汎化性能とは?未知データに対応する力をわかりやすく解説

AIの初心者
「汎化性能」ってよく聞くんですけど、具体的にはどんな意味ですか?

AI専門家
簡単に言うと、初めて見るデータに対しても、きちんと判断できる能力のことです。たとえば、たくさんの猫の写真で学習したAIが、別の猫の写真を見ても「猫」と判断できるかどうかが関係します。
AIの初心者
学習したデータだけでなく、新しいデータにも対応できるかを見るんですね。なぜそこまで重要なんですか?
AI専門家
AIは実際に使われると、学習時とは少し違うデータに次々と出会います。だから、未知の状況でも安定して判断できる汎化性能が、実用的なAIには欠かせないのです。
汎化性能とは。
汎化性能とは、機械学習モデルが学習に使っていない未知データに対しても、適切に予測や分類を行える能力のことです。学習データで高い正答率を出すだけでは十分ではなく、訓練データとテストデータを分けて、実際に新しいデータへ対応できるかを確認することが大切です。
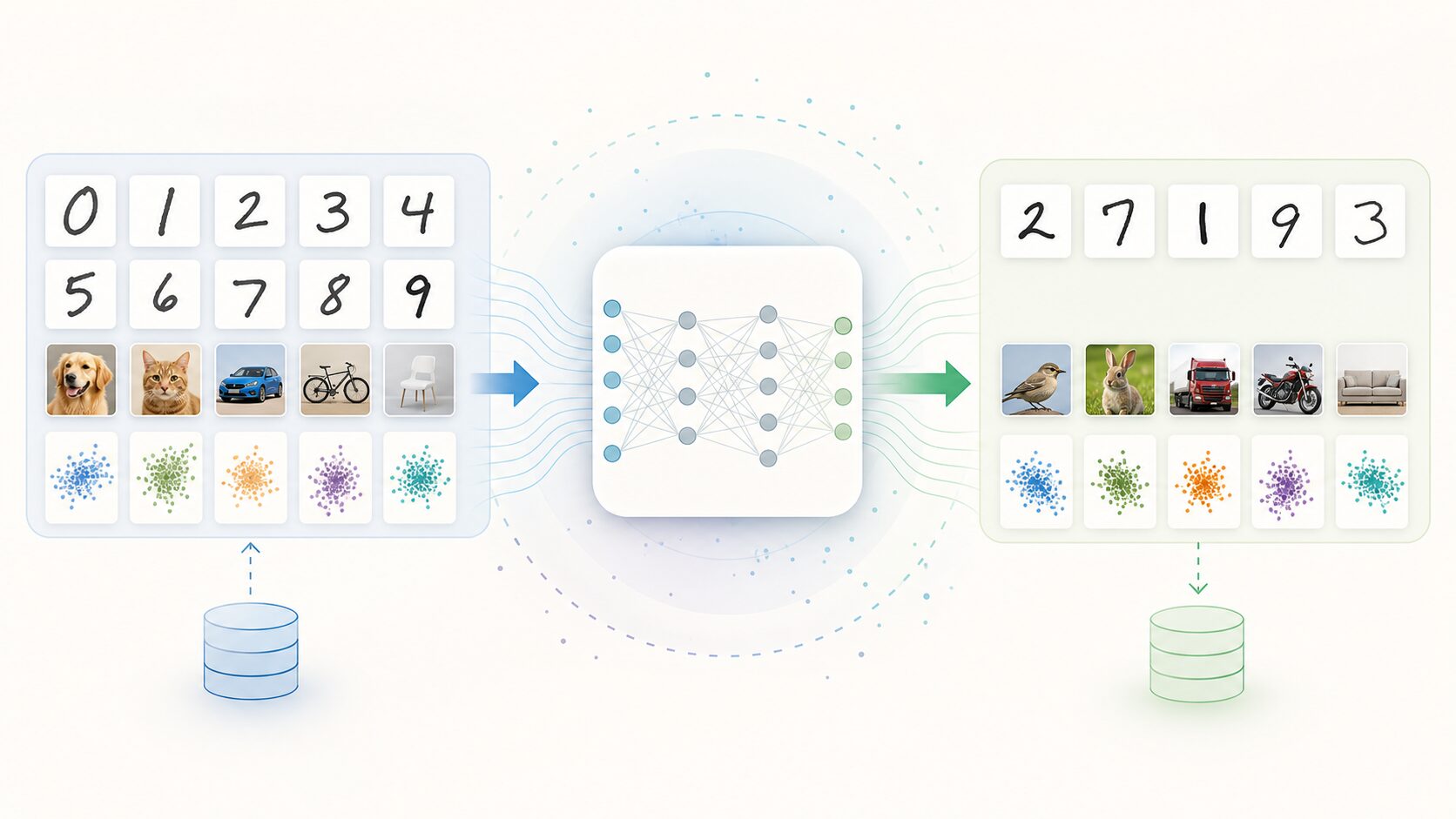
汎化性能とは
汎化性能とは、機械学習モデルが学習中に見ていないデータに対しても、正しく予測・分類できる能力を指します。英語では generalization performance と呼ばれ、AIや機械学習の実用性を考えるうえで中心になる考え方です。
たとえば、手書き数字を認識するモデルを考えてみましょう。学習データには多くの「0」から「9」までの画像が含まれています。モデルはその画像から、線の形、傾き、太さ、配置などの特徴を学びます。しかし、本当に重要なのは、学習に使った画像を当てられることではありません。まだ見たことのない筆跡の数字を見ても、正しく「これは3」「これは8」と判断できるかどうかです。
