非階層的クラスタリング:データの自動分類

AIの初心者
先生、「非階層的クラスタリング」って、グループ分けの良さを決めるやり方を最初に決めて、それを繰り返し計算することで、一番良いグループ分けを見つける方法ですよね?でも、具体的にどんなふうに計算していくのかがよくわからないんです。

AI専門家
そうだね。良いところに気がついたね。例えば、いくつかのデータがあったとします。まず、適当にグループを分けてみます。次に、それぞれのデータが、自分のグループの真ん中あたりにどれくらい近いかを計算します。すべてのデータが、自分のグループの真ん中に近ければ近いほど、良いグループ分けと言えます。この「近さ」を全部足し合わせたものが「グループ分けの良さ」になるんだ。これを繰り返すことで最適なグループ分けを見つけるのが非階層的クラスタリングだよ。
AIの初心者
なるほど。データがグループの真ん中に近いかどうかでグループ分けの良さが決まるんですね。でも、最初のグループ分けが悪いと、うまくいかないんじゃないですか?
AI専門家
良い質問だね。その通りで、最初のグループ分けによって結果が変わることがあるんだ。だから、何度か最初のグループ分けを変えて計算を繰り返したり、計算方法を工夫したりすることで、より良いグループ分けを見つけようとするんだよ。
非階層的クラスタリングとは。
コンピュータの知能に関する言葉で、『階層を作らないで集団に分けること』について説明します。これは、集団分けの良し悪さを数値で表す式を決めて、何度も計算を繰り返すことで、一番良い分け方を見つける方法です。
はじめに

非階層的クラスタリングとは、データの集まりをいくつかのグループ(集団)に分類する手法で、データ分析において重要な役割を担っています。階層的な分類とは異なり、あらかじめグループの数を決めて分類を行います。つまり、データを木構造のように階層的に分類していくのではなく、平坦な構造でグループ分けを行います。この手法は、近年のデータ量の増加に伴い、その重要性を増しています。膨大なデータを扱う現代社会において、データの持つ特性を理解し、適切に分類することは、企業の経営判断や科学的な新発見に不可欠です。非階層的クラスタリングは、データ同士の類似度に基づいて自動的に集団分けを行うことで、データの構造を明らかにして、隠れた法則性を見つけるのに役立ちます。
具体的には、まず分類したいデータの数を決めます。次に、それぞれのデータがどのグループに属するかを計算によって求めます。この計算では、データ間の類似度を測る尺度を用いて、似ているデータは同じグループに、似ていないデータは異なるグループに割り当てられます。この処理を繰り返すことで、最終的に最適なグループ分けが得られます。
非階層的クラスタリングの利点の一つは、大量のデータを効率的に処理できることです。階層的な分類と比べて計算量が少なく、大規模なデータセットにも適用できます。また、グループの数をあらかじめ指定できるため、分析の目的やデータの特性に合わせて柔軟に調整できる点もメリットです。
この手法は、様々な分野で応用されています。例えば、販売促進活動においては、顧客を購買行動の類似性に基づいてグループ分けすることで、効果的な販売戦略を立てることができます。医療分野では、患者の症状や検査データに基づいてグループ分けすることで、病気の診断や治療方針の決定に役立ちます。画像認識の分野では、画像の特徴に基づいてグループ分けすることで、画像の分類や検索を効率的に行うことができます。このように、非階層的クラスタリングは、データ分析を通して様々な分野で課題解決に貢献しています。
| 項目 | 説明 |
|---|---|
| 定義 | データをあらかじめ決めた数のグループに分類する手法。階層構造を持たない平坦な分類。 |
| 目的 | データの特性を理解し、隠れた法則性を見つける。 |
| 手順 | 1. 分類したいデータの数を決める。 2. データ間の類似度に基づいて、各データをグループに割り当てる。 3. この処理を繰り返して最適なグループ分けを行う。 |
| 利点 |
|
| 応用分野 |
|
手法の概要

