 アルゴリズム
アルゴリズム 時系列分析とは?意味・仕組み・活用例をわかりやすく解説
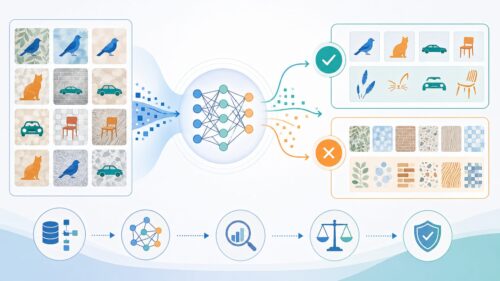
時系列分析とは、時間とともに変化するデータ、すなわち時間の経過とともに順序立てて記録されたデータの並びを詳しく調べる方法です。このデータの並びのことを時系列データと呼びます。たとえば、毎日の気温の変化や毎月の商品の売り上げ金額、毎年の会社の株価、一日の間に変わる心臓の鼓動の数など、様々なものが時系列データとして扱われます。時系列データの特徴は、データが時間の流れに沿って並んでおり、この順番が分析を行う上で非常に重要だということです。普通のデータ分析のように、順番を入れ替えて計算してしまうと、正しい結果が得られません。
時系列分析を行う主な目的は、データの中に隠れている規則性や全体的な流れ、そして繰り返す動きを見つけることです。そして、これらの情報をもとに、将来の値がどのようになるか予測したり、普段とは違う値を見つけて問題を早期に発見したりします。
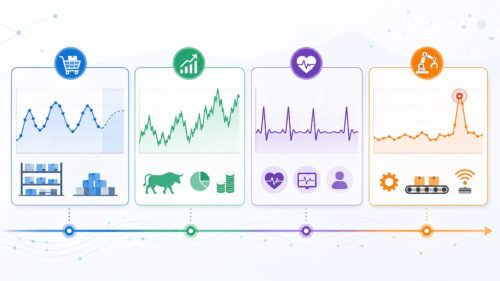
この分析方法は、様々な分野で役に立ちます。例えば、会社の経営判断に必要な情報を得るために使われます。将来の商品の売れ行きを予測することで、適切な量の在庫を確保し、無駄を減らすことができます。また、株価の上がり下がりを予測することで、より効果的な投資計画を立てることができます。
医療の分野でも、この分析方法は活用されています。たとえば、入院している人の体温や血圧など、刻々と変化する体の状態を示すデータから、病気が悪化する兆候を早期に見つけることができます。
環境問題についても、時系列分析は役立ちます。大気汚染の程度を示すデータの変化を分析することで、汚染の原因を探ったり、効果的な対策を考えたりすることができます。このように、時系列分析は、時間とともに変化する様々な現象を理解し、未来を予測するための強力な道具なのです。