感度:機械学習における重要指標

AIの初心者
「Sensitivity」ってどういう意味ですか?機械学習の評価でよく出てきますが、少し難しく感じます。

AI専門家
簡単に言うと「本来見つけるべきものを、どれだけ見つけられたか」を表す指標だよ。病気の検査なら、病気の人を正しく陽性と判定できた割合だね。
AIの初心者
つまり、Sensitivityが高いほど見落としが少ないということですか?
AI専門家
その通り。1.0に近いほど、本当に陽性のものを陰性と誤って判断する可能性が低くなる。ただし、他の指標とのバランスも大切だよ。
Sensitivityとは。
統計学や機械学習で使われる「感度」は、実際に陽性である対象をどれだけ正しく陽性と判定できたかを示す評価指標です。値は0から1の範囲で表され、1に近いほど陽性の見落としが少ないことを意味します。
感度とは
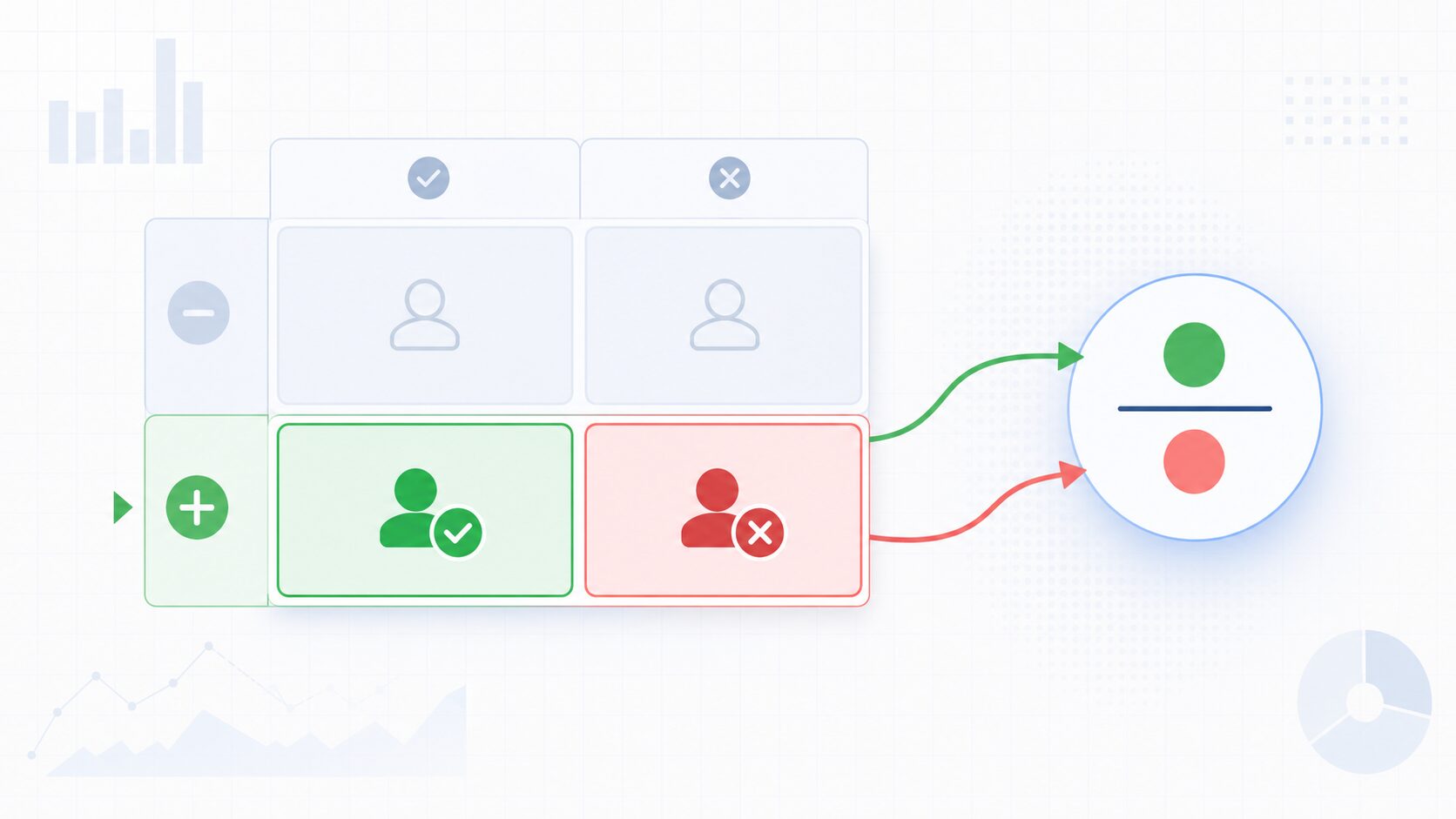
感度とは、実際に陽性であるもののうち、モデルが正しく陽性と予測できた割合を表す指標です。英語ではSensitivityと呼ばれ、再現率やRecallと近い意味で使われることもあります。
たとえば病気の検査では、実際に病気である人を「陽性」と正しく判定できた割合が感度です。不正検知であれば、実際に不正である取引をどれだけ不正として検出できたかを表します。
感度は、特に見落としが大きな損失につながる場面で重視されます。病気の診断で陽性者を見逃すと治療の遅れにつながり、不正検知で不正取引を見逃すと金銭的な被害が広がる可能性があります。
