アルゴリズム
アルゴリズム SVM入門:マージン最大化で高精度分類
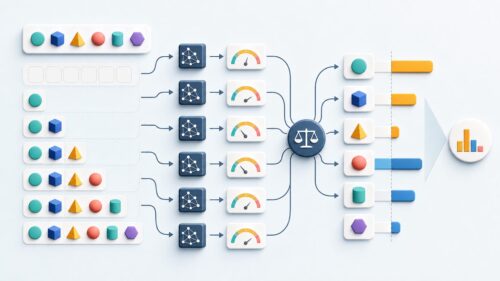
サポートベクターマシン(略して「エスブイエム」)は、教師あり学習という手法を使った強力な機械学習の手法です。ものの種類分けや数値の予測といった作業に役立ちます。このエスブイエムは、データの集まりを最もよく仕分ける境界線を見つけることで、高い精度で予測を行います。
具体的に説明すると、例えば、りんご」と「みかん」を分ける問題を考えましょう。エスブイエムは、この二つの果物の間の境界線をできるだけ広く取るようにします。この境界線と果物との間の距離を「余白(読み方よはく)」と言います。この余白を最大にすることで、未知の果物、例えば少し変わった形のりんごやみかんが出てきても、高い精度で分類できるようになります。これが、エスブイエムの大きな特徴です。
この余白の最大化は、新しいデータに対しても高い予測精度を保つために非常に大切です。学習に用いたデータだけでなく、見たことのないデータに対してもきちんと対応できる能力のことを「汎化性能(読み方はんかせいのう)」と言いますが、エスブイエムはこの汎化性能が高いという利点があります。
例えば、様々な大きさや色の「りんご」と「みかん」をエスブイエムに学習させたとします。すると、エスブイエムは「りんご」と「みかん」を見分ける理想的な境界線を学習します。この境界線は、多少いびつな形のりんごや、色が薄いみかんが出てきても、正しく分類できるような位置に引かれます。このように、エスブイエムはデータの分類だけでなく、回帰分析と呼ばれる数値予測にも応用できる、強力で汎用的な手法です。