教師あり学習とは?機械学習の基礎をわかりやすく解説

AIの初心者
「教師あり学習」って、どんな学習方法ですか?

AI専門家
教師あり学習は、あらかじめ正解が分かっているデータを使ってAIに学習させる方法です。犬と猫の写真に「犬」「猫」という正解ラベルを付けて見せ、特徴と答えの関係を覚えさせるイメージです。
AIの初心者
正解付きの例題をたくさん用意して、未知のデータにも答えられるようにするのですね。他の例でも考えられますか?
AI専門家
例えば、過去の気温や曜日、天気とアイスクリームの売上をセットで学習させれば、未来の条件から売上を予測できます。この場合、気温や天気が「入力」、売上が「正解」にあたります。
教師あり学習とは。
教師あり学習とは、入力データと正解データの組を使って、未知のデータに対する答えを予測できるようにする機械学習の方法です。画像に写っているものを判定する、住宅価格を予測する、文章を翻訳する、異常なログを見つけるなど、多くのAI活用の土台になっています。
この記事では、教師あり学習の意味、機械学習の中での位置づけ、学習の仕組み、分類と回帰の違い、活用例、注意点を初心者向けに整理します。専門用語を丸暗記するよりも、「何を入力し、何を正解として学び、何を予測したいのか」という流れで理解すると、教師あり学習はぐっと分かりやすくなります。
教師あり学習とは
教師あり学習では、学習に使うデータが「問題」と「答え」のセットになっています。例えば、果物の写真と「りんご」「みかん」という名前、家の広さや築年数と販売価格、メール本文と「迷惑メールかどうか」といった組み合わせです。この正解にあたる情報は、一般に教師データ、ラベル、正解データなどと呼ばれます。
モデルは、入力データの特徴と正解データの関係を学習します。果物の例なら、色、形、模様、輪郭などの特徴と果物名の関係を少しずつつかみます。学習後は、まだ見たことのない果物の画像を入力されたときに、過去に学んだ関係をもとに「これはりんごの可能性が高い」と予測します。
ここで重要なのは、教師あり学習の目的が、学習データを丸暗記することではない点です。目指すのは、学習に使っていない新しいデータにも妥当な予測を返せる状態です。この能力は「汎化」と呼ばれ、実用的な機械学習モデルを作るうえで非常に重要です。
機械学習の種類
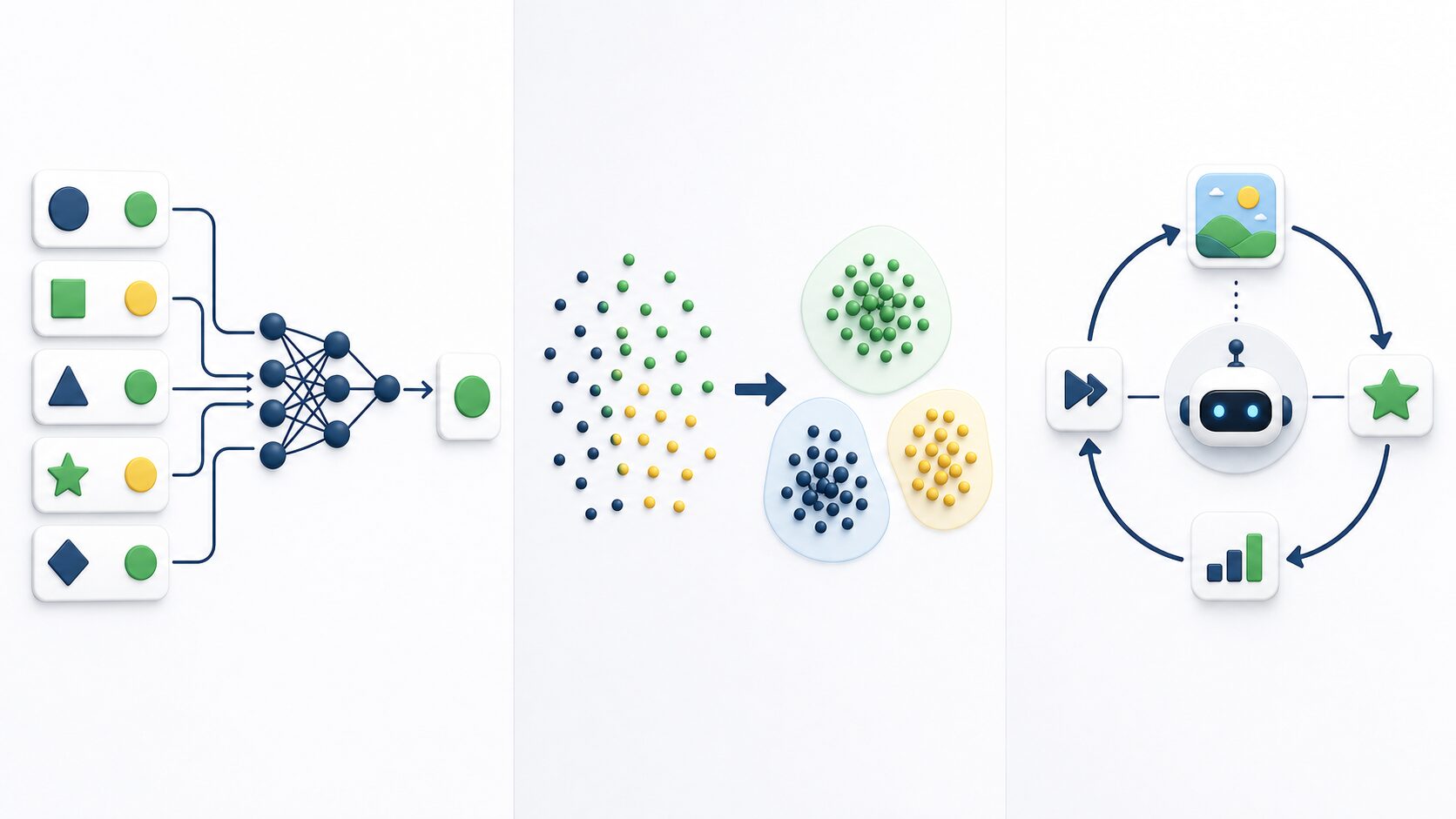
機械学習は、データから規則性やパターンを見つけ、判断や予測に利用する技術です。大きく見ると、教師あり学習、教師なし学習、強化学習に分けられます。違いを理解するには、学習時に「正解」があるかどうかに注目すると整理しやすくなります。
教師あり学習は、正解付きのデータを使います。画像に「猫」「犬」とラベルが付いている、過去の物件情報に販売価格が付いている、といった状況です。入力と出力の対応関係を学び、新しい入力に対して適切な出力を予測します。
