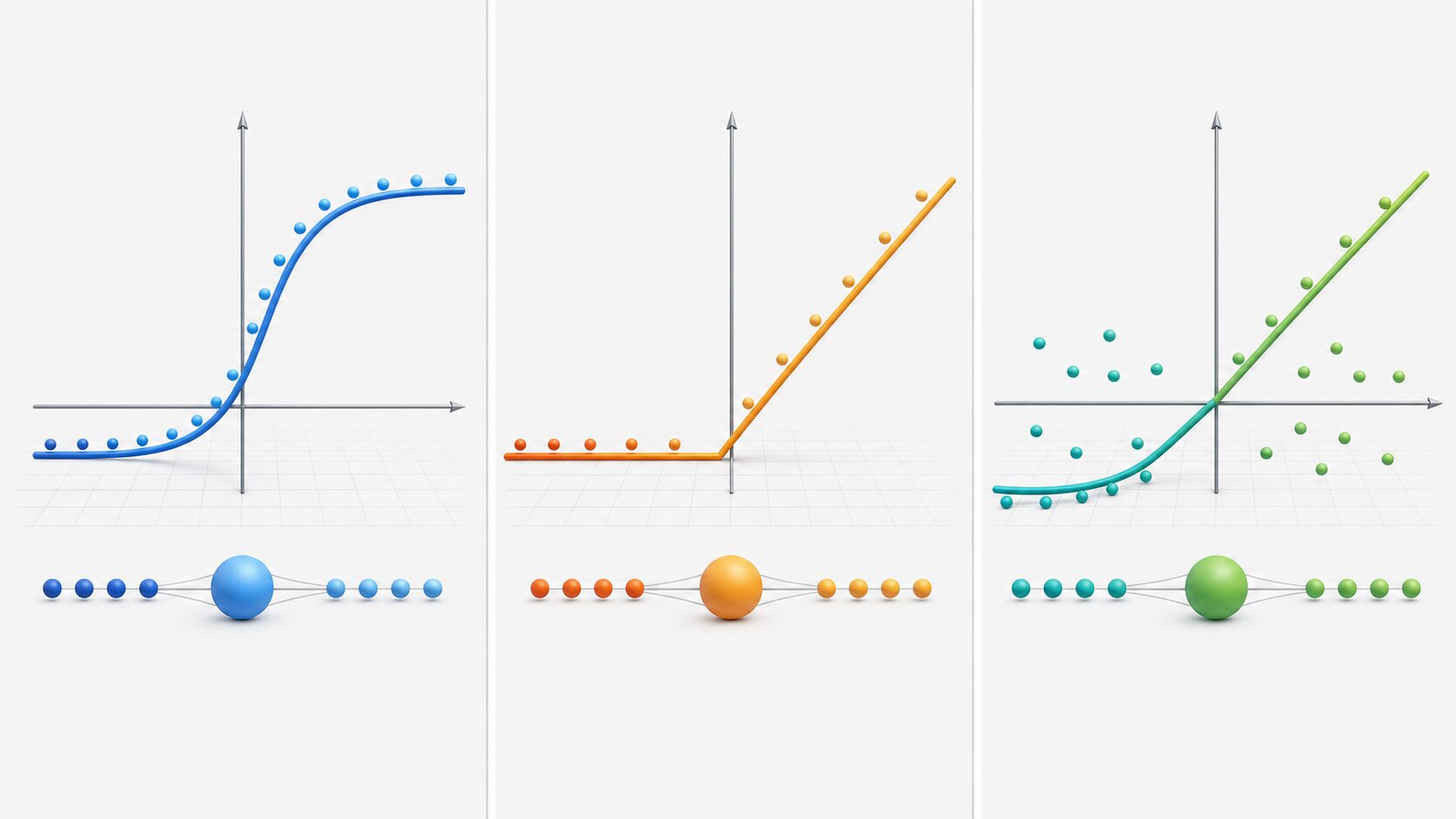
SELUとは?自己正規化する活性化関数の仕組みと使い方

AIの初心者
「SELU」って聞いたことがあるんですが、どんなものかよくわかりません。何に使う関数なんですか?

AI専門家
SELUは、Scaled Exponential Linear Unitの略で、ニューラルネットワークの学習に使われる活性化関数の一つだよ。人工ニューロンの出力を調整する役割を持っているんだ。
AIの初心者
活性化関数なんですね。ReLUやシグモイド関数とは何が違うのでしょうか?
