連続値制御:AIによる滑らかな動きの実現

AIの初心者
先生、「連続値制御」って、難しそうでよくわからないです。簡単に説明してもらえますか?

AI専門家
そうだね、難しく感じるかもしれないね。「連続値制御」とは、AIが滑らかに動くために必要な値を調整する技術のことだよ。例えば、ロボットの腕を動かすとき、カクカク動かすのではなく、滑らかに動かしたいよね?そのために、動きの角度や速さを細かく調整する必要があるんだ。この細かい調整をAIに学習させるのが「連続値制御」だよ。
AIの初心者
なるほど。でも、「左に行く」「右に行く」のような指示とは何が違うのですか?
AI専門家
いい質問だね。「左に行く」「右に行く」のような指示は、いくつかの決まった選択肢から選ぶものだよね。一方、ロボットの腕の角度や速さは、自由に細かく調整できる値なんだ。例えば、角度は0度から360度まで、どんな値でも取れる。このような、自由に値を取れるものを「連続値」と呼び、AIに連続値をうまく扱わせる技術が「連続値制御」なんだよ。
連続値制御とは。
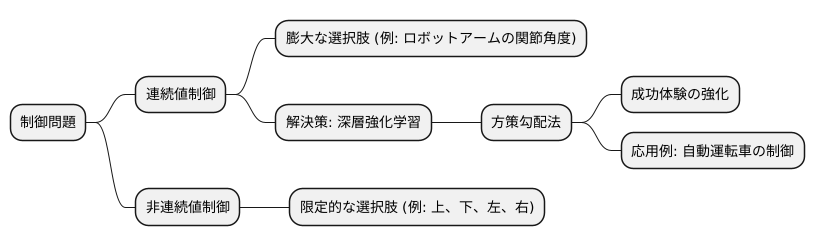
人工知能の分野で、特に深い強化学習という技術において、どのように行動を学ぶかという問題があります。例えば、「左へ行く」「右へ行く」といった行動は、いくつかの決まった選択肢の中から選ぶものなので、とびとびの値として扱われます。一方、速さやロボットの進む角度のように、自由に値を決められるものもあります。このような、滑らかに変化する値を扱う問題を、連続値制御問題と呼びます。
連続値制御とは

計算機に複雑な動作を覚えさせる研究が、特に人工知能の深層強化学習という分野で盛んに行われています。この学習の中で、計算機はどのように行動するべきかを決める必要があります。たとえば、機械仕掛けの人間を動かす場合を考えてみましょう。「前へ進む」「後ろへ下がる」「右へ曲がる」「左へ曲がる」といった選択肢から一つを選ぶような制御方法は、それぞれの行動がはっきりと分けられているため、飛び飛びの値を取る制御と呼ばれます。一方、機械仕掛けの人間の移動の速さや回転の角度のように、滑らかに変化する値を制御する必要がある場合は、連続した値を取る制御と呼ばれる方法が使われます。
連続した値を取る制御は、たとえば自動車の運転のように、アクセルペダルやハンドルの操作を細かく調整することで、速さや方向を自由に変化させることを可能にします。これは、あらかじめ決められた選択肢の中から行動を選ぶ飛び飛びの値を取る制御とは違い、より複雑で繊細な制御を可能にします。たとえば、アクセルペダルをどれくらい踏むか、ハンドルをどれくらい回すかといった操作は連続した値で表現されます。アクセルペダルを少しだけ踏めばゆっくりと加速し、深く踏めば急激に加速します。ハンドルも同様に、少しだけ回せば緩やかに曲がり、大きく回せば急なカーブを曲がることができます。
深層強化学習における連続した値を取る制御は、機械仕掛けの人間を作る技術や自動運転技術の発展に欠かせない要素です。この技術によって、計算機は人間の行動をより精密に模倣し、滑らかで自然な動きを実現することができます。たとえば、自動運転車の場合、連続した値を取る制御によって、周りの車の動きや道路状況に合わせて、スムーズな加減速や車線変更を行うことが可能になります。また、機械仕掛けの人間も、連続した値を取る制御によって、人間のように滑らかに歩き、繊細な動作を行うことができるようになるでしょう。このように、連続した値を取る制御は、計算機に複雑な動作を学習させ、より人間に近い動きを実現するための重要な技術です。
| 制御の種類 | 説明 | 例 |
|---|---|---|
| 飛び飛びの値を取る制御 | はっきりと分けられた行動の選択肢から一つを選ぶ制御方法 | 機械仕掛けの人間:「前へ進む」「後ろへ下がる」「右へ曲がる」「左へ曲がる」 |
| 連続した値を取る制御 | 滑らかに変化する値を制御する方法 | 機械仕掛けの人間の移動速度、回転角度、自動車のアクセル、ハンドル操作 |
課題と解決策