教師なし学習は、正解ラベルがないデータから構造を見つける方法です。顧客の購買履歴をもとに似た行動の人をグループ分けする、たくさんの文書から似たテーマのまとまりを見つける、といった用途があります。最初から「正しいグループ名」が与えられているわけではありません。
強化学習は、行動と報酬を通じてよい戦略を学ぶ方法です。ゲームAIやロボット制御のように、ある環境の中で行動し、成功に近い行動ほど高い報酬を得ることで、次第に望ましい行動を選べるようにします。
| 学習方法 | 使うデータ | 目的 | 代表例 |
|---|---|---|---|
| 教師あり学習 | 入力と正解のセット | 未知のデータに対してカテゴリや数値を予測する | 画像認識、価格予測、翻訳、異常検知 |
| 教師なし学習 | 正解ラベルのないデータ | データの構造、まとまり、特徴を見つける | 顧客分類、クラスタリング、次元削減 |
| 強化学習 | 行動、状態、報酬 | 報酬を最大化する行動方針を学ぶ | ゲームAI、ロボット制御、最適化 |
教師あり学習の仕組み
教師あり学習の基本的な流れは、学習データを用意し、モデルに予測させ、予測と正解のずれを確認し、そのずれが小さくなるようにモデルを調整する、というものです。人が問題集を解き、答え合わせをして、間違えた部分を修正していく流れに近いと考えると分かりやすいでしょう。
まず、入力データと正解データを集めます。画像認識なら画像とラベル、売上予測なら日付、気温、キャンペーン有無などの条件と実際の売上です。モデルは入力から出力を予測しますが、最初から正確に答えられるわけではありません。
次に、予測結果と正解を比べます。予測が外れていれば誤差が大きく、正解に近ければ誤差は小さくなります。モデル内部には重みやパラメータと呼ばれる調整値があり、学習ではこの値を少しずつ変えながら、誤差が小さくなる方向を探します。
この作業を大量のデータで繰り返すことで、モデルは入力と正解の関係を学びます。ただし、学習データにだけ過剰に合わせすぎると、新しいデータに弱くなります。これが過学習です。実務では、学習に使うデータとは別に検証用・評価用のデータを用意し、未知のデータに対する性能を確かめます。
教師あり学習の二つの種類:分類と回帰
教師あり学習は、予測したい答えの種類によって、主に分類と回帰に分けられます。どちらも入力と正解の関係を学ぶ点は同じですが、出力の性質が異なります。
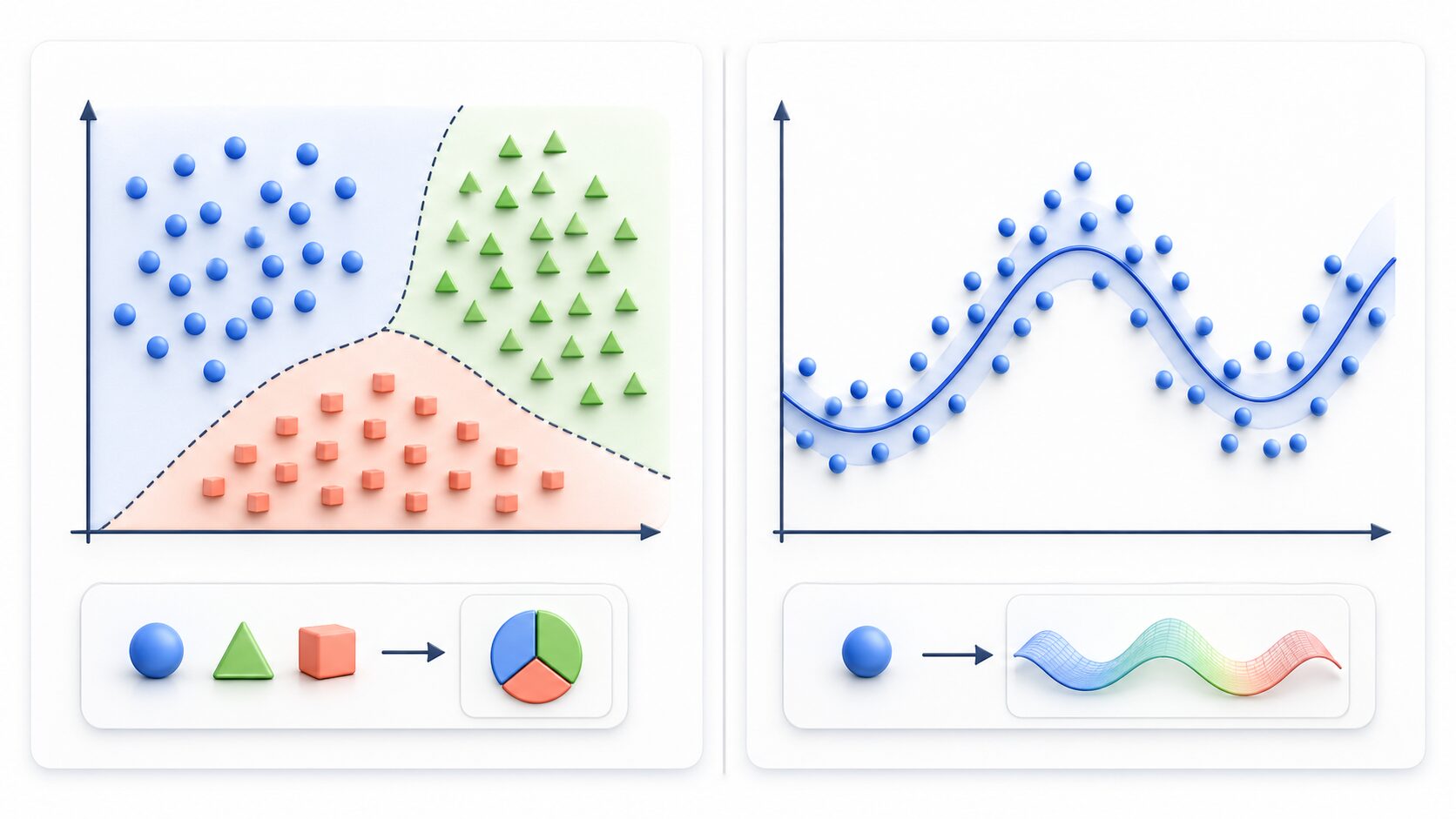
分類は、データがどのカテゴリに属するかを予測する問題です。犬か猫か、迷惑メールか通常メールか、画像に写っているものが車か人か、といった判断が分類にあたります。出力はカテゴリ名やクラス、または各カテゴリに属する確率になります。
