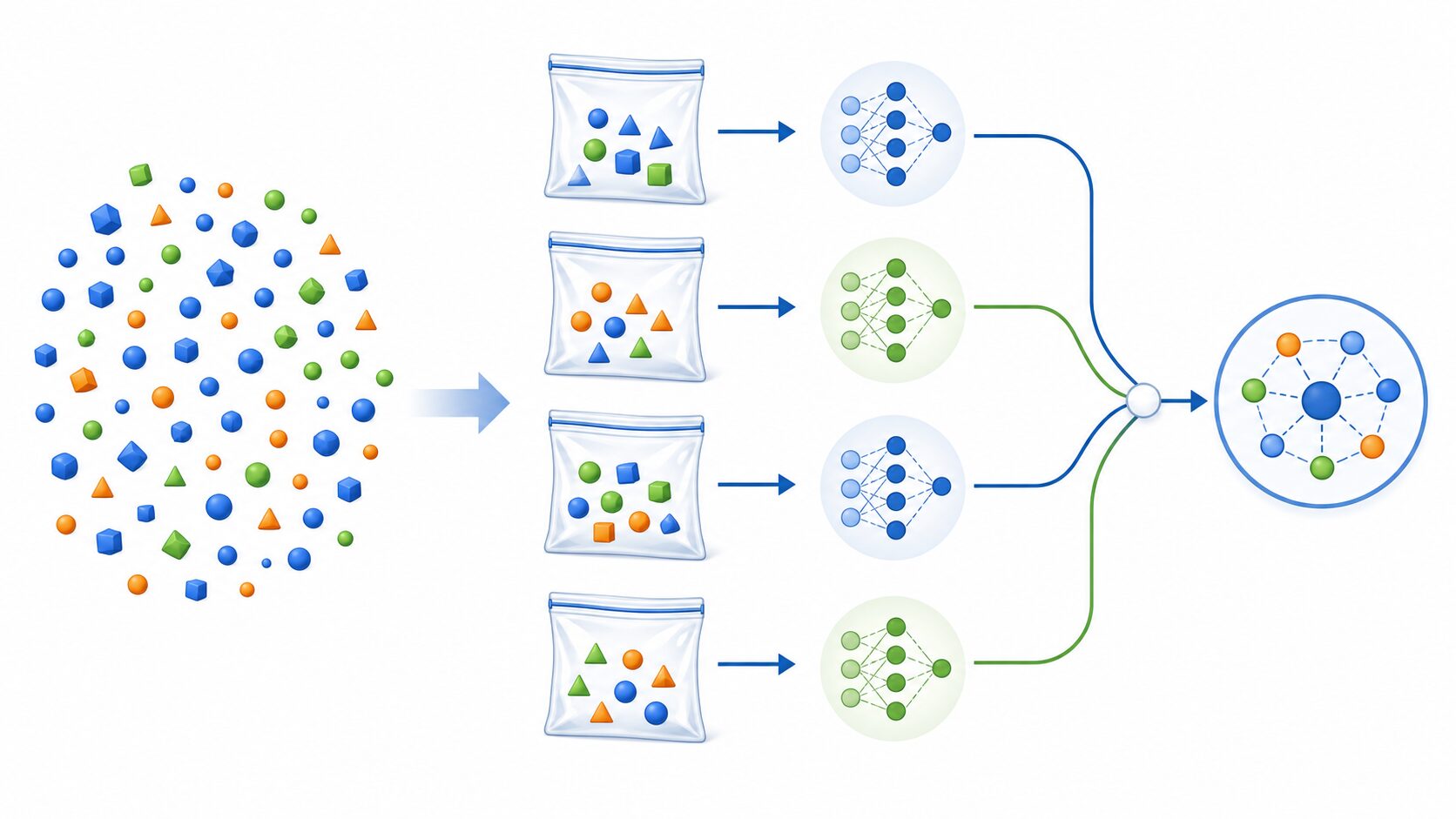
バギング(bagging)は、bootstrap aggregatingを縮めた名称です。元の学習データから複数のブートストラップ標本を作り、同じ種類の学習アルゴリズムをそれぞれに適用して、予測結果を一つにまとめます。
分類問題では各モデルの予測クラスを多数決で決め、回帰問題では予測値の平均を取るのが基本です。たとえば10個の分類モデルのうち7個が「A」、3個が「B」と予測した場合、全体の答えは「A」になります。
バギングの主な狙いは、学習データのわずかな違いで予測が大きく変わるモデルのばらつき(分散)を小さくすることです。特に、深い決定木のように柔軟で不安定になりやすいモデルと相性がよい手法です。
バギングの仕組みとブートストラップサンプリング
元の学習データが100件なら、通常は100回の抽出を行って一つの標本を作ります。ただし、抽出したデータを元に戻してから次を選ぶ「復元抽出」なので、同じデータが複数回入る一方、一度も選ばれないデータもあります。この操作を繰り返して複数の学習用標本を用意します。
- 元の学習データから、重複を許して複数の標本を作る。
- 各標本で同じ種類のモデルを別々に学習させる。
- 新しいデータを各モデルへ入力する。
- 分類は多数決、回帰は平均などで予測を統合する。
単純に同じデータで同じモデルを何度も学習しても、似た予測しか得られません。標本を変えて判断のずれを作り、そのずれを集約によって打ち消す点が重要です。ただし、モデル同士の誤りが強く似ている場合は、数を増やしても改善が小さくなります。
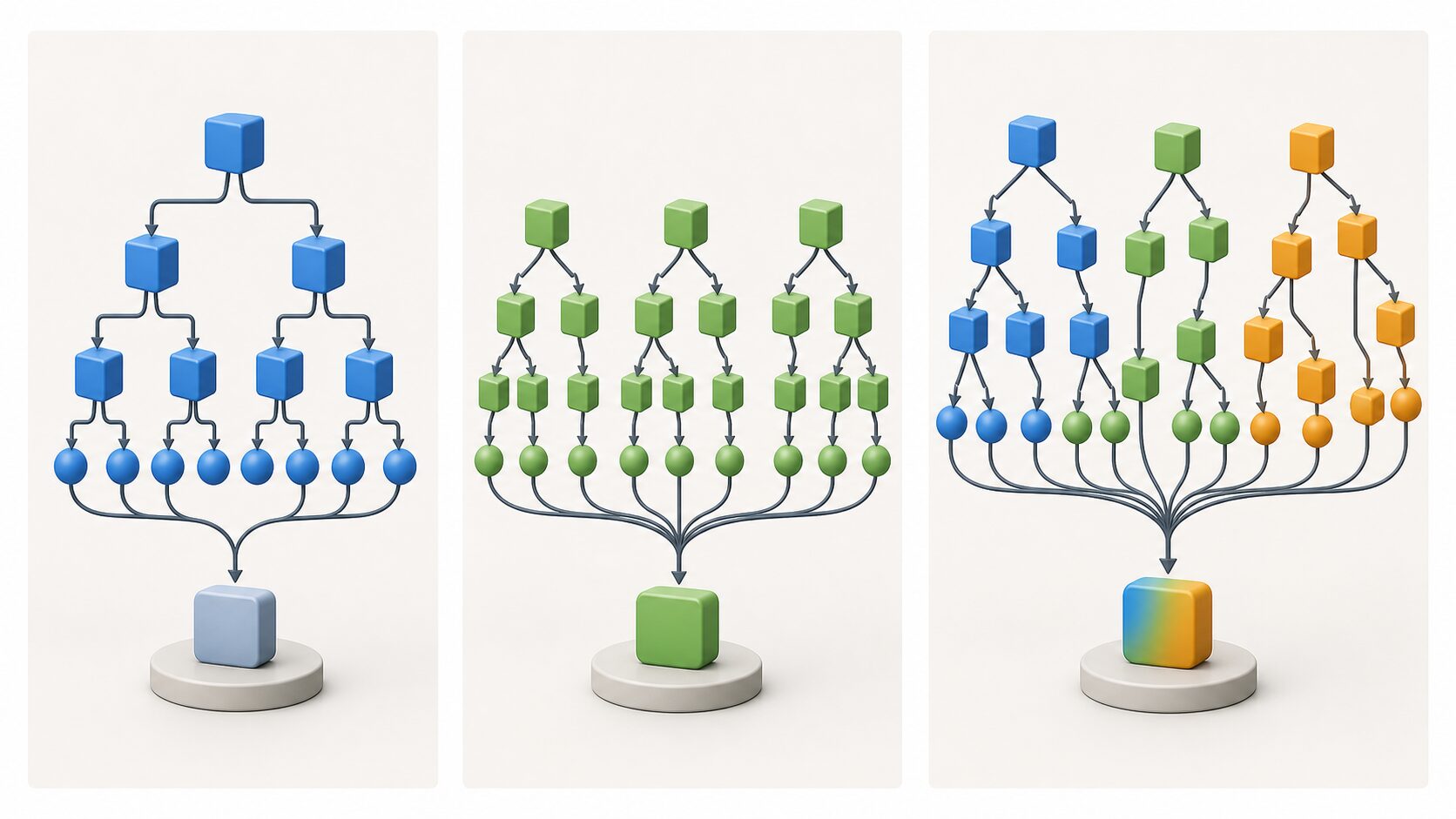
ランダムフォレストとは
ランダムフォレストは、バギングのベースモデルに決定木を使う代表的なアルゴリズムです。決定木は「年齢が30歳未満か」「利用回数が5回以上か」のような条件でデータを枝分かれさせ、葉に到達した結果から分類や数値予測を行います。
