逆強化学習:熟練者の技をAIで再現

AIの初心者
先生、『逆強化学習』って、普通の強化学習とは何が違うんですか?

AI専門家
いい質問だね。普通の強化学習は、目標が先にあって、それを達成するための行動をコンピュータに学習させるんだ。逆強化学習は、目標がわからない。でも、上手な人の行動を見本にして、その人が何を目標にしているのかをコンピュータが推測して、さらに上手な行動を見つけ出すんだよ。
AIの初心者
つまり、上手な人の真似をして、さらに上を目指すってことですか?
AI専門家
そうだね。たとえば、車の運転で言うと、上手な運転手の運転データから『安全に早く目的地に着く』という目標をAIが推測し、その運転手よりもさらに効率の良い運転方法を見つける、といったことができるんだよ。
逆強化学習とは。
いわゆる人工知能の分野で使われる「逆強化学習」という技術について説明します。これは機械学習の一種で、上手な人のやり方を見て、その人が何を目標にしているのかを推測します。そして、その目標を達成するために、上手な人よりもさらに良い方法を見つけ出そうとする技術です。
はじめに

人のような賢い機械を作る分野では、機械に人の熟練した技を教え込むことが大きな目標となっています。これまでの機械学習では、はっきりとした目標を定め、その目標に向かう行動を機械に覚えさせるのが普通でした。例えば、囲碁で勝利することが目標であれば、勝利につながる打ち手を学習させるわけです。しかし、人の行動はいつもはっきりとした目標に基づいているわけではありません。
例えば、腕のいい職人の技を考えてみましょう。彼らの技は長年の経験から来る直感や、言葉では言い表せない知識に支えられています。このような、言葉で説明するのが難しい技を機械に教え込むのは、従来の方法では困難でした。
このような難題に対して、『逆強化学習』と呼ばれる新しい方法が注目されています。逆強化学習とは、熟練者の行動をよく観察することで、その行動の裏にある目的や価値観を推測し、それを元に機械が最適な行動を学ぶ方法です。
具体的には、熟練した職人がどのように道具を扱い、材料を加工しているかを細かく観察し、そこから職人が何を大切にして作業しているのかを推測します。例えば、製品の美しさ、作業の速さ、材料の節約など、様々な価値観が考えられます。そして、推測した価値観を元に、機械は同じように行動することを目指して学習します。これは、まるで熟練者の考えを読み解き、その大切な部分を機械に移し替えるような、画期的な方法と言えるでしょう。
このように、逆強化学習は、これまで難しかった暗黙知を扱う技術を実現する上で、大きな期待が寄せられています。
手法の仕組み

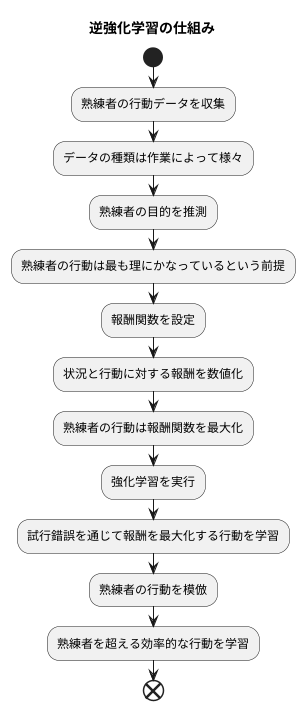
熟練者の技を機械に教え込む、逆強化学習の仕組みについて詳しく見ていきましょう。この手法は、熟練者の行動を記録した情報、例えばロボットの動きの軌跡や囲碁の棋譜といったデータを出発点とします。まず、これらのデータを集めることが最初の段階です。データの種類は、教えたい作業によって様々です。
次に、集めたデータから、熟練者がどのような目的意識を持って行動していたのかを推測します。この推測は、熟練者の行動は最も理にかなっているという前提に基づいて行われます。具体的には、その行動を最も上手く説明できる目的を探し出す問題として捉えます。この目的は、多くの場合「報酬関数」という形で表現されます。
報酬関数は、ある状況である行動をとった時に得られる報酬を数値で表す関数です。熟練者の行動は、この報酬関数の値を最大にするように選ばれていると考えます。例えば、ロボットが物を掴む作業を学習する場合、掴むことに成功したら高い報酬が得られ、失敗したら低い報酬が得られるような関数を設定します。熟練者の行動データから、掴む位置、速度、角度などを分析し、成功に繋がりやすい行動に高い報酬を与える関数を推定するのです。
このようにして推定された報酬関数を用いて、強化学習という学習方法を実行します。強化学習は、試行錯誤を通じて報酬を最大化する行動を学習する手法です。逆強化学習では、推定した報酬関数を基に、機械が試行錯誤を行い、熟練者の行動を模倣するように学習します。さらに学習を進めることで、熟練者の技を真似るだけでなく、熟練者を超える、より効率的な行動を学習することも可能になります。このように、逆強化学習は、熟練者の行動データから目的を推定し、それを基に機械学習を行うことで、高度な技能の習得を実現する手法です。
応用例