回帰は、連続した数値を予測する問題です。家の価格、明日の気温、来月の売上、商品の需要量などを予測する場合に使われます。出力は「高い・低い」のようなカテゴリではなく、価格や温度、数量といった数値です。
分類と回帰を使い分けるには、「予測したい答えが種類なのか、数値なのか」を確認します。例えば、メールを「迷惑メールかどうか」に分けたいなら分類、顧客が来月いくら購入しそうかを予測したいなら回帰です。この判断を間違えると、適切なモデルや評価指標を選びにくくなります。
| 種類 | 予測するもの | 具体例 | 出力のイメージ |
|---|---|---|---|
| 分類 | カテゴリやラベル | 猫か犬か、迷惑メールかどうか、故障の有無 | 「猫」「正常」「迷惑メール」など |
| 回帰 | 連続した数値 | 住宅価格、気温、売上、需要量 | 3200万円、25.4度、120個など |
教師あり学習の活用例
教師あり学習は、すでに多くの分野で使われています。特に、過去のデータと正解を大量に集められる業務では効果を発揮しやすい方法です。画像、文章、数値、センサーデータなど、入力データの種類はさまざまです。
画像認識では、写真とラベルを使って、写っている対象を判定します。ECサイトの商品分類、医療画像の補助診断、製造業の外観検査、自動運転の周辺認識などが代表例です。正しくラベル付けされた画像が多いほど、モデルは特徴と答えの関係を学びやすくなります。
機械翻訳や文章分類でも教師あり学習は重要です。日本語文と英語訳のペア、問い合わせ文とカテゴリのペア、レビュー文と評価ラベルのペアなどを学習し、新しい文章に対して翻訳や分類を行います。自然言語処理では、文脈を理解する深層学習モデルと組み合わせて使われることが多くなっています。
異常検知や需要予測にも使われます。正常時と異常時のデータが揃っていれば、設備の故障予兆や不正アクセスの兆候を検出できます。過去の販売実績、天候、曜日、キャンペーン情報があれば、将来の需要や売上を予測できます。
| 分野 | 教師データ | 学習する関係 | 活用例 |
|---|---|---|---|
| 画像認識 | 画像とラベル | 見た目の特徴と対象物の種類 | 商品分類、外観検査、自動運転 |
| 自然言語処理 | 文章と翻訳・カテゴリ・評価 | 文章の特徴と意味・分類先 | 機械翻訳、問い合わせ分類、レビュー分析 |
| 異常検知 | 正常データと異常データ | 通常状態と異常状態の違い | 設備監視、セキュリティ監視、品質管理 |
| 需要予測 | 条件データと実績値 | 条件と売上・需要の関係 | 在庫計画、販売予測、人員配置 |
教師あり学習で注意すべき点