この違いは、学校の勉強にたとえるとわかりやすくなります。過去問を丸暗記して同じ問題だけ解ける状態は、学習データへの適合度は高いかもしれません。一方で、初めて見る応用問題にも考え方を使って答えられる状態は、汎化性能が高い状態に近いと言えます。
つまり、汎化性能は「覚えたものを再現する力」ではなく、学習した規則性を新しいデータへ応用する力です。機械学習モデルを現実の業務やサービスで使うなら、この力が十分にあるかを確認しなければなりません。
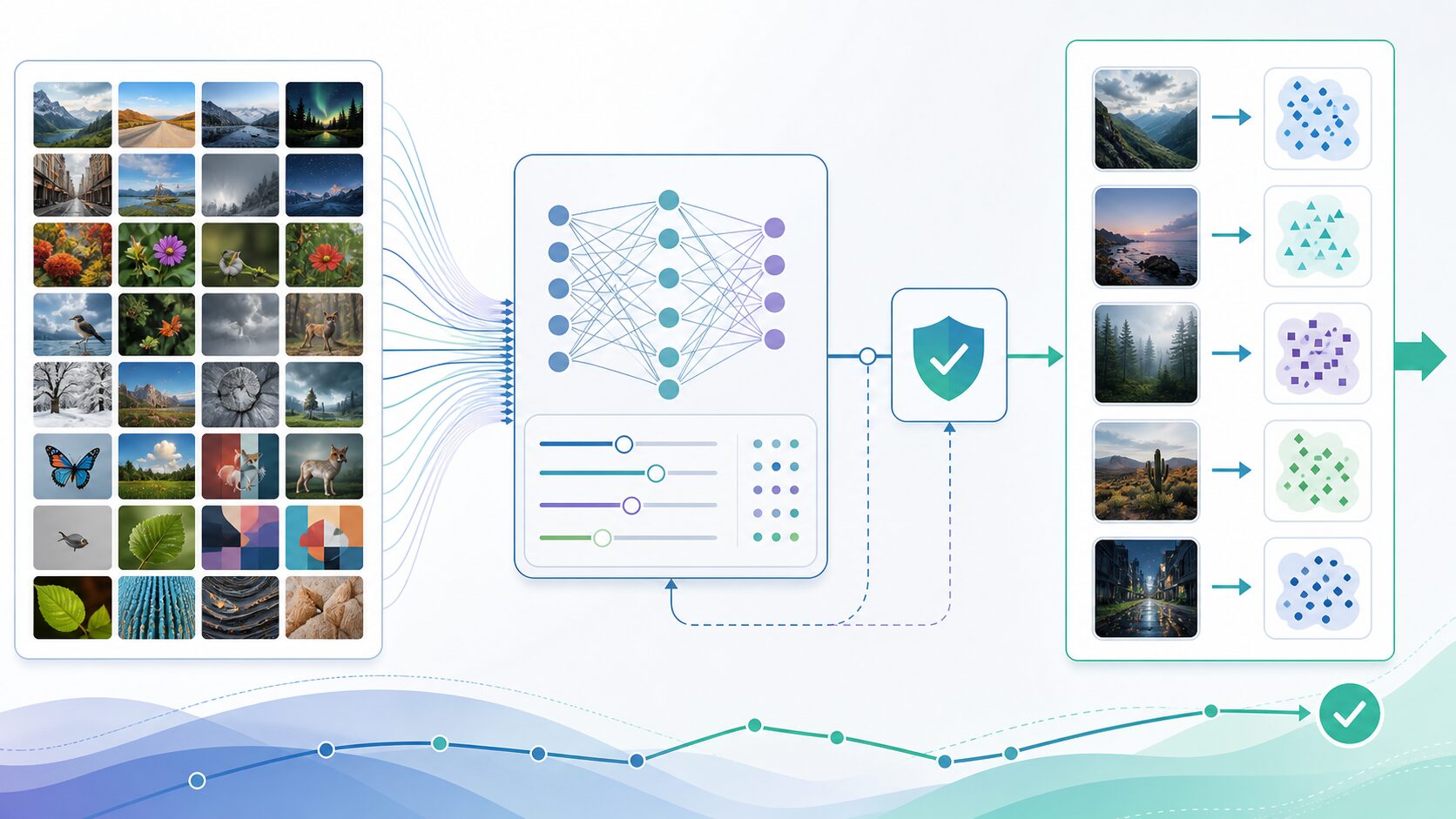
汎化性能が重要な理由
機械学習モデルは、現実世界で使われて初めて価値を発揮します。ところが、現実のデータは学習時とまったく同じ形では現れません。画像なら明るさ、角度、背景、解像度が変わります。文章なら言い回しや文脈が変わります。数値データでも、季節、地域、利用者層、市場環境などの影響を受けます。
たとえば、猫画像を分類するAIが、学習データにあった猫だけを見分けられても不十分です。背景が室内から屋外に変わったり、毛色が違ったり、横向きではなく正面を向いていたりしても、猫の特徴を捉えて判断できる必要があります。このように、学習データと少し違う状況でも安定して働くことが、汎化性能の重要な役割です。
自動運転の例でも同じです。晴れた日の決まった道路だけでうまく走れるモデルは、実用的とは言えません。雨の日、夜間、工事中の道路、歩行者の動きなど、学習時には少なかった状況にも対応する必要があります。医療診断支援でも、特定の病院や特定の患者層にだけ合うモデルでは、別の環境で性能が落ちるおそれがあります。
そのため、汎化性能は単なる評価指標ではなく、AIを安全に使えるか、継続的に役立つかを判断する基準でもあります。学習データでの成績だけを見ると、モデルの実力を過大評価してしまうことがあるため注意が必要です。
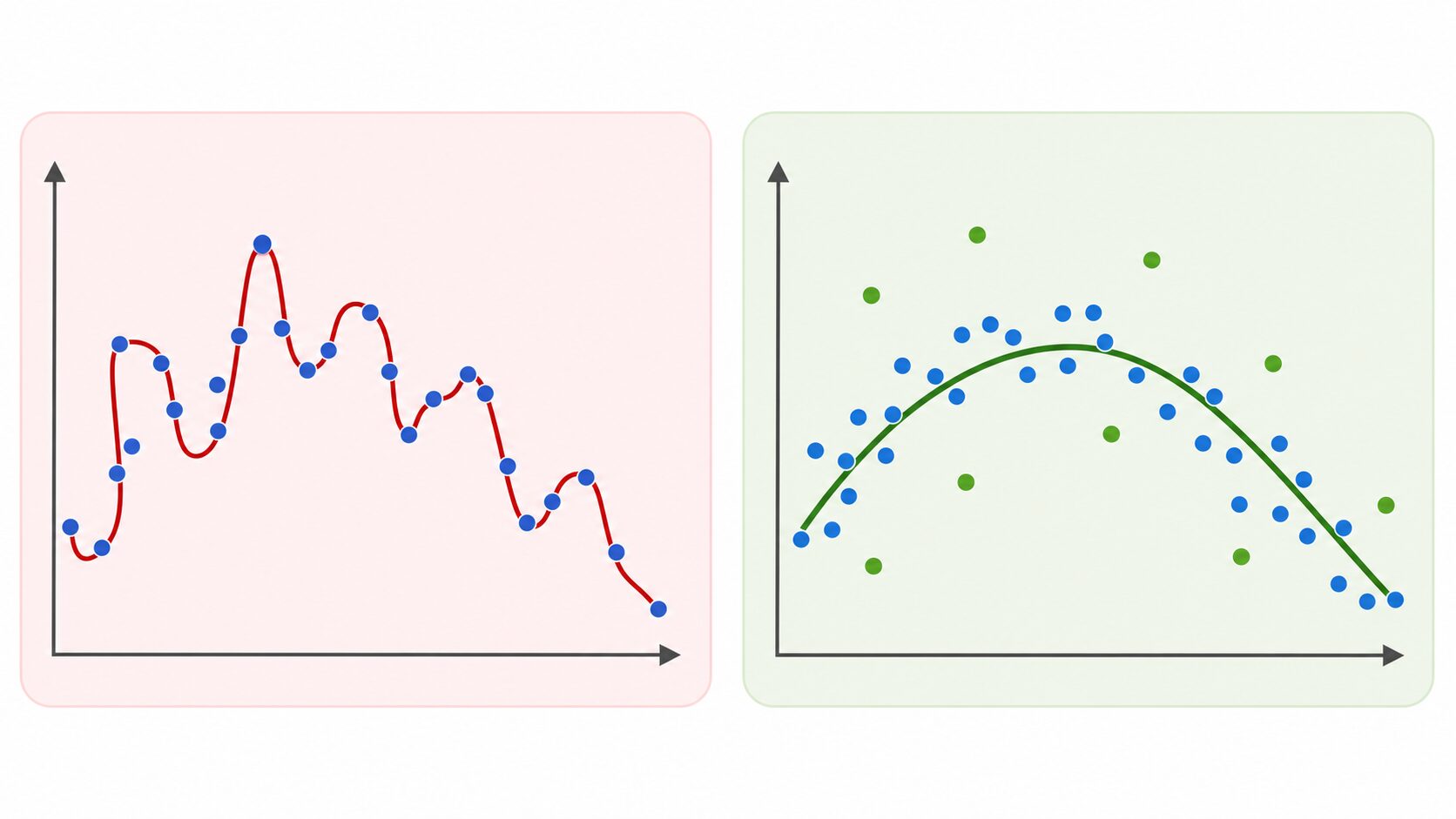