逆強化学習は、お手本となる行動からその背後にある意図や目的を読み解き、機械に学習させる技術です。この技術は、様々な分野で応用が期待されており、私たちの生活を大きく変える可能性を秘めています。
例えば、製造業におけるロボット制御の分野では、熟練作業者の複雑な動作をロボットに学習させることができます。従来のロボット制御では、一つ一つの動作を細かくプログラムする必要がありました。しかし、逆強化学習を用いれば、熟練者の動きをデータとして記録し、その背後にある目的や戦略をロボットが理解することで、人間のように滑らかで効率的な作業を自動化できるようになります。
医療分野においても、逆強化学習は大きな期待を集めています。医師の診断データや治療方針の決定過程を分析することで、病気の早期発見や最適な治療法の選択に役立つ可能性があります。例えば、ベテラン医師の豊富な経験に基づく診断を学習することで、経験の浅い医師でも適切な診断を下せるようになるかもしれません。また、患者の状態や体質に合わせた最適な治療計画を立てる上でも、この技術は役立つと考えられます。
さらに、自動運転技術の開発においても、逆強化学習は重要な役割を果たすと期待されています。熟練ドライバーの運転データ、例えばハンドル操作やアクセルワーク、ブレーキ操作などを分析することで、より安全でスムーズな自動運転システムを実現できる可能性があります。人間のように状況に合わせて柔軟に対応できる自動運転車は、交通事故の削減に大きく貢献するでしょう。
このように、逆強化学習は、まるで人間の知恵を機械に移植するかのような技術であり、様々な分野で革新をもたらす可能性を秘めているのです。
| 分野 | 従来の方法 | 逆強化学習による改善 | 期待される効果 |
|---|---|---|---|
| 製造業 | ロボットの動作を一つ一つプログラムする必要があった | 熟練者の動作データから目的や戦略を学習 | 人間のように滑らかで効率的な作業の自動化 |
| 医療 | 医師の経験に基づく診断 | 医師の診断データや治療方針の決定過程を分析 | 病気の早期発見、最適な治療法の選択、経験の浅い医師でも適切な診断が可能に |
| 自動運転 | – | 熟練ドライバーの運転データを分析 | より安全でスムーズな自動運転システムの実現、交通事故の削減 |
課題と展望

