L1ノルム損失とは?機械学習で使う平均絶対誤差をわかりやすく解説

AIの初心者
「L1ノルム損失」って何ですか?名前だけ見ると難しく感じます。

AI専門家
簡単に言えば、AIの予測と実際の値がどれくらいずれたかを平均で見る方法だよ。例えば気温を25度と予測して実際が28度なら、ずれは3度。そのずれを複数のデータで集めて平均したものがL1ノルム損失なんだ。
AIの初心者
ずれの平均なんですね。では、なぜ「ノルム」という言葉が付くのでしょうか?
AI専門家
ノルムは、数学で「大きさ」を測るための考え方だよ。L1ノルムでは誤差の絶対値を足し合わせるので、予測が正解からどれだけ離れているかを素直に測れるんだ。
L1ノルム損失とは。
L1ノルム損失は、機械学習で予測値と実測値のずれを測る損失関数です。統計や機械学習では平均絶対誤差(MAE)とも呼ばれ、外れ値に強い評価指標としてよく使われます。
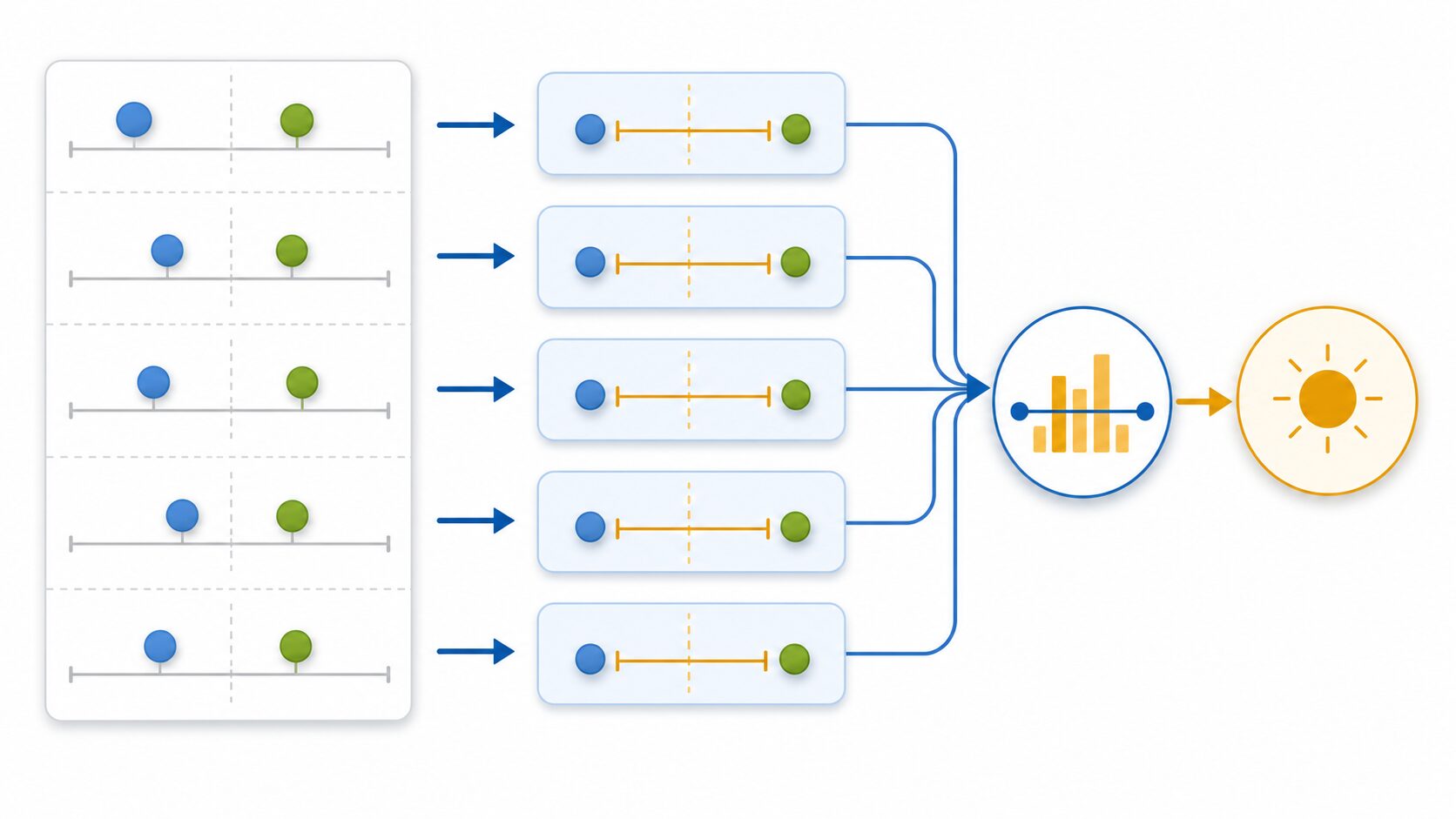
損失関数とは何を測るものか
機械学習では、モデルが出した予測と正解の差を数値で表し、その差が小さくなるように学習を進めます。この差を測る物差しが損失関数です。損失が小さいほど、モデルの予測は正解に近いと判断できます。
例えば、明日の気温を予測するモデルが「25度」と答え、実際の気温が「28度」だった場合、予測は3度ずれています。損失関数は、このようなずれを1件ずつ評価し、モデルをどの方向に調整すべきかを決めるための基準になります。