値は0から1で表され、1に近いほど高い感度です。感度が0.9であれば、実際に陽性である対象のうち90%を検出できている、という読み方になります。
| 指標名 | 意味 | 範囲 | 重視される場面 |
|---|---|---|---|
| 感度 | 実際に陽性であるものを正しく陽性と予測できた割合 | 0から1 | 陽性の見落としを減らしたい場面 |
感度の計算方法
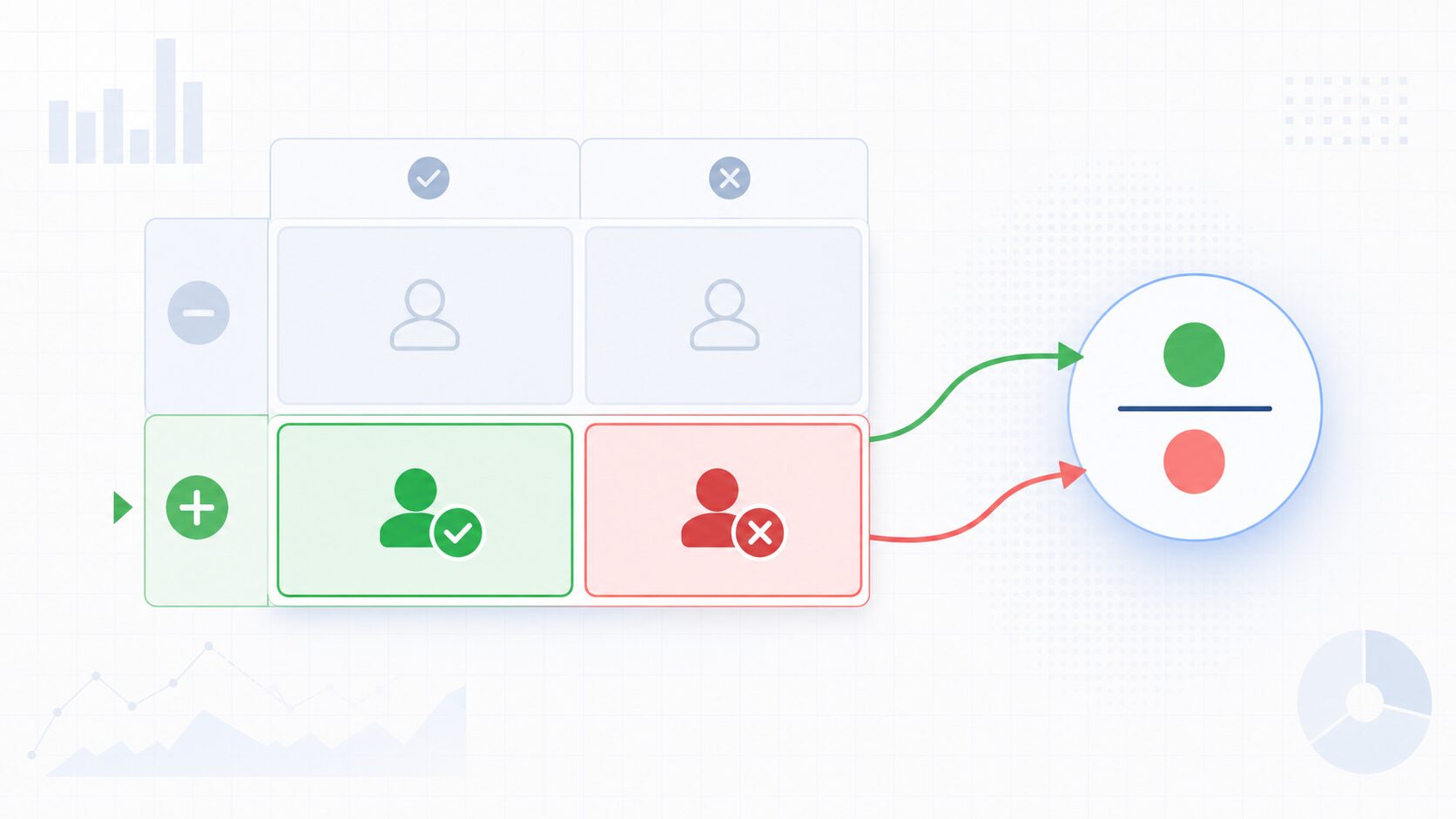
感度を計算するには、まず混同行列の考え方を押さえる必要があります。混同行列は、実際の結果とモデルの予測結果を比べて、予測の当たり外れを整理する表です。
感度で特に重要なのは、真陽性と偽陰性です。真陽性は、実際に陽性で、モデルも陽性と正しく予測した場合です。偽陰性は、実際は陽性なのに、モデルが陰性と誤って予測した場合です。
計算式は次の通りです。
| 指標 | 計算式 | 意味 |
|---|---|---|
| 感度 | 真陽性 ÷ (真陽性 + 偽陰性) | 実際に陽性である対象のうち、正しく陽性と判定できた割合 |
たとえば、実際に病気である100人を検査し、そのうち90人を陽性、10人を陰性と判定したとします。この場合、真陽性は90、偽陰性は10です。感度は 90 ÷ (90 + 10) = 0.9 となります。
この例では、検査が本当に病気である人の90%を見つけられていることになります。逆に言えば、10%は見落としているため、用途によっては改善が必要です。
| 要素 | 説明 | 病気の検査での例 |
|---|---|---|
| 真陽性 | 実際に陽性で、予測も陽性 | 病気の人を病気と判定した |