通常の決定木は、毎回すべての特徴量から最適な分岐を探します。これに対しランダムフォレストでは、各分岐で候補となる特徴量をランダムに一部だけ選び、その候補内で分岐を決めます。木全体で同じ特徴量だけを使うという意味ではありません。

強い特徴量が一つあると、すべての木が似た分岐を選びやすくなります。特徴量候補を制限すると、別の特徴量を使う木も生まれ、木同士の相関が下がります。精度のある木を保ちながら予測の似すぎを抑えることが、ランダムフォレストの強さにつながります。
単一の決定木・バギング・ランダムフォレストの違い

| 比較項目 | 単一の決定木 | 一般的なバギング | ランダムフォレスト |
|---|---|---|---|
| モデル数 | 1本 | 複数 | 複数の決定木 |
| 学習データ | 原則として全体 | ブートストラップ標本 | ブートストラップ標本 |
| 特徴量の扱い | 全候補から選ぶ | ベースモデル次第 | 各分岐で候補をランダムに絞る |
| 予測の統合 | 不要 | 多数決・平均など | 多数決・平均など |
| 特徴 | 説明しやすいが不安定になりやすい | 分散を抑えやすい | 木の相関も抑えやすい |
つまり、バギングは複数モデルを作って統合する一般的な枠組みであり、ランダムフォレストはその具体的な実装の一つです。「バギング=ランダムフォレスト」ではありません。
顧客の解約予測で考える具体例
通信サービスの顧客について、契約期間、月額料金、問い合わせ回数、利用量などから解約の有無を予測するとします。ランダムフォレストでは、顧客データを復元抽出して木ごとに異なる標本を作ります。
ある木は契約期間と問い合わせ回数を重視し、別の木は料金と利用量を重視するかもしれません。新しい顧客に対して100本の木が予測し、65本が「解約する」、35本が「継続する」と判断すれば、最終予測は「解約する」です。確率を扱う実装では、賛成した木の割合などをクラス確率の目安として利用することもあります。