汎化性能と過学習の関係
汎化性能を考えるときに必ず出てくるのが、過学習です。過学習とは、モデルが訓練データに合わせ込みすぎて、未知データへの対応力が下がる状態を指します。
過学習したモデルは、訓練データでは非常に高い精度を示すことがあります。しかし、それはデータの本質的なパターンを学んだというより、訓練データに含まれる細かなクセやノイズまで覚えてしまった状態です。たとえば、猫を判定するモデルが、猫そのものではなく「特定の背景」や「特定の撮影条件」に強く反応してしまうと、背景が変わっただけで誤判定しやすくなります。
汎化性能が高いモデルは、訓練データの細部を丸暗記するのではなく、多くのデータに共通する特徴を捉えます。猫であれば、耳の形、顔の輪郭、体の構造など、環境が変わっても比較的保たれる特徴を使って判断します。
したがって、モデル開発では「訓練データの精度を上げること」だけを目標にしてはいけません。訓練データでの性能と、検証データやテストデータでの性能を比べ、差が大きくなりすぎていないかを見ることが重要です。この差が大きい場合、過学習が起きている可能性があります。

汎化性能を評価する方法
汎化性能を正しく評価するには、学習に使うデータと評価に使うデータを分けます。基本は、集めたデータを訓練データ、検証データ、テストデータに分ける考え方です。
訓練データは、モデルがパターンを学ぶために使います。検証データは、モデルの設定や学習の進み具合を調整するために使います。テストデータは、最終的にモデルが未知データへどれくらい対応できるかを確認するために使います。特にテストデータは、モデルの調整に何度も使いすぎないことが大切です。
データ数が少ない場合は、交差検証が使われることもあります。交差検証では、データをいくつかのまとまりに分け、学習用と評価用を入れ替えながら複数回評価します。これにより、たまたま分割したデータの偏りに左右されにくくなります。
