
局所最適解とは?機械学習の落とし穴

AIの初心者
「局所最適解」って何ですか?勾配降下法と関係があると聞きましたが、少し難しく感じます。

AI専門家
局所最適解は、全体で見ると一番よい答えではないのに、近くの範囲だけで見ると一番よく見える答えのことです。山ではなく谷で考えると、もっと深い谷が別にあるのに、目の前の小さな谷底で止まってしまう状態に近いですね。
AIの初心者
つまり、今いる場所の周りだけを見るとよさそうでも、全体ではもっとよい答えがあるかもしれない、ということですね。
AI専門家
その通りです。機械学習では、損失を小さくするようにパラメータを動かします。複雑な問題では損失の地形に谷や平らな場所がいくつもあるため、学習率、初期値、最適化手法を工夫して、よりよい解へ近づけることが大切です。
局所最適解とは
局所最適解とは、ある範囲の中では最もよい解に見えるものの、全体で見ると最善ではない解のことです。機械学習では、モデルの誤差を表す損失関数を小さくする過程で、この局所最適解に収束することがあります。特に、損失関数が複雑な形をしている場合は、出発点や学習率によって到達する解が変わるため注意が必要です。
局所最適解とは

局所最適解は、「近くの範囲では最適だが、全体では最適とは限らない解」です。機械学習では、モデルの重みやバイアスなどのパラメータを調整し、予測の誤差を小さくしていきます。この誤差を表す関数を損失関数と呼びます。
損失関数を地形にたとえると、値が小さい場所ほど低い谷になります。最も深い谷が大域最適解です。一方で、周囲よりは低いものの、全体で最も深いわけではない谷が局所最適解です。局所最適解とは、探索している近傍では最良でも、全体で見ればもっと良い解が残っている状態を指します。
この考え方は、最適化問題全般で重要です。機械学習では、損失を小さくすることが目的になるため、局所最適解に止まるとモデルの性能が本来より低いままになる可能性があります。ただし、実務上は「完全な大域最適解」だけが正解とは限りません。十分に性能が高く、未知のデータに対して安定していれば、局所的な解でも実用上は問題ない場合があります。
| 用語 | 意味 | 機械学習での見方 |
|---|---|---|
| 局所最適解 | 近くの範囲では最もよい解 | その周辺では損失が小さいが、別の場所により低い損失がある可能性がある |