メリットと向いている場面
- 過学習を抑えやすい:単一の深い決定木より予測が安定しやすい。
- 非線形な関係を捉えられる:単純な直線では表しにくい条件分岐や特徴量同士の関係を学習できる。
- 前処理が比較的少ない:数値特徴量の標準化が必須ではなく、外れ値の影響も線形モデルより受けにくいことがある。
- 分類と回帰の両方に使える:顧客離反、故障検知、価格予測など幅広い表形式データに適用できる。
- 学習を並列化しやすい:各木をおおむね独立に学習できる。
まず性能の基準を作りたい表形式データの課題では、有力な候補です。一方、画像や文章を未加工のまま入力する課題では、専用の深層学習モデルなどが適する場合があります。
注意点と不得意なケース
多数の木を保存・実行するため、単一の決定木よりメモリ使用量と予測時間が増えます。また、一本の木は追いやすくても、森全体の判断を一つの規則として説明するのは簡単ではありません。説明責任が重要な用途では、部分依存、SHAPなどの説明手法や、より単純なモデルとの比較が必要です。
木ベースの回帰は、学習データの範囲外へ直線的な傾向を延長する「外挿」が苦手です。クラス不均衡が大きい場合は、正解率だけで判断せず、適合率、再現率、F1、ROC-AUCなど目的に合う指標を確認し、クラス重みや再標本化も検討します。
特徴量重要度も因果関係を示すものではありません。重要度の算出法によっては、候補値の多い特徴量が高く評価されやすいなどの偏りがあります。相関した特徴量同士で重要度が分散することもあるため、置換重要度など複数の見方で確かめます。
OOB評価と主なハイパーパラメータ
ブートストラップ標本を作ると、各木の学習に一度も使われないデータが残ります。これをOOB(out-of-bag)データと呼びます。あるデータを使わなかった木だけでそのデータを予測し、全データについて結果を集約すれば、別の検証データを切り出さずに汎化性能の目安を得られます。ただし、最終評価には目的に応じた交差検証や独立したテストデータも有用です。