評価時に注意したいのは、テストデータが学習工程に漏れ込むと、汎化性能を高く見積もってしまうことです。これをデータ漏洩と呼ぶことがあります。たとえば、テストデータの情報を使って前処理や特徴量選択をしてしまうと、本来は未知であるはずの情報をモデル開発に使ったことになり、評価の信頼性が下がります。
また、評価指標も目的に合わせて選ぶ必要があります。分類なら正解率、適合率、再現率、F値などが使われます。予測値の誤差を見る回帰問題なら、平均絶対誤差や二乗平均平方根誤差などが使われます。重要なのは、指標の数字だけでなく、そのモデルが実際の利用場面で許容できる判断をしているかまで確認することです。
汎化性能を高める主な方法
汎化性能を高めるには、いくつかの代表的な方法があります。まず重要なのは、学習データの量と多様性を増やすことです。さまざまな条件のデータに触れるほど、モデルは一部のクセに依存しにくくなります。画像であれば、角度、明るさ、背景、対象物の種類などに幅を持たせることが有効です。
次に、モデルの複雑さを適切に調整します。複雑なモデルは高い表現力を持ちますが、データが少ない場合やノイズが多い場合には、訓練データへ過度に適合しやすくなります。必要以上に大きなモデルを使わず、目的とデータ量に合った構成を選ぶことが大切です。
正則化もよく使われる方法です。正則化は、モデルが一部の特徴や大きすぎるパラメータに依存しすぎないよう制約を加える考え方です。これにより、訓練データに対する過度な合わせ込みを抑え、未知データでも安定しやすいモデルを目指します。
そのほか、学習の途中で検証データの性能が悪化し始めたら学習を止める早期終了、データを人工的に変化させて学習例を増やすデータ拡張、複数の分割で性能を確認する交差検証なども役立ちます。どれか一つの方法だけで解決するのではなく、データ、モデル、評価方法を組み合わせて調整することが現実的です。