損失関数には多くの種類があります。連続値を予測する回帰問題では、L1ノルム損失やL2ノルム損失が代表的です。どちらも誤差を扱いますが、誤差の扱い方が違うため、外れ値への反応や学習の進み方に差が出ます。
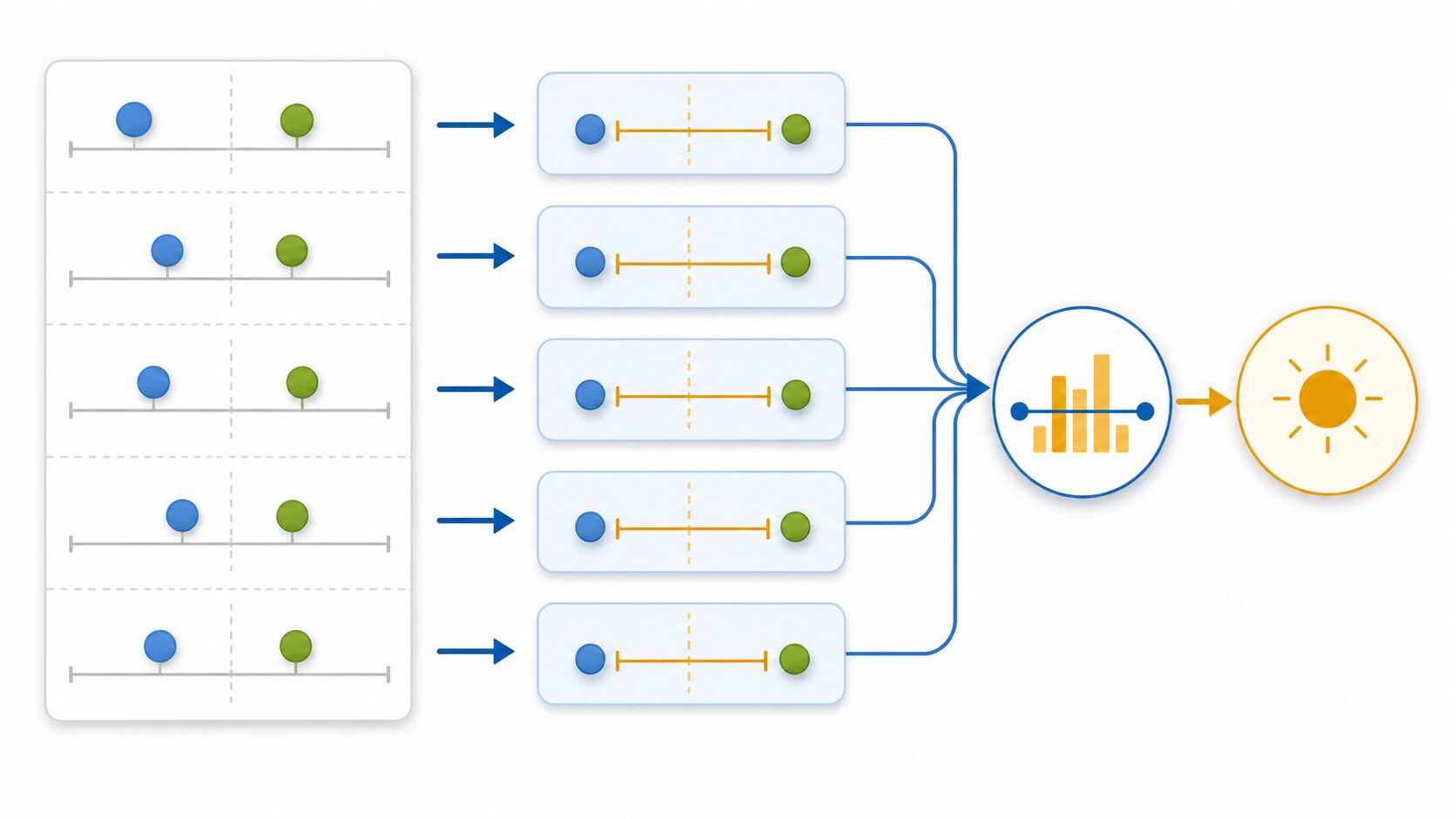
L1ノルム損失の定義とMAEとの関係
L1ノルム損失は、各データについて「予測値と実測値の差」を求め、その絶対値を平均したものです。絶対値を使うため、予測が実測値より大きくても小さくても、ずれの大きさだけを評価できます。
数式で表すと、データ数を n、実測値を y_i、予測値を \hat{y}_i としたとき、L1ノルム損失は次のように書けます。
\frac{1}{n}\sum_{i=1}^{n}|y_i-\hat{y}_i|
\)
この式は、平均絶対誤差(Mean Absolute Error、MAE)としても知られています。厳密には「L1ノルム」は絶対値の総和を指す文脈でも使われますが、機械学習の損失関数として説明されるときは、平均を取ったMAEの形で扱われることが多くあります。
ここで重要なのは、誤差のプラスとマイナスを打ち消さないことです。例えば、ある予測で+5、別の予測で-5の誤差が出た場合、単純に平均すると0になってしまいます。しかしL1ノルム損失ではどちらも5として扱うため、モデルが実際には大きく外していることを見逃しません。