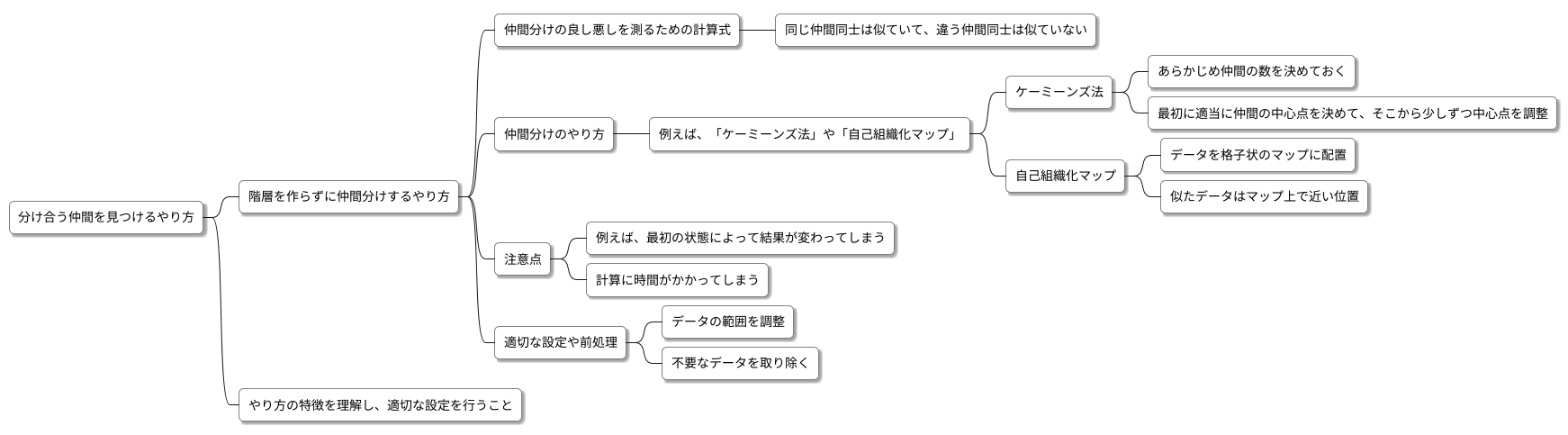
分け合う仲間を見つけるやり方について、詳しく説明します。階層を作らずに仲間分けするやり方は、仲間分けの良し悪しを測るための計算式を使います。この計算式は、同じ仲間同士は似ていて、違う仲間同士は似ていないほど、良い仲間分けだと判断するようにできています。
具体的には、まず仲間分けの良し悪しを測る計算式を決めます。この計算式は、仲間内の似ている度合いと、仲間同士の似ていない度合いを組み合わせて作られます。目指すのは、仲間内はできるだけ似ていて、仲間同士はできるだけ似ていない状態です。この計算式の値が最も高くなる、あるいは最も低くなるように、データを仲間分けしていきます。
仲間分けのやり方には、色々な種類があります。例えば、「ケーミーンズ法」や「自己組織化マップ」などです。それぞれに得意な点、不得意な点があります。「ケーミーンズ法」は、あらかじめ仲間の数を決めておく必要があります。最初に適当に仲間の中心点を決めて、そこから少しずつ中心点を調整していくことで、仲間分けを完成させます。一方、「自己組織化マップ」は、データを格子状のマップに配置し、似たデータはマップ上で近い位置に配置されるように学習することで仲間分けを行います。
これらのやり方には、いくつか注意点があります。例えば、最初の状態によって結果が変わってしまうことや、計算に時間がかかってしまうことなどです。しかし、適切な設定や前処理を行うことで、精度の高い仲間分けを行うことができます。前処理としては、例えばデータの範囲を調整したり、不要なデータを取り除いたりすることが挙げられます。このように、やり方の特徴を理解し、適切な設定を行うことが重要です。
代表的な手法:k-means法