| 偽陽性 | 実際は陰性だが、予測は陽性 | 健康な人を病気と判定した |
| 真陰性 | 実際に陰性で、予測も陰性 | 健康な人を健康と判定した |
| 偽陰性 | 実際は陽性だが、予測は陰性 | 病気の人を健康と判定した |
特異度・精度との関係

機械学習モデルを評価するときは、感度だけを見ればよいわけではありません。感度は「陽性の見落とし」に注目する指標ですが、モデルには別の失敗もあります。
たとえば、実際は陰性なのに陽性と判定してしまう誤りがあります。この誤りを抑える観点では、特異度が重要です。特異度は、実際に陰性であるものを正しく陰性と判定できた割合を示します。
また、全体としてどれだけ正しく予測できたかを見る指標が精度です。ただし、陽性と陰性の数が大きく偏っているデータでは、精度だけを見るとモデルの問題を見落とすことがあります。
| 指標 | 見るポイント | 病気の診断での意味 |
|---|---|---|
| 感度 | 陽性をどれだけ見つけられたか | 病気の人を病気と判定できた割合 |
| 特異度 | 陰性をどれだけ正しく除外できたか | 健康な人を健康と判定できた割合 |
| 精度 | 全体でどれだけ正解したか | 検査結果全体の正解率 |
感度を高めると、陽性と判定する範囲が広がり、偽陽性が増える場合があります。逆に、偽陽性を減らそうとすると、今度は偽陰性が増えて感度が下がる場合があります。そのため、目的に応じてどの指標を重視するかを決めることが大切です。
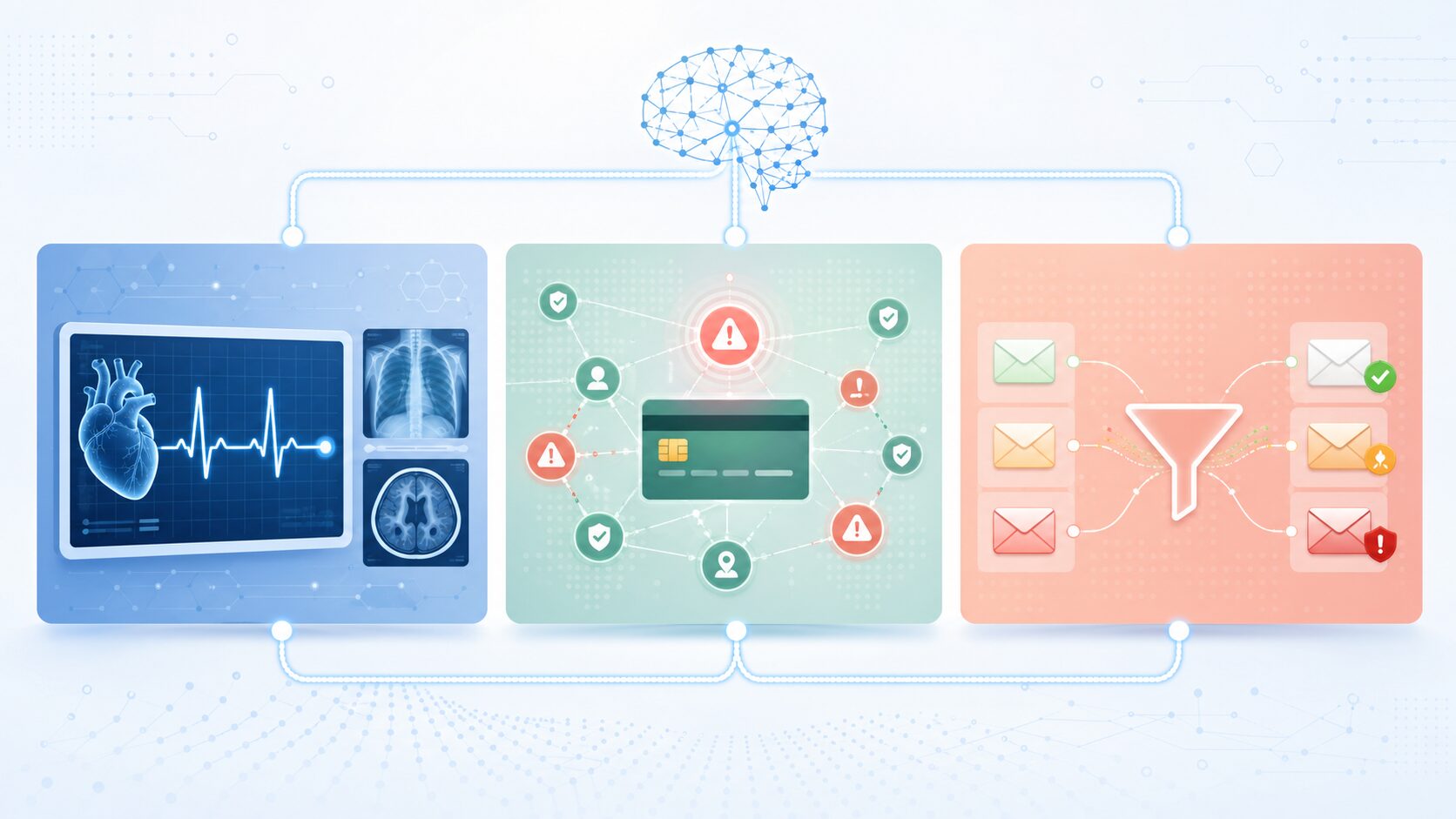
感度が重視される応用事例