連続的な値を扱う制御の問題は、非連続的な値を扱う制御に比べて、格段に難しいものです。なぜなら、連続値制御では、膨大な選択肢の中から最適な行動を見つけ出す必要があるからです。例えば、ロボットアームの制御を考えてみましょう。ロボットアームの関節は、滑らかに、無段階に角度を変えることができます。このため、アーム全体で見ると、取ることができる姿勢は事実上無限に存在します。目的とする動作を実現するために、それぞれの関節を何度に曲げれば良いのか、その最適な組み合わせを見つけることは、大変な計算を必要とします。
非連続値制御では、例えば、選択肢が「上、下、左、右」のように限られているため、比較的簡単に最適な行動を見つけ出すことができます。しかし、連続値制御では、選択肢が「0度から360度までの任意の角度」のように無数に存在するため、最適な行動を見つけるのが難しくなります。これは、広い砂浜から、特定の1粒の砂を探し出すようなものです。
この難しい連続値制御の問題を解決するために、深層強化学習という技術が使われます。深層強化学習は、人間の学習方法と似た方法で、機械に学習させる技術です。具体的には、方策勾配法という手法がよく用いられます。方策勾配法は、機械に何度も試行錯誤をさせ、成功体験を強化することで学習を進めます。ちょうど、子供が自転車に乗る練習をするように、最初はうまくいかなくても、何度も練習することで徐々に上達していくように、機械も学習していきます。
方策勾配法は、複雑な連続値制御問題を解くのに効果的であることが確認されており、ロボットの制御や自動運転技術など、様々な分野で応用が期待されています。例えば、自動運転車の場合、ハンドル操作やアクセル、ブレーキ操作を連続的に制御する必要があるため、方策勾配法を用いた深層強化学習が有効です。このように、方策勾配法は、複雑な制御問題を解決するための、強力な手法として注目を集めています。
応用例

連続値制御は、私たちの身の回りの様々な場面で活躍しています。まるで人間が滑らかに手を動かすように、機械や装置を精密に操る技術であり、実社会における応用範囲は多岐に渡ります。
例えば、工場などで働くロボットアームを考えてみましょう。ロボットアームは、物体を掴む、持ち上げる、特定の位置に置くといった動作を連続的に行います。この時、それぞれの動作を滑らかに、かつ正確に行うためには、連続値制御が欠かせません。急な動きやぎこちない動作は、対象物を壊したり、作業効率を低下させたりする可能性があります。連続値制御によって、ロボットアームは人間のように繊細な作業をこなせるようになるのです。
また、自動車の自動運転技術においても、連続値制御は重要な役割を担っています。アクセルやブレーキ、ハンドル操作を適切に調整することで、スムーズな加減速や車線変更を可能にします。人間が運転するように、周囲の状況に合わせて速度や方向を細かく制御することで、安全で快適な自動運転を実現できるのです。
さらに、エンターテイメントの世界でも連続値制御は活用されています。ゲームのキャラクターを自然に動かす、仮想空間でリアルな動きを再現するなど、私たちの目を楽しませる表現を支えています。例えば、格闘ゲームでキャラクターが流れるような攻撃を繰り出すのも、連続値制御によるものです。
このように、連続値制御は、機械や装置を思い通りに動かすための重要な技術です。ロボットの制御、自動運転、エンターテイメントなど、様々な分野で応用され、私たちの生活をより豊かに、そして便利にしています。今後ますます発展が期待される技術と言えるでしょう。
| 分野 | 適用例 | 効果 |
|---|---|---|
| 産業ロボット | ロボットアームによる物体の把持、移動、配置 | 滑らかで正確な動作、作業効率向上、繊細な作業 |
| 自動運転 | アクセル、ブレーキ、ハンドル操作の調整 | スムーズな加減速、車線変更、安全で快適な運転 |
| エンターテイメント | ゲームキャラクターの自然な動作、仮想空間でのリアルな動きの再現 | 流れるような動き、リアルな表現 |
将来展望

