LLM
LLM 言葉の魔法:言語モデルの世界
私たちが言葉を話す時、そこには無意識のうちに従っている法則が存在します。まるで重力の法則のように、言葉と言葉の間には見えない糸が張り巡らされており、その糸に導かれるように言葉は紡がれていきます。「おはよう」の後には「ございます」が、そして「こんにちは」の後には「お元気ですか」が続くように、自然と感じる言葉の繋がりがあるのです。これは偶然ではなく、私たちが長い時間をかけて言語を学ぶ中で、言葉の並び方の規則性を無意識のうちに習得してきた結果です。
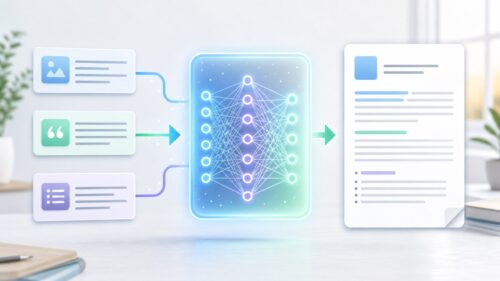
この言葉の並びの規則性、言い換えれば言葉の繋がり方を、膨大な量の文章データから学習するのが言語モデルです。まるで言葉を操る魔法使いのように、言語モデルは次に来る言葉を予測します。例えば、「今日は」という言葉の後に続く言葉として、「良い天気ですね」や「何曜日ですか」といった候補を、過去の膨大なデータに基づいて選び出すのです。言語モデルは、文脈を理解し、それにふさわしい言葉を生成することで、まるで人間のように自然な文章を作り出すことができます。これは、私たちが日常的に行っている言葉のやり取りを、機械で再現するための重要な一歩です。
言語モデルの学習は、辞書を引くような単純な作業ではありません。辞書には言葉の意味は載っていますが、言葉同士の繋がり方までは示されていません。言語モデルは、膨大な文章データを読み込むことで、言葉の意味だけでなく、言葉同士の関係性や、ある言葉の後にどの言葉が続く可能性が高いかといった、複雑な情報を学習しています。この学習を通して、人間が言葉を使う際の微妙なニュアンスや、言葉の奥深さを理解しようと試みているのです。そして、この技術は機械翻訳や文章生成など、様々な分野で応用され、私たちの生活をより豊かにする可能性を秘めています。