AI専門家
大きな特徴は、層を通る値の分布を自然に安定させる「自己正規化」だね。深いネットワークで学習を崩れにくくするために設計された関数なんだ。
SELUとは。
SELUは、深層学習で使われる活性化関数の一つです。この記事では、SELUの意味、自己正規化の仕組み、ReLUなどとの違い、実際に使うときの注意点を順に整理します。
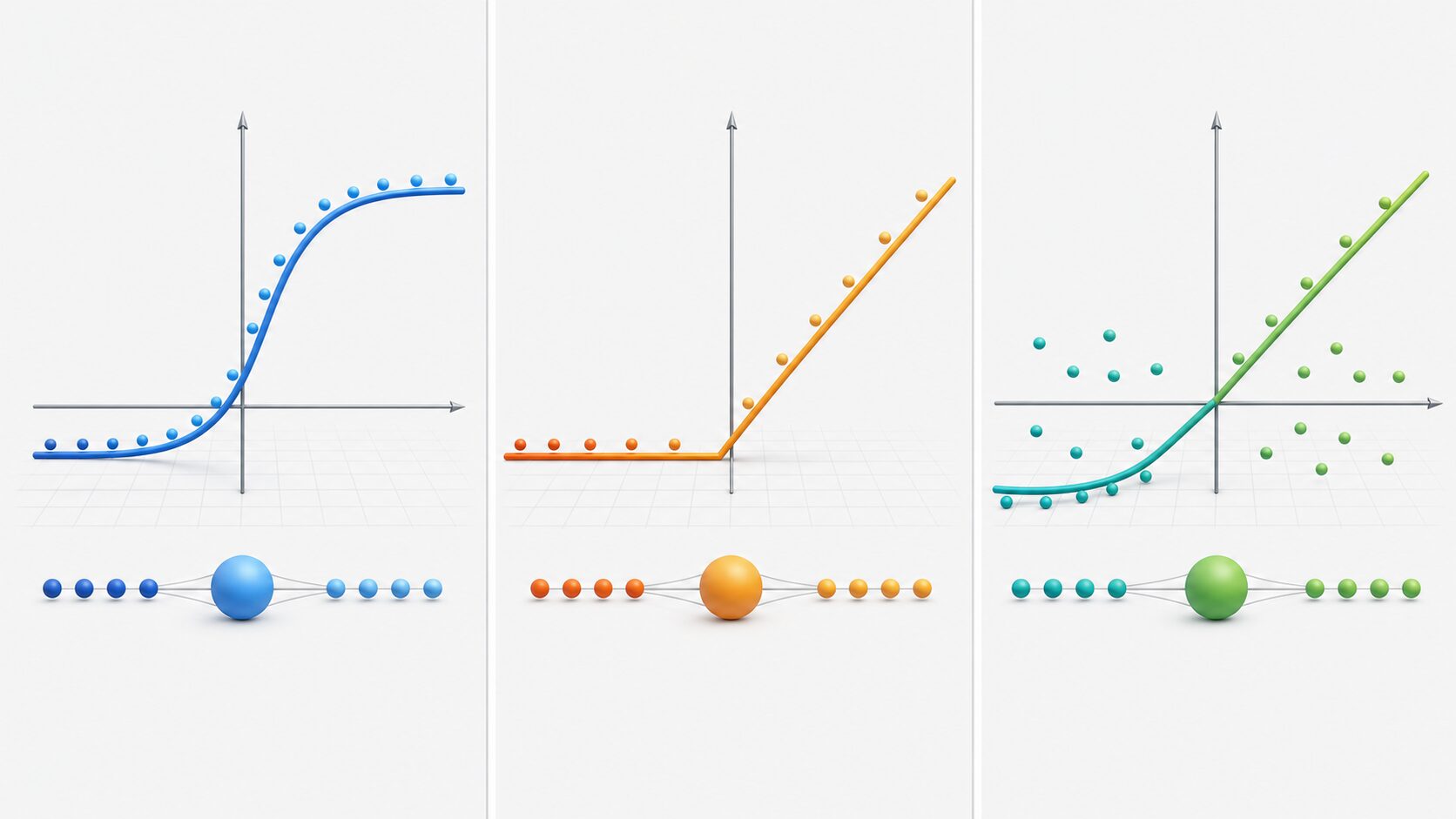
SELUは「セルー」と読み、正式には Scaled Exponential Linear Unit と呼ばれます。ニューラルネットワークの各ニューロンで使われる活性化関数で、入力をそのまま次へ流すのではなく、学習しやすい形に変換して出力します。
特徴は、名前の通り単なる指数線形ユニットではなく、スケール調整された形になっていることです。この調整により、一定の条件を満たすネットワークでは、層を通る値の平均や分散が極端に崩れにくくなります。この性質が 自己正規化 と呼ばれます。
活性化関数とは何をするものか
ニューラルネットワークは、多数の人工ニューロンを層状につないだ仕組みです。それぞれのニューロンは、前の層から受け取った値に重みを掛け、足し合わせ、その結果を次の層へ渡します。このとき、単なる足し算だけで層を重ねると、ネットワーク全体は複雑な関係を十分に表現できません。
そこで使われるのが活性化関数です。活性化関数は、ニューロンの計算結果に非線形な変換を加えます。これにより、画像、文章、音声、表形式データのような複雑なパターンをモデルが学習できるようになります。
代表的な活性化関数には、シグモイド関数、tanh、ReLU、Leaky ReLU、ELU、GELUなどがあります。SELUもその一つですが、特に 深いネットワークで内部の値の分布を安定させる ことを意識して設計されています。
SELUとは何か
SELUは、ELUをもとにしつつ、出力に特定の係数を掛けることで分布の安定化を狙った活性化関数です。入力が正の値のときはほぼ直線的に値を通し、入力が0以下のときは指数関数を使って滑らかに負の値へ近づけます。
ReLUでは、入力が0以下のとき出力が0になります。そのため計算は簡単ですが、負の領域の情報が切り捨てられます。SELUは負の領域も完全には消さず、滑らかな曲線として扱います。この性質により、出力の平均が一方向へ偏りすぎるのを抑えやすくなります。
ただし、SELUは「入れれば必ず精度が上がる関数」ではありません。自己正規化が働くには、入力データの標準化、適切な重み初期化、ネットワーク構造、Dropoutの扱いなどが関係します。SELUの強みは、条件が合ったときに 正規化層に頼りすぎず学習を安定させやすい 点にあります。
自己正規化が学習を安定させる理由

深いニューラルネットワークでは、層を進むたびに値の分布が大きくずれることがあります。ある層では値がどんどん大きくなり、別の層ではほとんど変化しないほど小さくなる、といった状態です。こうした不安定さは、勾配消失や勾配爆発の原因になります。
勾配消失とは、学習時に誤差を後ろへ伝える勾配が小さくなりすぎ、前の層まで十分に学習信号が届かなくなる現象です。反対に勾配爆発は、勾配が大きくなりすぎて重みの更新が不安定になる現象です。どちらも、深いモデルの学習を難しくします。
