
報酬成形とは?強化学習を効率よく進めるための報酬設計
報酬成形とは、強化学習においてエージェントが望ましい行動を学びやすくなるように、報酬の与え方を設計・調整する考え方です。強化学習では、エージェントが環境を観察し、行動を選び、その結果として報酬を受け取ります。エージェントはより多くの報酬を得ようとして行動を変えていくため、どの行動にどれだけ報酬を与えるかが学習結果を大きく左右します。
単に「成功したら報酬を与える」だけでは、複雑な課題では学習が進みにくいことがあります。そこで、最終目標に近づく途中の行動にも適切な報酬を与え、学習の手がかりを増やします。これが報酬成形の基本です。
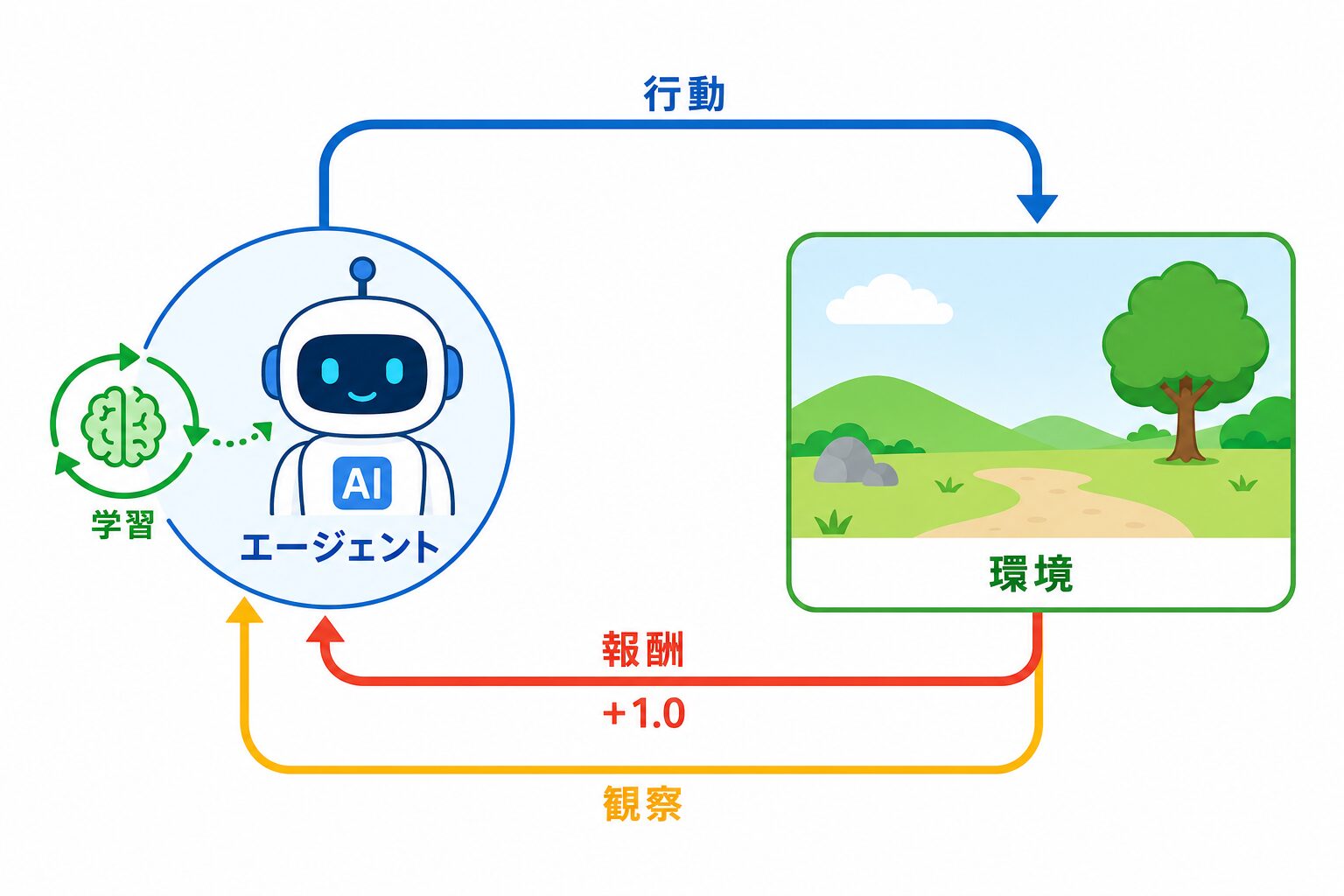
報酬成形は、エージェントが環境とのやり取りから学ぶ方向を整えるための工夫です。
犬のしつけで考える報酬成形