L1ノルム損失の計算方法
L1ノルム損失の計算は、初心者でも追いやすい手順で行えます。まず各データについて予測値と実測値の差を出し、次にその差の絶対値を取り、最後に平均します。
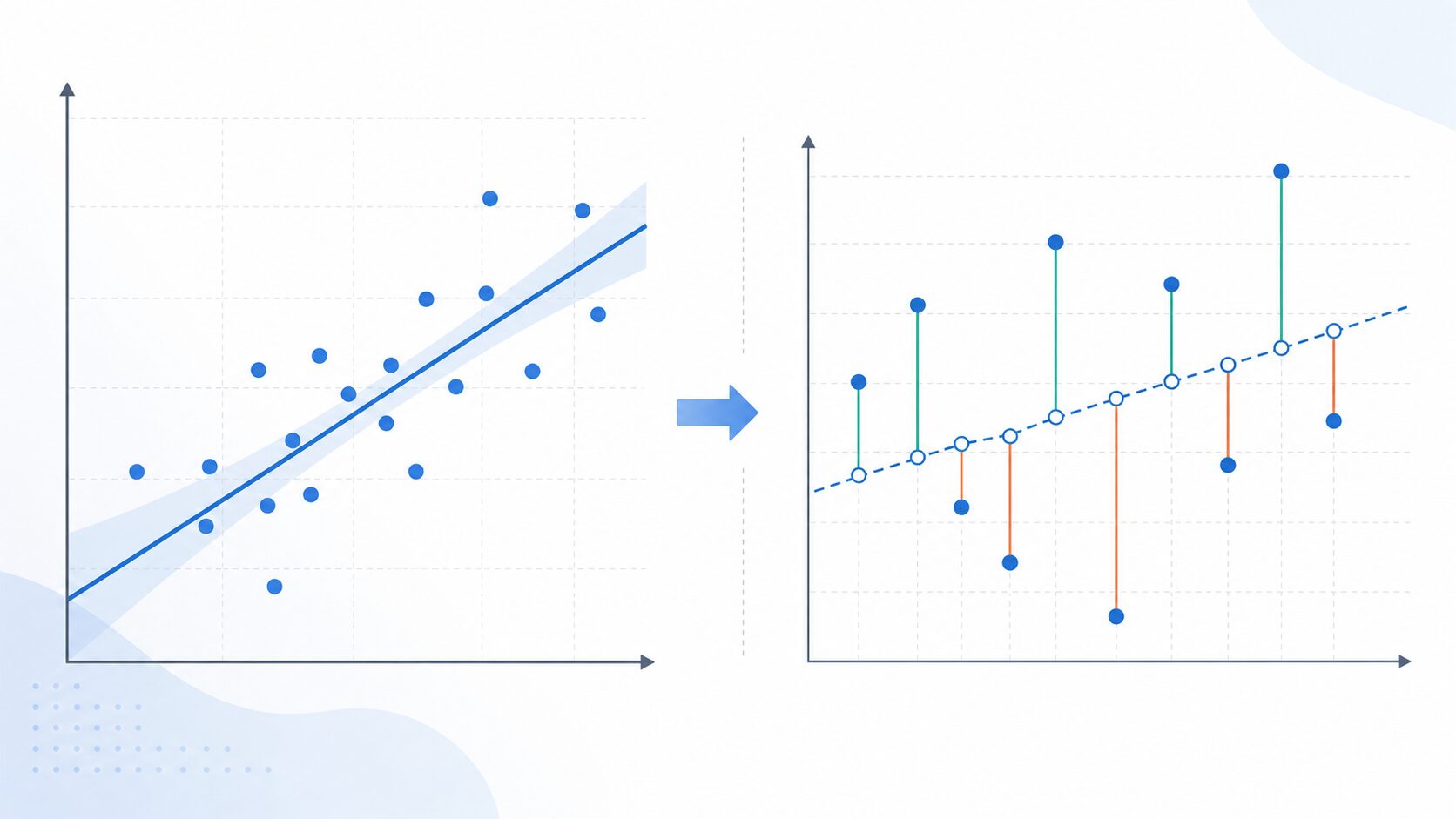
例として、3つの商品の売上予測を考えます。予測値が100、80、60で、実測値が90、100、55だったとします。このとき誤差は10、-20、5です。絶対値を取ると10、20、5になり、合計は35です。データが3件なので、35を3で割った約11.7がL1ノルム損失になります。
| データ | 予測値 | 実測値 | 誤差の絶対値 |
|---|---|---|---|
| 1 | 100 | 90 | 10 |
| 2 | 80 | 100 | 20 |
| 3 | 60 | 55 | 5 |
この値は「予測が平均して約11.7だけ外れている」と読むことができます。単位も元のデータと同じなので、売上個数なら個数、気温なら度、価格なら円として直感的に解釈しやすい点もL1ノルム損失の利点です。
L2ノルム損失との違い
L1ノルム損失とよく比較されるのが、L2ノルム損失です。L2ノルム損失は、誤差を二乗してから平均する損失関数で、平均二乗誤差(MSE)とも呼ばれます。