SELUの自己正規化は、各層の出力が平均0、分散1に近い状態へ戻りやすくなるように設計された性質です。層を重ねても値の分布が極端に広がったり片寄ったりしにくいため、学習が安定しやすくなります。
イメージとしては、ネットワーク内部を流れる値が毎回ばらばらなスケールになるのではなく、一定の幅に収まりながら次の層へ進む状態です。これにより、最適化が進みやすくなり、深い全結合ネットワークなどで効果が期待されます。
SELU関数の式と読み方
SELUは、入力値が正か負かによって計算が分かれる関数です。標準的には、次のように表されます。
\(\operatorname{SELU}(x)=\lambda
\begin{cases}
x & (x>0)\\
\alpha(e^x-1) & (x\leq 0)
\end{cases}
\)
ここで、\lambda は全体のスケールを調整する係数、\alpha は負の領域の曲線を調整する係数です。よく使われる値は、おおよそ \lambda=1.0507、\alpha=1.6733 です。
入力が正の場合、SELUは値をほぼそのまま伸ばします。一方、入力が0以下の場合は、指数関数によって滑らかな負の値を出します。負の値を完全に0へ切り捨てないため、出力の平均を中央付近へ戻す働きに貢献します。
この式だけを見ると複雑に感じるかもしれませんが、目的は明確です。ネットワークの中を流れる値が大きく崩れないよう、正の領域と負の領域のバランスを取ることです。SELUの係数は、この自己正規化が成り立ちやすいよう理論的に選ばれています。
ReLU・シグモイド関数との違い
SELUを理解するときは、よく使われるシグモイド関数やReLUと比べると特徴が見えやすくなります。
| 活性化関数 | 主な特徴 | 注意点 |
|---|---|---|
| シグモイド関数 | 出力を0から1の範囲に収めるため、確率のような値を扱いやすい | 入力が大きい領域で変化が小さくなり、勾配消失が起きやすい |
| ReLU | 正の値をそのまま通し、0以下を0にするため計算が軽い | 負の値の情報が失われ、ニューロンが更新されにくくなる場合がある |
| SELU | 負の領域も滑らかに扱い、自己正規化によって分布を安定させやすい | 前提条件が合わないと期待した効果が出にくい |
ReLUは現在でも多くのモデルで使われる標準的な選択肢です。計算が軽く、畳み込みニューラルネットワークなどでも扱いやすいからです。一方、SELUは、特定の条件下で内部の分布を安定させることを狙う場合に候補になります。
重要なのは、SELUがReLUの完全な上位互換ではないという点です。モデルの種類、データの性質、正規化層の有無、Dropoutの使い方によって、適した活性化関数は変わります。実務では、SELUを使う理由を明確にしたうえで、検証データで比較することが大切です。
SELUが向いている場面
SELUは、深い全結合ニューラルネットワークのように、層を重ねることで内部の値の分布が崩れやすい場面で候補になります。特に、Batch Normalizationなどの正規化層を多用せずに学習を安定させたい場合、SELUの自己正規化は検討する価値があります。