報酬成形は、犬に「お手」を教える場面にたとえると理解しやすくなります。最初から完璧に手を乗せたときだけ褒めると、犬は何をすればよいのか分からず、学習が進まないかもしれません。
そこで、はじめは手を少し上げたら褒め、次に人の手に近づけたら褒め、最終的にはきちんと手を乗せたときに褒めるようにします。目標に近い行動を段階的に評価することで、複雑な行動を学びやすくするわけです。
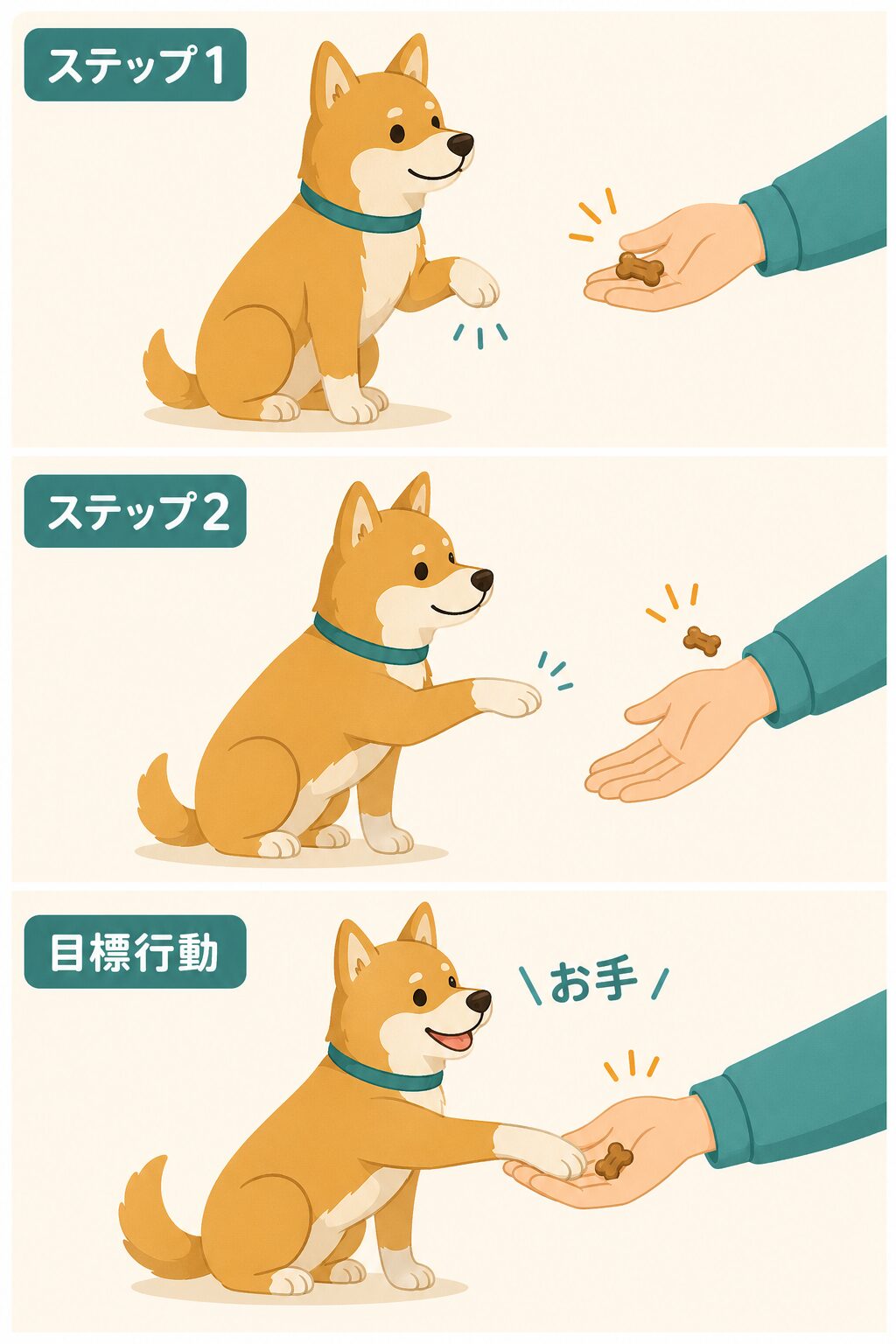
最終目標だけでなく、そこへ近づく行動にも報酬を与えると学習の道筋が見えやすくなります。
強化学習での報酬関数の役割
強化学習では、行動の良し悪しを数値で評価する仕組みを報酬関数と呼びます。報酬関数は、エージェントにとっての指導方針のようなものです。適切に設計されていれば、エージェントは目的に合った行動を効率よく見つけられます。