違いの中心は、大きな誤差への反応です。L1ノルム損失では誤差10は誤差1の10倍として扱われます。一方、L2ノルム損失では誤差10を二乗して100として扱うため、大きな誤差が損失全体に強く影響します。
| 項目 | L1ノルム損失 | L2ノルム損失 |
|---|---|---|
| 計算方法 | 誤差の絶対値を平均する | 誤差の二乗を平均する |
| 別名 | 平均絶対誤差、MAE | 平均二乗誤差、MSE |
| 外れ値の影響 | 比較的受けにくい | 強く受けやすい |
| 最適化 | ゼロ付近で扱いに注意が必要 | 滑らかで扱いやすい場面が多い |
| 向いている場面 | 外れ値やノイズが混ざるデータ | 大きな誤差を強く減らしたいデータ |
どちらが常に優れている、という関係ではありません。外れ値に過剰に引っ張られたくない場合はL1ノルム損失が有力です。一方で、大きな誤差を強く罰したい場合や、滑らかな損失関数として最適化しやすい性質を重視する場合はL2ノルム損失が向いています。
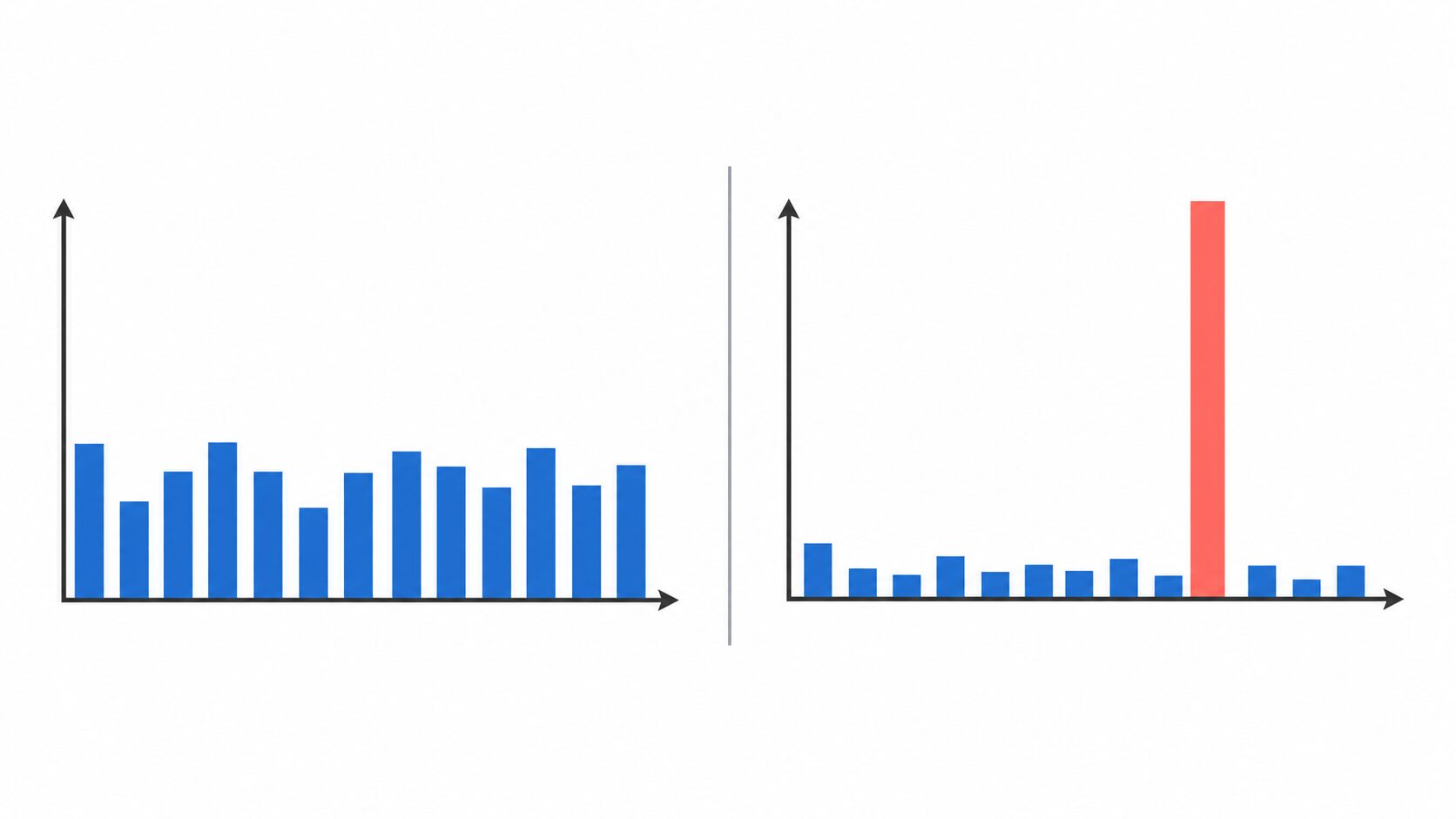
L1ノルム損失が外れ値に強い理由
ロバスト性とは、データにノイズや異常値が混ざっても結果が大きく崩れにくい性質のことです。L1ノルム損失は、誤差を絶対値として扱うため、外れ値の影響が線形に増えます。
例えば、ほとんどのデータの誤差が1前後で、1件だけ誤差が100のデータが混ざっているとします。L2ノルム損失では100を二乗して10000として扱うため、その1件が学習全体を大きく左右します。L1ノルム損失では100は100のままなので、影響は大きいものの、二乗ほど極端にはなりません。