「ケー平均法」は、階層構造を作らないタイプの集団分け手法の中でも、最もよく使われている方法の一つです。この手法は、データの集まりを幾つかのグループに分けることを目的としています。分けたいグループの数を最初に決めておくことが必要です。
ケー平均法では、各グループの中心点となる「重心」を計算します。そして、それぞれのデータが、どの重心に一番近いかを調べ、一番近い重心を持つグループに属させます。この時、重心の位置は、グループに属するデータの平均の位置で計算されます。
データのグループ分けと重心の計算を何度も繰り返すことで、最終的に、データがバランスよくグループ分けされた状態になります。具体的には、全てのデータが、自分自身に一番近い重心のグループに属するようになった時点で計算を終了します。
ケー平均法の良い点は計算が比較的簡単で、処理速度が速いことです。そのため、たくさんのデータを含む大規模なデータに対しても、現実的な時間で計算を行うことができます。
しかし、欠点として、最初に設定する重心の位置によって、最終的なグループ分けの結果が変わってしまうことがあります。最初にランダムに重心の位置を決めるため、たまたま偏った位置に重心が配置されると、望ましい結果が得られない場合があります。この欠点を補うためには、異なる初期値で計算を何度も繰り返すことが大切です。そして、得られた結果の中から、最も良いものを選ぶことで、初期値の影響を減らすことができます。
例えば、顧客データを購買履歴に基づいてグループ分けする場合に、ケー平均法を使うことができます。この場合、グループの数は3つに設定し、顧客を購買傾向に基づいて3つのグループに分けます。そして、各グループに適した販売戦略を立てることで、売上向上につなげることができます。
このように、ケー平均法は様々な分野で活用できる、便利で強力な手法です。
| 項目 | 内容 |
|---|---|
| 手法名 | ケー平均法 |
| 目的 | データの集まりを幾つかのグループに分ける |
| グループ数 | 最初に決めておく必要がある |
| 重心 | 各グループの中心点 |
| データの所属 | 一番近い重心のグループに属する |
| 重心の計算 | グループに属するデータの平均の位置 |
| 計算終了条件 | 全てのデータが、自分自身に一番近い重心のグループに属するようになった時点 |
| メリット | 計算が比較的簡単、処理速度が速い、大規模データへの適用可能 |
| デメリット | 初期重心の位置によって結果が変わる |
| デメリット対策 | 異なる初期値で計算を何度も繰り返す、最も良い結果を選ぶ |
| 活用例 | 顧客データを購買履歴に基づいてグループ分け |
自己組織化マップ

自己組織化マップとは、人間の脳の神経回路網を模倣した情報処理モデルである、ニューラルネットワークの一種です。これは、高次元、つまりたくさんの特徴を持つデータを取り扱い、それを低次元、例えば二次元平面のような分かりやすい空間に配置することで、データの特徴や関係性を視覚的に把握できるようにする手法です。
自己組織化マップの最大の特徴は、データの持つ構造や繋がりを維持したまま、次元を縮減できる点にあります。たくさんの情報が詰まった複雑なデータを、重要な情報を失うことなく、単純化された形で表現できるのです。この過程で用いられるのが、競合学習と呼ばれる学習方法です。複数のニューロンが競い合い、入力データに最も近いニューロンとその周辺のニューロンだけが反応し、学習していきます。この学習方法のおかげで、似た特徴を持つデータはマップ上で近くに配置され、異なる特徴を持つデータは遠くへ配置されるようになります。このようにして、データの元の繋がりを保ったまま、視覚的に分かりやすいマップが作成されます。
よく似た手法であるk-means法では、データをいくつのグループに分けたいかをあらかじめ指定する必要がありますが、自己組織化マップはそうした事前の指定が不要です。データの構造を自ら学習し、最適な形でマップを作成してくれるため、データ分析の初期段階において特に有用です。また、得られたマップは視覚的に理解しやすいため、データの全体像を把握したり、隠れたパターンを発見したりするのに役立ちます。例えば、顧客データの分析に用いれば、顧客をいくつかのグループに分類し、それぞれのグループの特徴を把握することで、より効果的な販売戦略を立てることができるでしょう。また、画像認識や異常検知といった分野でも、その優れた可視化能力と学習能力が活かされています。
| 項目 | 説明 |
|---|---|
| 定義 | 人間の脳の神経回路網を模倣したニューラルネットワークの一種。高次元データの次元を縮減し、2次元平面のような低次元空間に配置することで、データの特徴や関係性を視覚的に把握できるようにする手法。 |
| 特徴 | データの構造や繋がりを維持したまま次元縮減が可能。競合学習により、似た特徴のデータは近くに、異なる特徴のデータは遠くに配置されるマップを作成。事前のグループ分け指定が不要(k-means法との違い)。視覚的に理解しやすいマップを作成。 |
| 学習方法 | 競合学習:入力データに最も近いニューロンとその周辺ニューロンが反応・学習。 |
| メリット | データの全体像把握、隠れたパターンの発見。初期段階のデータ分析に有用。 |
| 応用例 | 顧客データ分析による販売戦略立案、画像認識、異常検知。 |
利点と欠点