たとえば迷路を解くエージェントを考えます。ゴールに到達したときだけ報酬を与える設定でも学習は可能ですが、広い迷路ではゴールを見つけるまでに多くの試行錯誤が必要になります。ゴールに近づく正しい道を進んだときにも報酬を与えれば、エージェントはより早く有望な行動を学べます。
一方で、報酬関数が目的とずれていると、エージェントは望ましくない行動を覚えることがあります。ゴールに向かうことではなく、壁に沿って歩くことに報酬が与えられるような設計になっていれば、最短ルートを学ぶどころか、壁沿いに移動する行動ばかり強化される可能性があります。
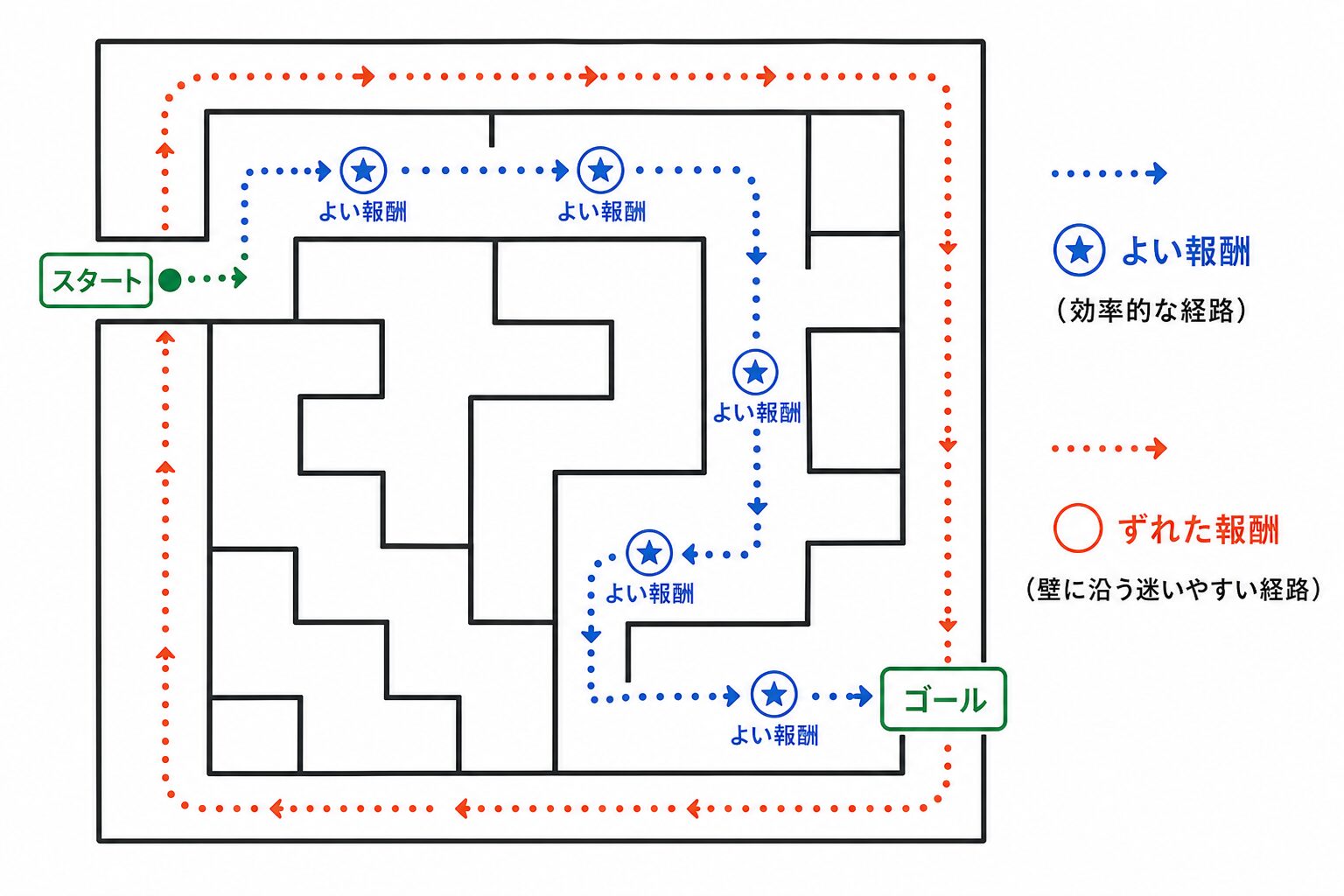
報酬は学習の方向を決めるため、目標とずれた報酬は意図しない行動を強化します。
実際の報酬成形は試行錯誤で進む
報酬成形は、一度決めたら終わりではありません。まず仮の報酬関数で学習させ、エージェントの行動を観察し、期待と違う動きがあれば原因を分析して報酬を調整します。この繰り返しによって、目的に合った報酬設計へ近づけていきます。