感度は、見逃しが重大な結果につながる分野で特に重視されます。代表的な例は、医療診断、不正検知、セキュリティ、迷惑メール判別などです。
医療診断では、病気の可能性がある人を早期に見つけることが重要です。感度の高い検査は、実際に病気である人を陰性と判定してしまうリスクを減らします。早期発見が治療成績に影響する病気では、特に重要な考え方です。
不正検知では、不正取引や不正アクセスを見逃すと、被害が拡大する可能性があります。感度の高いモデルは、疑わしい取引をできるだけ拾い上げるため、初期検知の仕組みに向いています。
迷惑メール判別でも感度の考え方は使われます。ただし、何を「陽性」と定義するかによって注意点が変わります。迷惑メールを陽性とする場合は迷惑メールの見逃しを減らす指標になり、重要メールを陽性とする場合は重要メールを残す力を見る指標になります。
| 分野 | 感度を重視する理由 | 具体例 |
|---|---|---|
| 医療診断 | 病気の見落としを減らすため | がん検査や感染症検査 |
| 不正検知 | 不正行為の見逃しを減らすため | クレジットカードの不正利用検知 |
| セキュリティ | 攻撃や侵入の兆候を拾うため | 不正ログイン検知 |
| メール判別 | 定義した陽性対象の見逃しを減らすため | 迷惑メールや重要メールの分類 |
感度を高める方法
感度を高めるには、単にモデルを複雑にするだけでは不十分です。データ、特徴量、判定しきい値、評価方法を目的に合わせて見直す必要があります。