非階層的集団分けは、階層構造を作らずに集団を作る方法で、たくさんの情報を効率よく似た者同士でまとめる長所があります。特に、ケーミーンズ法などは計算が速いため、莫大なデータにも対応できる点が優れています。この方法は、あらかじめ集団の数を決めて、それぞれの集団の中心点を定め、データがどの集団の中心に近いかで集団分けを行います。このため、計算の手間が少なく、大規模なデータ分析に適しています。また、データの視覚化に役立つ自己組織化マップも非階層的集団分けの一種です。これは、データを二次元のマップ上に配置することで、データの分布や類似性を視覚的に把握することができます。
しかし、非階層的集団分けにはいくつか注意点もあります。まず、集団の数を事前に決める必要がある点が挙げられます。適切な集団数を事前に知るのは難しく、分析者の経験や知識に頼ることになります。集団の数を誤ると、本来は異なる集団に属するデータが同じ集団に分類されたり、逆に同じ集団に属するデータが異なる集団に分類されたりする可能性があります。また、初期値によって結果が変わるという欠点もあります。ケーミーンズ法では、集団の中心点をランダムに設定するため、初期値の設定によって最終的な結果が異なる場合があります。同じデータでも、計算を繰り返すと異なる結果が得られる可能性があるため、安定した結果を得るためには、複数回の計算を行い、結果を比較する必要があります。さらに、データの前処理や結果の解釈にも注意が必要です。データに外れ値やノイズが含まれる場合は、前処理によってそれらを除去する必要があります。また、得られた集団分けの結果を解釈する際には、データの特性や分析の目的を考慮する必要があります。どの方法も完璧ではなく、データの性質や分析の目的に合わせて適切な方法を選ぶことが重要です。
| 項目 | 説明 |
|---|---|
| 手法 | 非階層的集団分け |
| 長所 |
|
| 方法 | あらかじめ集団数を決め、中心点を定め、データと中心点の近さで分類 |
| 注意点 |
|
| その他 | データの性質や分析の目的に合わせて適切な方法を選ぶことが重要 |
まとめ

データの集まりをいくつかのグループに分ける作業は、全体を理解する上でとても役に立ちます。このような作業は「非階層的クラスタリング」と呼ばれ、データ分析の強力な道具として使われています。非階層的クラスタリングには様々な方法があり、それぞれに特徴があるので、データの性質や分析の目的に合った方法を選ぶことが大切です。適切な方法を選ぶことで、データから価値ある情報を見つけ出し、新しい発見に繋がるのです。
非階層的クラスタリングの中でも、「K平均法」はよく知られた方法の一つです。この方法は、あらかじめグループの数を決めておき、データ同士の似ている度合いを計算しながら、それぞれのデータが属するグループを決めていきます。計算が単純で速いため、大規模なデータにも対応できるのが利点です。しかし、最初にグループの数を決める必要があるため、適切な数を決めるための工夫が必要です。
一方、「自己組織化マップ」という方法も、非階層的クラスタリングでよく用いられます。この方法は、データの関係性を視覚的に分かりやすく表現できるのが特徴です。高次元のデータを二次元のマップ上に配置することで、データの分布やグループの繋がりを視覚的に把握できます。自己組織化マップは、データの可視化に優れているため、データの全体像を掴んだり、隠れた関係性を見つけるのに役立ちます。
このように、非階層的クラスタリングには様々な方法があり、それぞれに長所と短所があります。K平均法は速くて大規模データにも対応できる反面、グループの数をあらかじめ決める必要があります。自己組織化マップはデータの関係性を視覚的に理解するのに役立ちますが、高次元データの表現には限界がある場合もあります。これらの方法をうまく使い分けることで、データ分析をより効果的に行うことができます。非階層的クラスタリングは、データ分析において重要な手法であり、今後の更なる発展にも期待が持てます。
| 手法 | 説明 | 長所 | 短所 |
|---|---|---|---|
| K平均法 | あらかじめグループ数を決め、データの類似度に基づいてグループ分けを行う。 | 計算が単純で速く、大規模データに対応可能。 | 適切なグループ数を事前に決定する必要がある。 |
| 自己組織化マップ | データの関係性を視覚的に表現する二次元マップを作成。 | データの分布やグループの繋がりを視覚的に把握できる。 | 高次元データの表現に限界がある場合も。 |