二足歩行ロボットを例にすると、単純に「進んだ距離」だけを報酬にすると、ロボットは遠くへ進もうとして転倒しやすくなるかもしれません。この場合は、進んだ距離に加えて、姿勢の安定性や転倒しないことも評価する必要があります。速度を重視したい場合は、一定時間内に進んだ距離を報酬へ反映させるといった調整も考えられます。
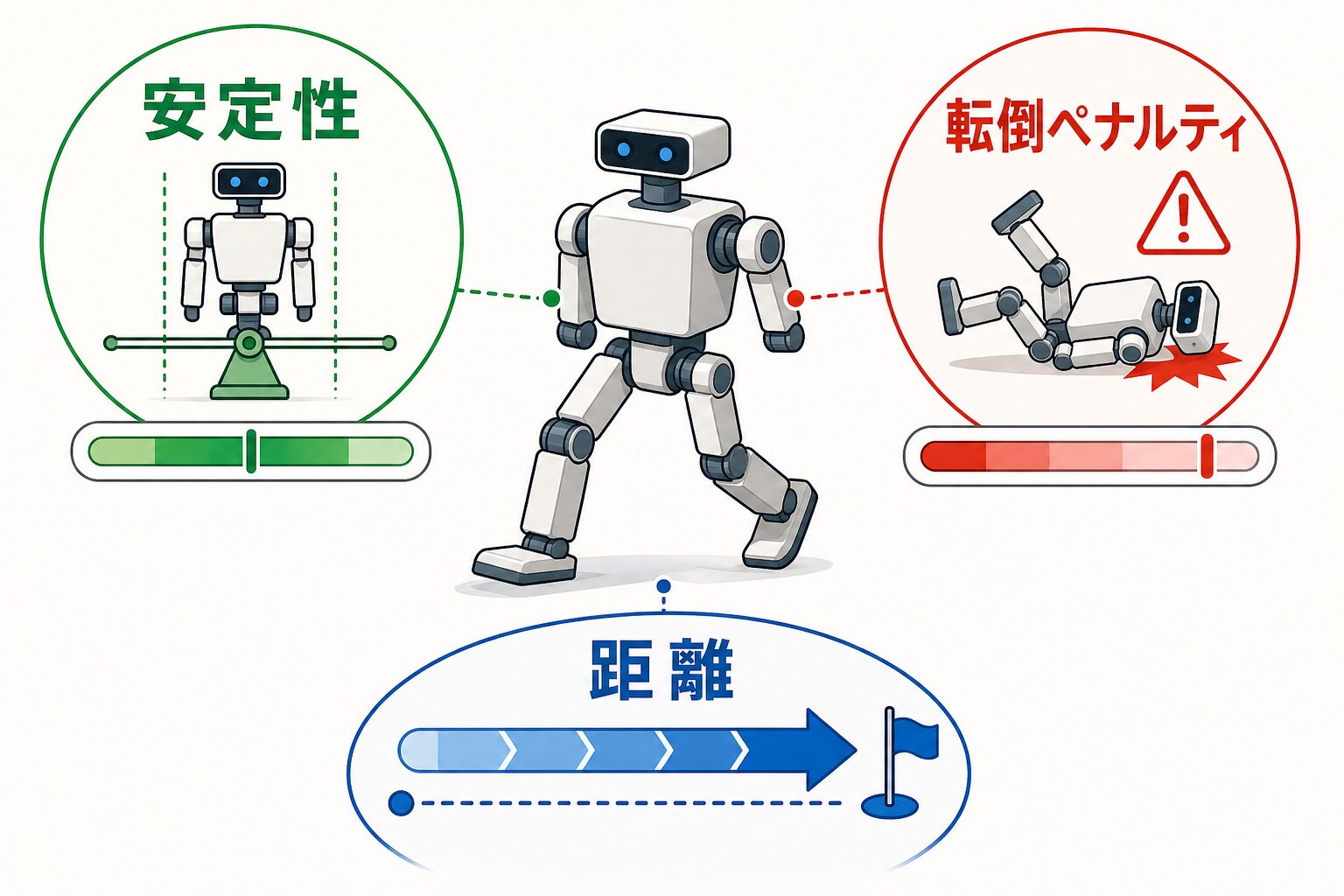
複数の観点を報酬に含めることで、目的に近い行動を学ばせやすくなります。
報酬設計が難しい理由
報酬関数の設計が難しいのは、単純すぎても複雑すぎても問題が起きるためです。基準が単純すぎると、エージェントは人間の意図とは違う方法で報酬を得ようとします。たとえば「部屋がきれいに見えること」だけを評価すると、必要なものを隠して見た目だけを整える行動が学習されるかもしれません。