| 大域最適解 | 全体で最もよい解 | 損失関数全体で最も損失が小さい点 |
| 局所解 | 局所最適解を短く表す言い方 | 文脈によっては局所的な最小値や最大値を指す |
| 最適化 | 目的に合う最良の値を探すこと | 損失を小さくする、精度を高めるなどの形で行う |
勾配降下法でなぜ起きるのか
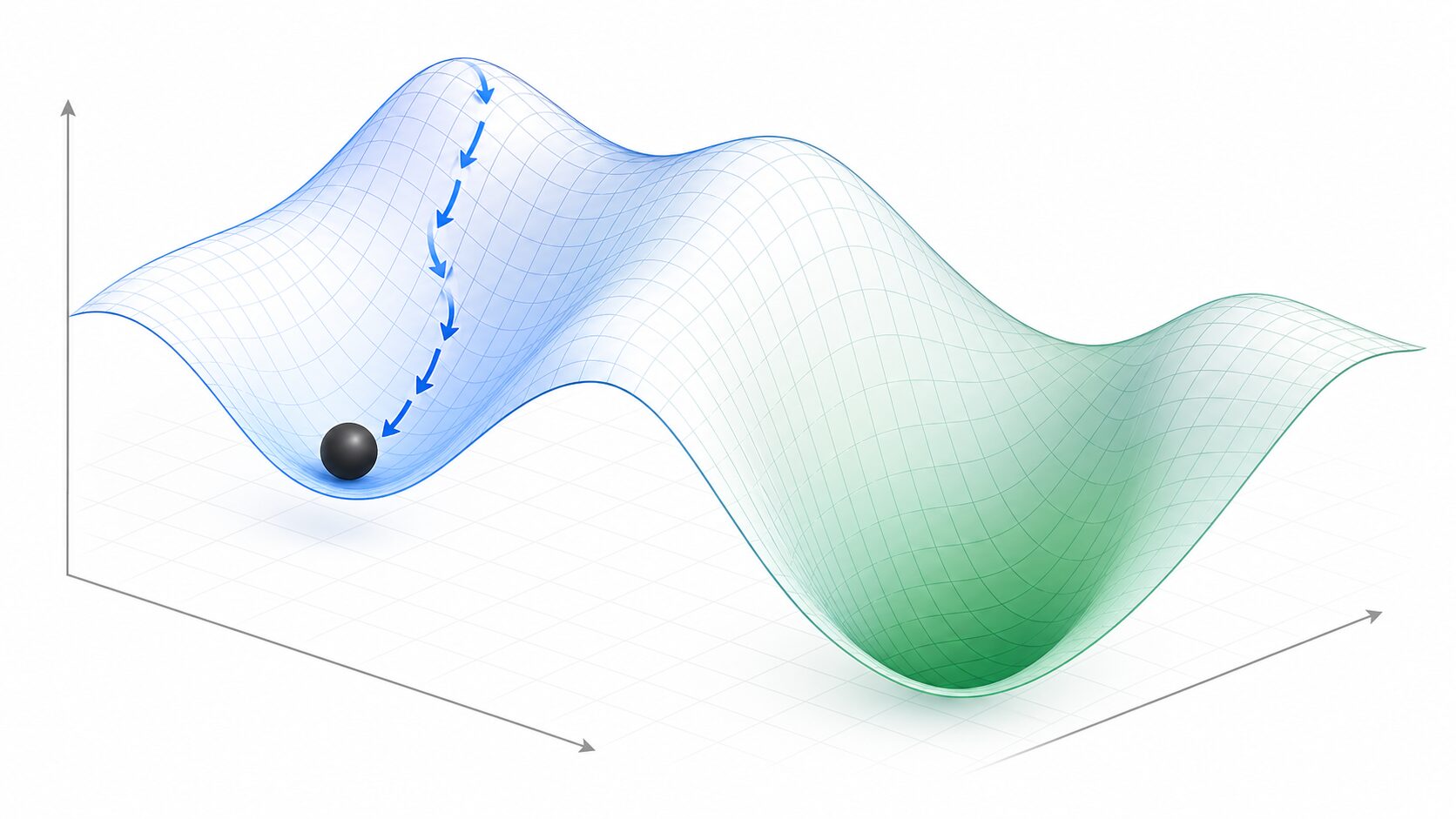
勾配降下法は、現在地の傾きを見て、損失が小さくなる方向へパラメータを少しずつ更新する方法です。山道で足元の傾きを見ながら低い方へ進むようなイメージです。計算が比較的わかりやすく、多くの機械学習モデルで基本となる考え方です。
しかし、勾配降下法は基本的に「今いる場所の周辺」の情報を使って進みます。損失関数の形が単純なら、下り続けるだけで最も低い場所へ到達しやすくなります。ところが、複雑な損失関数では谷が複数あるため、最初に入った浅い谷で傾きがほぼゼロになり、そこで学習が止まることがあります。
局所最適解が問題になるのは、勾配が小さくなった場所が、必ずしも全体で最もよい場所ではないためです。モデルの学習が進んでいるように見えても、別の初期値から始めればさらに低い損失へ到達できることがあります。
また、深層学習のようにパラメータ数が多い問題では、局所最適解だけでなく、鞍点や平坦な領域も学習を難しくします。鞍点とは、ある方向には下り坂でも、別の方向には上り坂になるような点です。表面上は勾配が小さく見えるため、学習が進みにくくなることがあります。
局所最適解と大域最適解の違い
局所最適解と大域最適解の違いは、「見ている範囲」です。局所最適解は周辺だけで判断した最適な解です。大域最適解は、探索対象全体で判断した最適な解です。小さな谷の底と、地形全体で最も深い谷の底を区別すると理解しやすくなります。
機械学習で「最適解とは何か」を考えるときは、損失関数の値だけでなく、未知データへの性能も見る必要があります。訓練データの損失だけが低くても、検証データや本番データで性能が悪ければ、モデルとしてはよい状態とは言えません。
そのため、実務では大域最適解を数学的に厳密に見つけることよりも、検証データで安定して性能が出る十分によい解を見つけることが重視されます。局所最適解を避ける工夫は、そのための手段の一つです。
| 観点 | 局所最適解 | 大域最適解 |
