 学習
学習 機械学習と汎化性能とは?意味・過学習との関係・高め方を解説
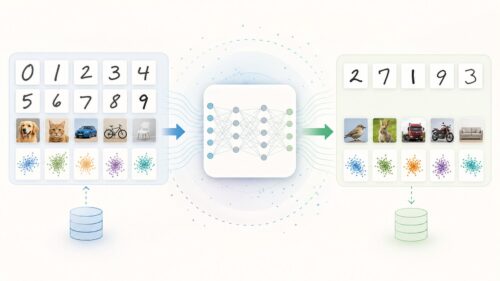
学習した機械が、初めて見る情報にもうまく対応できる能力、これが汎化性能です。未知の情報に対する対応力と言い換えることもできます。
たとえば、たくさんの犬の絵を見せて機械に犬を覚えさせたとします。学習後、機械が初めて見る犬の絵でも、「これは犬だ」と正しく判断できれば、汎化性能が高いと言えます。逆に、学習した犬の絵と全く同じ絵しか犬と認識できなければ、汎化性能が低いと判断されます。これは、機械が本質的な特徴を捉えていないことを意味します。つまり、耳の形や鼻の形、尻尾など、犬の種類に関係なく共通する特徴を理解していないのです。
機械学習の目的は、現実の課題を解決することにあります。現実世界では、常に新しい情報が流れてきます。そのため、初めて見る情報にも対応できる能力、すなわち汎化性能の高さが重要になります。
汎化性能を高めるには様々な工夫が必要です。学習に使う情報の量や質を調整したり、学習方法自体を改良したりします。まるで職人が技術を磨くように、様々な調整を経て性能を高めていくのです。
高い汎化性能を持つ機械は、新しい状況にも柔軟に対応できます。未知の病気を診断する、将来の需要を予測するなど、様々な分野で精度の高い予測や判断を可能にし、私たちの生活をより豊かにする可能性を秘めていると言えるでしょう。