教師あり学習は強力ですが、正解データを用意すれば必ず高精度になるわけではありません。まず重要なのは、データの量と質です。誤ったラベルが多い、特定の条件に偏っている、現実の利用場面と学習データが大きく違う、といった状態では、モデルの予測も不安定になります。
次に注意したいのが過学習です。学習データでは高い正解率が出ているのに、実際の新しいデータではうまく予測できない状態です。モデルが学習データの細かい癖まで覚えてしまい、一般的な規則を学べていない場合に起こります。学習用、検証用、評価用のデータを分けて性能を確認することが大切です。
また、教師データを作るコストも無視できません。画像にラベルを付ける、文章を分類する、異常の有無を専門家が判定する、といった作業には時間と人手がかかります。特に医療、金融、製造のように正解判定に専門知識が必要な分野では、データ作成の設計そのものがプロジェクトの成否に関わります。
さらに、予測結果をどのように使うかも重要です。AIの判断をそのまま自動実行するのか、人間の確認を挟むのか、誤判定したときの影響はどれほど大きいのかを考える必要があります。教師あり学習は便利な道具ですが、業務で使うには評価、監視、説明責任まで含めて設計することが求められます。
今後の展望
教師あり学習は、深層学習の発展によって画像認識、音声認識、自然言語処理などで大きく性能を伸ばしてきました。大規模なデータと高性能な計算環境を使うことで、従来より複雑な特徴や文脈を扱えるモデルが作られています。
一方で、今後は「大量の正解データがないと使えない」という課題を減らす研究も重要になります。少ないデータで学ぶ方法、既存モデルを別の用途に転用する方法、ラベル付けの負担を下げる方法が進めば、医療、製造、教育など、データ収集が難しい分野でも教師あり学習を使いやすくなります。
実務では、教師あり学習だけで完結するのではなく、教師なし学習、ルールベースの仕組み、人間の確認、生成AIなどと組み合わせる場面が増えています。重要なのは、技術名から入ることではなく、解きたい問題に対して「正解データを用意できるか」「予測したい答えは何か」「予測ミスの影響はどれくらいか」を確認することです。
まとめ
教師あり学習は、入力データと正解データの組を使って、未知のデータに対する予測を学ぶ機械学習の基本的な方法です。分類ではカテゴリを予測し、回帰では数値を予測します。画像認識、翻訳、異常検知、需要予測など幅広い分野で使われています。
初心者が押さえるべきポイントは、正解付きデータで学ぶこと、未知のデータに使える予測を目指すこと、分類と回帰を使い分けること、データ品質と過学習に注意することです。この流れを理解しておくと、機械学習の他の手法やAI活用の全体像もつかみやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月1日 | 教師あり学習の定義、機械学習の種類、分類と回帰、活用例、注意点を初心者向けに再構成 |