|---|---|---|
| 判断範囲 | 近くの範囲 | 探索対象全体 |
| 損失の状態 | 周辺よりは小さい | 全体で最も小さい |
| 到達しやすさ | 比較的到達しやすい | 複雑な問題では保証が難しい |
| 実務上の扱い | 性能が十分なら採用されることもある | 理想的だが、常に必要とは限らない |
局所最適解への対策
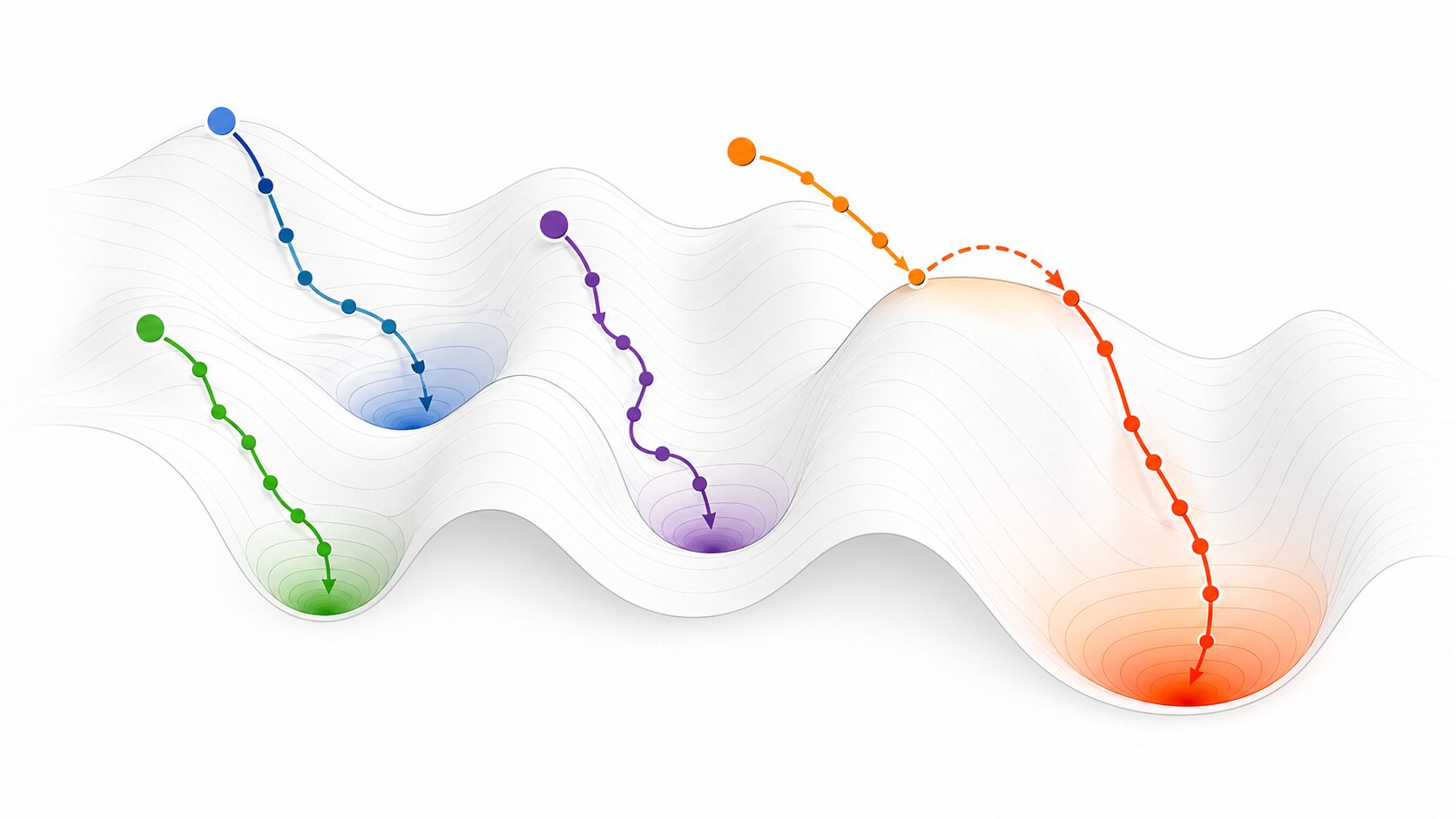
局所最適解を避けるには、一つの方法だけに頼るのではなく、問題に合わせて複数の工夫を組み合わせます。代表的な対策は、学習率の調整、初期値の変更、最適化手法の選択、複数回の学習です。
学習率は、1回の更新でどれくらいパラメータを動かすかを決める値です。学習率が小さすぎると、浅い谷から抜け出しにくくなります。反対に大きすぎると、よい解を飛び越えたり、学習が不安定になったりします。一定値だけでなく、学習の途中で少しずつ下げるスケジュールを使うこともあります。
初期値も重要です。同じモデル、同じデータでも、出発点が変わると到達する解が変わることがあります。複数の初期値で学習し、検証データで最も性能がよいモデルを選ぶ方法は、局所最適解の影響を減らす基本的な対策です。
最適化手法の工夫も有効です。モーメンタムは、過去の更新方向をある程度引き継ぐことで、小さな谷や凹凸の影響を受けにくくします。Adamなどの手法は、パラメータごとに更新幅を調整しながら学習を進めます。ミニバッチ学習では、データの一部を使って勾配を計算するため、更新にほどよい揺らぎが生まれ、悪い場所に固定されにくくなる場合があります。
| 対策 | 狙い | 注意点 |
|---|---|---|
| 学習率を調整する | 浅い谷に止まりにくくし、安定して損失を下げる | 大きすぎると発散し、小さすぎると学習が遅い |
| 初期値を変えて複数回学習する | 別の経路からよりよい解を探す | 計算時間が増える |
| モーメンタムを使う | 過去の進行方向を利用し、小さな凹凸を越えやすくする | 設定によっては振動が大きくなる |
| Adamなどの最適化手法を使う | パラメータごとに更新幅を調整する | 問題によって向き不向きがある |
| 検証データで選ぶ | 訓練データだけでなく未知データへの性能を確認する | 検証データの分け方にも注意が必要 |