実務・学習で注意したいポイント
汎化性能を学ぶときは、「高精度」という言葉だけに引っ張られないことが大切です。訓練データで99%の正答率が出ていても、テストデータで大きく下がるなら、実用上は不安が残ります。逆に、訓練データで少し低くても、未知データで安定しているモデルのほうが使いやすい場面もあります。
また、テストデータが現実の利用環境を代表しているかも確認する必要があります。たとえば、都市部のデータだけで評価したモデルを地方の環境で使う、若年層のデータだけで評価したモデルを高齢者にも使う、といった場合には、データの分布がずれて性能が落ちる可能性があります。
汎化性能は「どんな未知データにも必ず正しく対応できる」という意味ではありません。あくまで、学習した範囲から外れすぎない新しいデータに対して、どの程度安定して性能を出せるかを測る考え方です。だからこそ、モデルを公開したあとも、実際の運用データで性能を監視し、必要に応じて再学習や評価の見直しを行うことが重要になります。
まとめ
汎化性能とは、機械学習モデルが学習に使っていない未知データにも対応できる能力です。学習データで高い成績を出すだけでは、現実のデータに強いモデルとは言えません。
汎化性能を正しく見るには、訓練データ、検証データ、テストデータを分け、過学習やデータ漏洩に注意しながら評価する必要があります。さらに、データの多様性、モデルの複雑さ、正則化、交差検証などを組み合わせることで、未知の状況にも対応しやすいモデルを目指せます。
AIや機械学習を学ぶうえでは、汎化性能を「実際に役立つモデルかどうかを見極める視点」として理解しておくと、モデル評価や改善の意味がつかみやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月16日 | 過学習、評価方法、運用時の見落としやすい論点を追記 |