人の熟練した技を機械に教え込む、逆強化学習という方法には、大きな可能性とともに、乗り越えるべき壁もいくつかあります。まず、熟練者の行動を記録したデータから、どのような基準で行動の良し悪しを判断しているのか(報酬関数)を正確に読み解くのが難しいのです。人は複数の目的を同時に考えて行動していることが多く、一つの判断基準だけでその行動の全てを説明することはできません。例えば、自動車の運転では、安全に目的地へ到着すること以外にも、同乗者の乗り心地や燃費なども考慮しているでしょう。このように複雑な判断基準を読み解くのは容易ではありません。また、せっかく苦労して読み解いた判断基準が、本当に熟練者の考えていることを正しく表しているのかを確認するのも難しい問題です。推定した判断基準を基に機械に学習させても、熟練者とは全く異なる行動をとってしまうかもしれません。
これらの課題を解決するために、より高度な推定の仕組みを作る研究や、人の考えをより的確に反映できる判断基準の表現方法を探る研究が進められています。例えば、熟練者に直接判断基準を質問したり、複数の判断基準を組み合わせたりする手法が考えられます。まるで探偵のように、様々な角度から人の思考を解き明かす必要があります。もしこれらの研究がさらに進めば、逆強化学習はより強力な道具となり、様々な分野で人の能力をはるかに超える機械の実現につながるでしょう。医療現場での診断支援や、災害時の救助活動、新しい製品の設計など、応用の可能性は無限に広がっています。近い将来、逆強化学習によって育てられた機械が、私たちの生活を大きく変える日が来るかもしれません。
| 逆強化学習の課題 | 解決策 | 将来への展望 |
|---|---|---|
| 熟練者の行動データから、行動の良し悪しを判断する基準(報酬関数)を正確に読み解くのが難しい。 ・人は複数の目的を同時に考えて行動している。 ・一つの判断基準だけでは行動の全てを説明できない。 |
より高度な推定の仕組みを作る研究 人の考えをより的確に反映できる判断基準の表現方法を探る研究 ・熟練者に直接判断基準を質問する ・複数の判断基準を組み合わせる |
様々な分野で人の能力をはるかに超える機械の実現 ・医療現場での診断支援 ・災害時の救助活動 ・新しい製品の設計 逆強化学習によって育てられた機械が私たちの生活を大きく変える |
まとめ

人の熟練した技を機械に覚えさせることは、これまで難しいことでした。なぜなら、熟練の技は言葉で説明することが難しい暗黙の知識や、長年の経験に基づいているからです。しかし、「逆強化学習」という新しい方法が登場したことで、状況は変わりつつあります。
逆強化学習は、熟練者がどのように行動しているかを観察し、そこからその人が何を目標としているのかを推測します。例えば、自転車に乗る熟練者を観察することで、バランスを保ちつつ、目的地に速く安全に到達することが目標だと推測できます。そして、その目標を達成するための最適な行動を機械が学習していくのです。
従来の方法では、機械に学習させるためには、どのような行動が良いのかを具体的に指示する必要がありました。しかし、逆強化学習では、熟練者の行動を見せるだけで、機械が自分で目標や最適な行動を理解していきます。これは、まるで人が師匠の技を見て学ぶように、機械が人の技を学ぶことを可能にする画期的な方法です。
この技術は、様々な分野で応用が期待されています。例えば、ロボットの制御です。複雑な動きを必要とするロボットに、熟練者の動きを模倣させることで、より滑らかで正確な動作を学習させることができます。また、医療の分野では、医師の診断や治療の行動を分析することで、より効果的な治療法の開発に役立つ可能性があります。さらに、自動運転技術にも応用が期待されており、より安全で効率的な運転を実現できる可能性を秘めています。
逆強化学習は、単に熟練者の行動を真似るだけでなく、その背後にある意図や価値観を理解することを目指しています。これにより、機械はより人間らしい知能を獲得し、私たちの生活をより豊かで便利なものにする可能性を秘めています。今後の研究の進展により、逆強化学習が社会に大きな変化をもたらすことが期待されます。
| 従来の機械学習 | 逆強化学習 |
|---|---|
| 熟練の技を機械に覚えさせるのは困難 | 熟練の技を機械に覚えさせることが可能に |
| 言葉で説明できる必要がある | 熟練者の行動観察から目標を推測 |
| 機械学習に良い行動を具体的に指示する必要あり | 熟練者の行動を見せるだけで学習 |
| – | 様々な分野への応用が期待される
|