まず重要なのは、陽性データを十分に集めることです。陽性の事例が少なすぎると、モデルは陽性の特徴を学びにくくなります。医療や不正検知のように陽性が少ない分野では、データの偏りに注意が必要です。
次に、陽性と陰性を区別しやすい特徴量を設計します。たとえば不正検知では、取引金額、利用場所、時間帯、過去の利用傾向などが判断材料になります。適切な特徴量は、モデルが陽性を見つける助けになります。
また、分類のしきい値を調整することも有効です。多くのモデルは、陽性である確率を出力し、その確率が一定以上なら陽性と判定します。しきい値を下げると陽性と判定される対象が増え、感度が上がることがあります。ただし、偽陽性も増えやすいため、特異度や運用コストとのバランスを確認する必要があります。
感度は「高ければ常に正解」という指標ではなく、見逃しのリスクと誤検知のコストを比べながら調整する指標です。利用目的を明確にしたうえで、他の評価指標と合わせて判断しましょう。
| 方法 | 狙い | 注意点 |
|---|---|---|
| 陽性データを増やす | 陽性の特徴を学びやすくする | データ品質や偏りを確認する |
| 特徴量を見直す | 陽性と陰性の違いを捉えやすくする | 過学習に注意する |
| しきい値を調整する | 陽性判定の範囲を変える | 偽陽性が増える可能性がある |
| 複数指標で評価する | 感度だけに偏らず判断する | 運用目的に合う基準を決める |
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月2日 | 初回公開 |
| 2026年4月29日 | 感度の定義、計算方法、特異度・精度との関係、応用事例、改善方法を初心者向けに再構成 |