この性質は、計測ミス、入力ミス、突発的な市場変動、センサーの一時的な乱れなどが混ざる現実のデータで役立ちます。ただし、外れ値に強いからといって外れ値を確認しなくてよいわけではありません。外れ値が単なる誤記なのか、重要な異常のサインなのかは、データの背景を見て判断する必要があります。
L1ノルム損失が使われる場面
L1ノルム損失は、回帰問題で予測値と実測値のずれを評価したいときに使われます。特に、データに外れ値やノイズが含まれやすく、極端な値にモデルを引っ張られすぎたくない場面で有効です。
金融分野では、株価や需要のように突発的な変動が起きるデータを扱います。L2ノルム損失を使うと、一時的な急変を過大に重視することがありますが、L1ノルム損失なら通常の傾向を比較的保ちながら学習できます。
医療やセンサーデータでも、測定ノイズや一時的な異常値は珍しくありません。診断支援、設備監視、故障予測などでは、異常値に反応しすぎず、かつ全体の傾向を捉えることが重要です。L1ノルム損失は、そのようなデータで安定した評価指標になりやすい選択肢です。
使うときの注意点
L1ノルム損失には、誤差がゼロになる点で微分できないという注意点があります。多くの機械学習の最適化では勾配を使うため、この性質が実装や学習の安定性に影響する場合があります。