逆に、条件を増やしすぎると、どの行動が評価されているのかが分かりにくくなり、学習が進みにくくなります。さらに、報酬は学習目的と合っていなければなりません。ゲームで高得点だけを目標にすると、人間らしい遊び方や世界観を楽しむ行動は再現されない可能性があります。
| 報酬設計の状態 | 起こりやすい問題 | 例 |
|---|---|---|
| 単純すぎる | 抜け道のような行動を学ぶ | 片付けで、物を隠して見た目だけを整える |
| 複雑すぎる | 何をすればよいか分からず学習が進みにくい | 条件が多すぎて、目標への手がかりが得られない |
| 目的と合っていない | 人間の意図しない行動が強化される | ゲームで得点だけを追い、人間らしい遊び方から外れる |
今後の展望
強化学習は、試行錯誤を通じて望ましい行動を学ばせる技術です。とくに深層学習と組み合わせた深層強化学習では、複雑なデータから特徴を取り出しながら行動を学べるため、自動運転やロボット制御などへの応用が期待されています。
ただし、課題が複雑になるほど、どの報酬を与えれば目的に合った行動を学べるのかを決めることは難しくなります。そのため、人間の指示や評価をもとに報酬関数を調整する方法や、複数の報酬関数を組み合わせる方法など、より効率的な報酬成形の研究が重要になります。
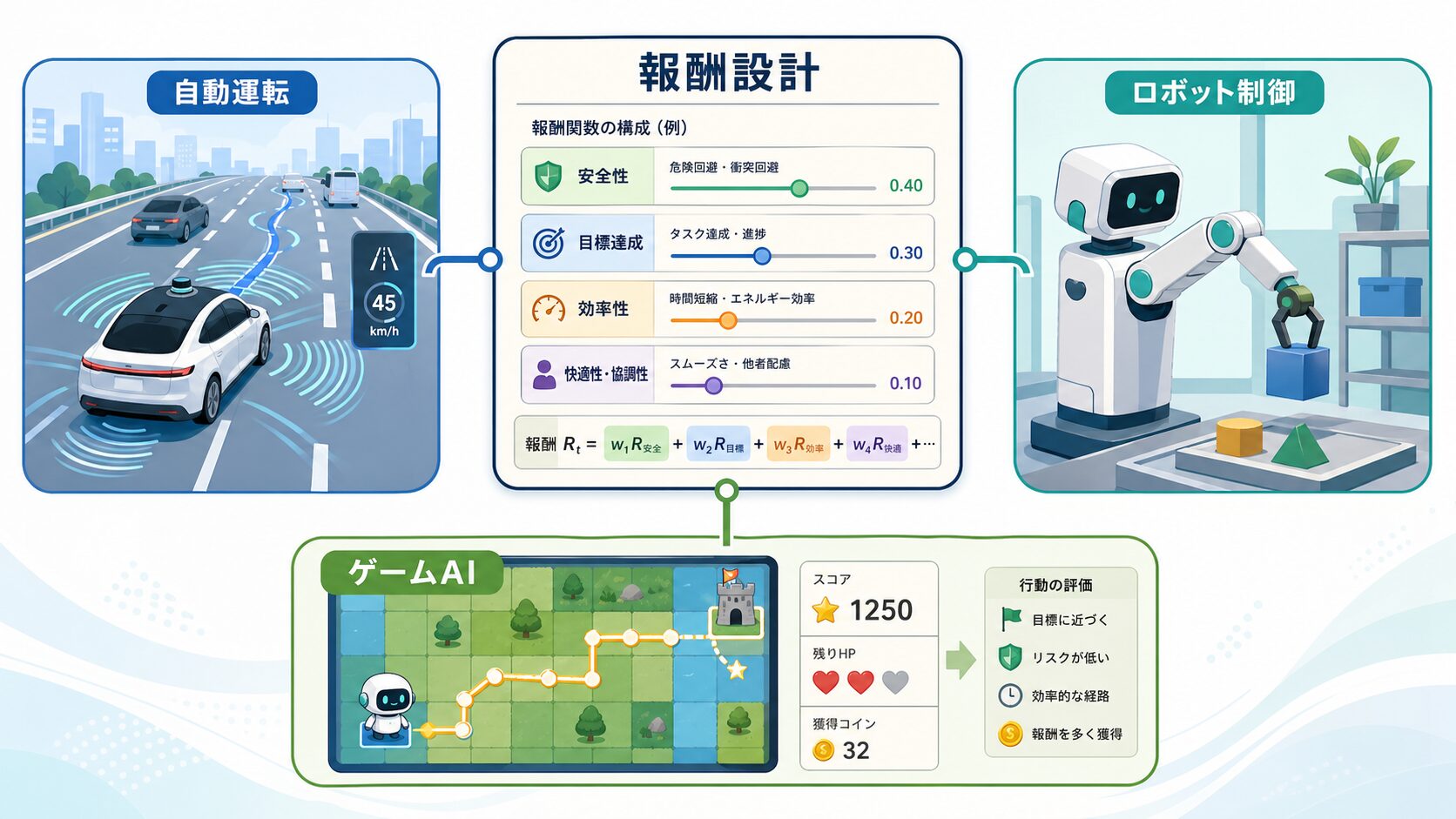
報酬成形の改善は、より複雑な強化学習タスクへの応用を広げる鍵になります。
まとめ
報酬成形は、強化学習でエージェントを正しい方向へ導くための重要な設計作業です。最終目標だけでなく、そこへ近づく中間的な行動にも報酬を与えることで、学習効率を高められます。
一方で、報酬の与え方が不適切だと、エージェントは予想外の行動を学習してしまいます。目的を明確にし、結果を観察しながら報酬関数を調整することが、強化学習を成功させるための大切なポイントです。
更新履歴
2026年4月28日: 元記事の内容をもとに、報酬成形の意味、具体例、注意点、今後の展望を読みやすく整理しました。