| 設定 | 役割と確認ポイント |
|---|---|
| 木の本数 | 増やすと予測が安定しやすいが、計算量とメモリも増える。 |
| 木の深さ・葉の最小サンプル数 | 各木の複雑さを調整する。制限を強めると過学習を抑えやすい。 |
| 分岐で使う特徴量候補数 | 木の強さと木同士の多様性のバランスを左右する。 |
| サンプル数・復元抽出 | 木ごとの学習データの違いとOOB評価の可否に関わる。 |
| 乱数シード | 実験の再現性を確保する。性能を上げる設定ではない。 |
ブースティングとの違い
バギングとブースティングは、どちらも複数モデルを組み合わせるアンサンブル学習ですが、学習の進め方が異なります。バギングはモデルをおおむね独立・並列に学習させ、結果を平均化して主に分散を抑えます。
ブースティングは前のモデルが間違えた例を次のモデルが補うように逐次学習し、弱いモデルを積み重ねます。勾配ブースティングやXGBoostなどが代表例です。ブースティングが常に優れるわけではなく、調整のしやすさ、学習時間、ノイズへの感度、必要な説明性を含めて選びます。
まとめ
バギングとは、ブートストラップ標本で複数のモデルを学習し、分類なら多数決、回帰なら平均などで予測を統合する手法です。データの違いから生まれる多様な判断を組み合わせ、単一モデルのばらつきを抑えます。
ランダムフォレストは、決定木のバギングに特徴量候補のランダム選択を加えたアルゴリズムです。表形式データで扱いやすく高い予測性能を得やすい一方、森全体の解釈、計算量、外挿、クラス不均衡、特徴量重要度の読み方には注意が必要です。まず単一決定木と比較すると、多様性を加える効果を理解しやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年7月11日 | 両手法の比較、OOB評価、不得意なケースを追記 |