将来展望についてお話します。深層強化学習を用いた連続値制御という技術は、現在盛んに研究開発が行われている分野です。この技術は、複雑な動きをスムーズに制御できるという特徴を持っています。例えば、ロボットの腕を滑らかに動かす、自動車の速度を微妙に調整するといった、人間にとっては簡単な動作も、機械にとっては難しい制御が必要になります。この難しい制御を、深層強化学習によって実現しようという試みが、連続値制御です。
現在、この分野では、より高度な制御方法の開発が進められています。より正確に、より速く、より複雑な動作を制御できるアルゴリズムの開発が期待されています。また、学習効率の向上も重要な課題です。深層強化学習は、大量のデータと計算時間を必要とするため、学習効率を上げることで、より早く、より少ない資源で、高度な制御を実現できるようになります。
さらに、この技術は、様々な分野への応用が期待されています。例えば、人間のように器用な動きをするロボットの開発です。工場での作業だけでなく、家事や介護など、様々な場面で活躍するロボットの実現に貢献すると考えられます。また、複雑な道路状況でも安全に走行できる自動運転システムの実現も期待されています。天候や交通状況の変化に柔軟に対応できる自動運転車は、交通事故の減少や交通渋滞の緩和につながる可能性を秘めています。
その他にも、深層学習モデルの学習に必要なデータ量を減らす研究や、学習過程を安定させるための研究も進められています。これらの研究は、連続値制御の適用範囲をさらに広げることにつながり、より高度な人工知能の実現に貢献すると期待されています。つまり、連続値制御は、私たちの生活を大きく変える可能性を秘めた、大変重要な技術と言えるでしょう。
| 技術 | 特徴 | 現状と課題 | 将来展望 |
|---|---|---|---|
| 深層強化学習を用いた連続値制御 | 複雑な動きをスムーズに制御できる |
|
|
まとめ

複雑な連続動作を学習できる深層強化学習は、人工知能の分野で注目されている技術です。特に、連続値制御という手法は、滑らかな動きの実現に重要な役割を果たします。
この技術は、ロボットの制御や自動運転、そしてゲームなど、多様な分野で応用されています。例えば、ロボットアームは、この技術によって複雑な動きを滑らかに制御できるようになり、工場の自動化などに役立っています。また、自動運転車においては、ハンドル操作や速度調整などを人間のドライバーのように滑らかに行うために必要不可欠な技術となっています。さらに、ゲームの世界では、キャラクターの自然でリアルな動きを実現するために活用され、ゲーム体験をより豊かにしています。
深層強化学習における連続値制御は、現在も盛んに研究開発が行われている分野です。研究者たちは、より高度な制御方法の開発や、学習にかかる時間や計算資源を減らすための効率的な学習方法の開発に取り組んでいます。これらの研究開発によって、将来的には、より人間に近い滑らかで複雑な動作を人工知能が実現できるようになると期待されています。
人工知能がより複雑な動作を滑らかに行えるようになれば、私たちの生活は大きく変わっていくでしょう。例えば、介護ロボットが人間の動作をより精密に模倣できるようになり、高齢者の生活支援をより効果的に行うことができるようになるかもしれません。また、家事ロボットが様々な家事をより器用にこなせるようになることで、家事労働の負担を軽減できる可能性もあります。さらに、複雑な作業を自動化できるようになり、生産性の向上に大きく貢献することも期待されます。このように、深層強化学習における連続値制御技術は、私たちの未来をより豊かで便利なものに変えていく可能性を秘めているのです。
| 技術 | 概要 | 応用分野 | 将来の展望 |
|---|---|---|---|
| 深層強化学習における連続値制御 | 複雑な連続動作を学習できる人工知能技術。滑らかな動きの実現に重要。 | ロボット制御(ロボットアームなど)、自動運転(ハンドル操作、速度調整など)、ゲーム(キャラクターの自然な動き) | より高度な制御方法、効率的な学習方法の開発。人間に近い滑らかで複雑な動作の実現。 |
| 深層強化学習における連続値制御の応用 | 人工知能がより複雑な動作を滑らかに行えるようになることで、様々な分野で応用が可能に。 | 介護ロボットによる高齢者支援、家事ロボットによる家事負担軽減、複雑な作業の自動化による生産性向上 | 生活の質の向上、より豊かで便利な未来の実現。 |