実務では、L1とL2の中間的な性質を持つHuber損失が使われることもあります。Huber損失は、小さい誤差にはL2のように滑らかに反応し、大きい誤差にはL1のように外れ値の影響を抑えるため、両者の折衷案として検討されます。
また、L1ノルム損失とL1正則化は同じものではありません。どちらも絶対値を使う点では関連しますが、L1ノルム損失は予測誤差を測るためのものです。一方、L1正則化はモデルの重みを制約し、不要な特徴量の影響を小さくするために使われます。
まとめ
L1ノルム損失は、予測値と実測値の差の絶対値を平均する損失関数です。平均絶対誤差(MAE)とも呼ばれ、単位が元データと同じなので解釈しやすく、外れ値の影響を受けにくいという特徴があります。
L2ノルム損失は大きな誤差を強く罰するため、最適化しやすい場面や大きな誤差を重視したい場面で有効です。一方、L1ノルム損失は外れ値やノイズが混ざりやすい現実のデータで安定した判断をしやすくなります。
損失関数を選ぶときは、データに外れ値があるか、大きな誤差をどの程度重視したいか、最適化の扱いやすさをどう考えるかを確認することが大切です。L1ノルム損失は、その判断軸を学ぶうえでも機械学習の基礎として押さえておきたい概念です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月16日 | MAEとの関係、L2比較、外れ値への強さを追記 |