表形式データを扱う多層パーセプトロン、特徴量を入力して分類や回帰を行うネットワーク、深いフィードフォワードネットワークなどでは、SELUの特性が役立つことがあります。画像認識や自然言語処理でも活性化関数として検討されることはありますが、近年の大規模モデルではアーキテクチャごとに標準的な活性化関数が決まっている場合も多く、単純な置き換えだけでは判断できません。
学習速度の面でも、内部の値が安定すれば最適化が進みやすくなります。勾配のスケールが乱れにくいことで、極端に小さい更新や大きすぎる更新を避けやすくなるためです。ただし、これは理論上の性質と実験上の傾向であり、実際の効果はデータセットと実装条件によって変わります。
使う前に知っておきたい注意点

SELUの自己正規化は便利な性質ですが、無条件に働くものではありません。まず、入力データは平均0、分散1に近い形へ標準化しておくことが重要です。入力のスケールが大きく乱れていると、層の内部で分布が安定しにくくなります。
重み初期化も重要です。SELUは、適切な初期化と組み合わせることで自己正規化の効果を発揮しやすくなります。実装ライブラリを使う場合でも、デフォルト設定がSELUに合っているとは限らないため、初期化方法を確認しましょう。
Dropoutを併用する場合は、通常のDropoutではなく AlphaDropout が使われます。通常のDropoutは出力分布を崩しやすく、SELUが保とうとする平均や分散に影響するためです。AlphaDropoutは、SELUの自己正規化を保ちやすいように設計されたDropoutです。
また、Batch NormalizationやLayer Normalizationと組み合わせる場合は、SELUの自己正規化と役割が重なることがあります。正規化層を入れるならSELUの利点が薄れる可能性もあるため、ReLU系の関数と比較しながら検証するのが現実的です。
SELUを学ぶときの確認ポイント
SELUを理解するうえで、最初に押さえたいのは「活性化関数の一種であること」と「自己正規化を狙って設計されていること」です。細かい式を暗記するよりも、まずは正の値を直線的に扱い、負の値を指数関数で滑らかに扱うことで、出力分布を安定させやすくしていると理解するとよいでしょう。
次に、ReLUやシグモイド関数との違いを整理します。シグモイドは出力範囲が限られるため勾配消失が起きやすく、ReLUは計算が軽い一方で負の値を0にします。SELUは負の領域も活用し、平均と分散を保ちやすいように調整されている点が違いです。
最後に、実装上の前提を確認します。入力の標準化、重み初期化、AlphaDropout、正規化層との関係を見落とすと、SELUを使っても期待通りの安定性が得られないことがあります。SELUは有力な選択肢ですが、最終的にはモデルとデータに合わせて検証する活性化関数です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月16日 | 式と比較表を補い、SELUの前提条件まで追える構成に更新 |