実務での考え方
局所最適解は「絶対に避けなければならない失敗」と考えるより、最適化で起こり得る性質として理解する方が実用的です。機械学習では、訓練データ、モデル構造、損失関数、最適化手法、初期値など、多くの要素が結果に影響します。
まず確認したいのは、学習曲線です。訓練損失と検証損失の推移を見ると、学習が進んでいるのか、途中で止まっているのか、過学習しているのかを判断しやすくなります。損失が早い段階で下がらなくなった場合は、学習率や初期値を見直す候補になります。
次に、複数条件で比較することが大切です。学習率、バッチサイズ、初期値、最適化手法を変えて試し、検証データの性能を比較します。局所最適解への対策は、理論上の最良点を探すためだけでなく、再現性のある高性能なモデルを選ぶためにも役立ちます。
また、深層学習では、局所最適解よりも鞍点や平坦な領域、過学習、データの偏りの方が大きな問題になることもあります。局所最適解だけに原因を絞らず、データ品質や評価方法も含めて確認することが重要です。
まとめ
局所最適解とは、近くの範囲では最もよいものの、全体では最善とは限らない解です。機械学習では、損失関数を小さくする最適化の過程で、勾配降下法がこのような点に収束することがあります。
局所最適解を理解するには、大域最適解との違いを押さえることが重要です。大域最適解は全体で最もよい解、局所最適解は周辺で最もよい解です。複雑なモデルでは、どの解に到達するかが初期値や学習率に左右されることがあります。
対策としては、学習率の調整、初期値を変えた複数回の学習、モーメンタムやAdamなどの最適化手法、検証データを使ったモデル選択が有効です。大切なのは、局所最適解を単なる失敗として避けるだけでなく、モデルが未知データに対して安定して性能を出せているかを確認することです。
局所最適解は、機械学習の最適化を理解するための基本概念です。損失関数、勾配降下法、学習率、初期値とあわせて理解すると、モデル学習で何が起きているのかをより正確に読み取れるようになります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2026年4月26日 | 局所最適解の定義、大域最適解との違い、勾配降下法で起きる理由、実務上の対策を整理し、本文構成と図解画像を更新しました。 |