
αβ法とは?ミニマックス探索を効率化する枝刈りの仕組み

AIの初心者
「αβ法」って難しそうですが、簡単に言うとどんな方法ですか?

AI専門家
ゲームで最善の手を探すときに、結果に影響しないと分かった手順を途中で調べないようにする方法だよ。将棋やチェスで、明らかに相手を有利にする変化を最後まで読まない感覚に近いね。
AIの初心者
どうして、まだ調べていない手を省いてよいと判断できるんですか?
AI専門家
すでに見つかった良い手や悪い手を基準にして、「この先を読んでも選ばれない」と分かる枝を止めるんだ。その判断に使うのがα値とβ値で、打ち切り方をαカット、βカットと呼ぶよ。
αβ法とは。
αβ法は、ゲームAIでよく使われる探索アルゴリズムです。ミニマックス法の考え方を土台にしながら、最終的な選択に影響しない枝を途中で打ち切ります。
すべての手を最後まで調べるのではなく、すでに分かっている評価値を利用して「これ以上調べても結論が変わらない」と判断します。この枝刈りによって、同じ結果を保ったまま探索量を減らせる点が大きな特徴です。
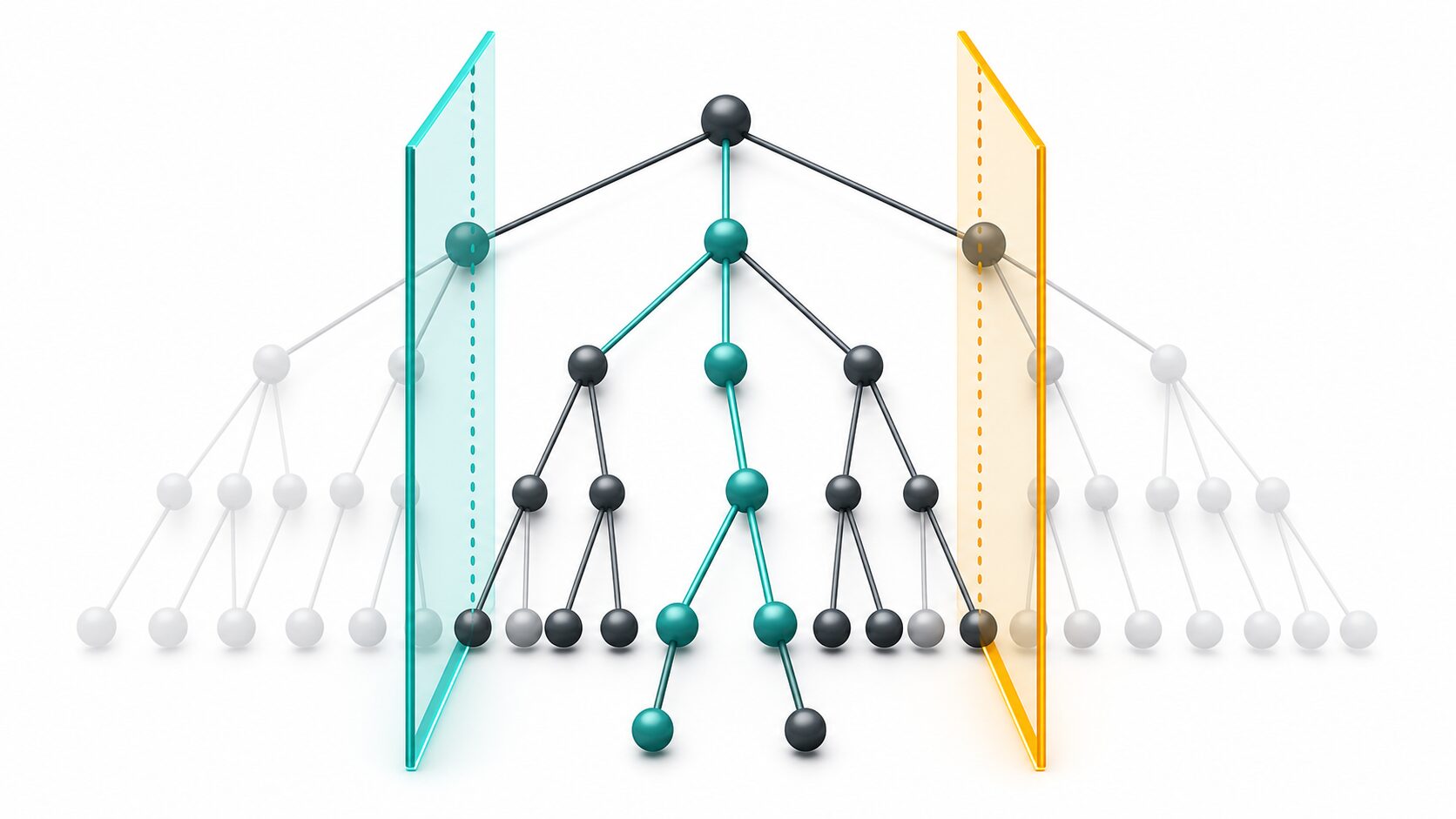
αβ法とは何か
αβ法は、ミニマックス法の探索を効率化する枝刈りの手法です。チェス、将棋、オセロ、三目並べのように、自分と相手が交互に手を選び、勝敗や得点が決まるゲームで説明されることが多いアルゴリズムです。
ミニマックス法では、自分は評価値が高くなる手を選び、相手は自分にとって評価値が低くなる手を選ぶと仮定します。つまり、自分は最大化、相手は最小化を行うものとしてゲーム木を下から評価します。
ただし、ゲーム木をすべて調べると計算量が急激に増えます。そこでαβ法では、探索中に得られた下限と上限を使い、残りの枝を調べても親ノードの値が変わらない場面で探索を止めます。これは近似的に手を抜く方法ではなく、正しく枝刈りできればミニマックス法と同じ最善手を返すのが重要な点です。
ミニマックス法でなぜ探索量が増えるのか
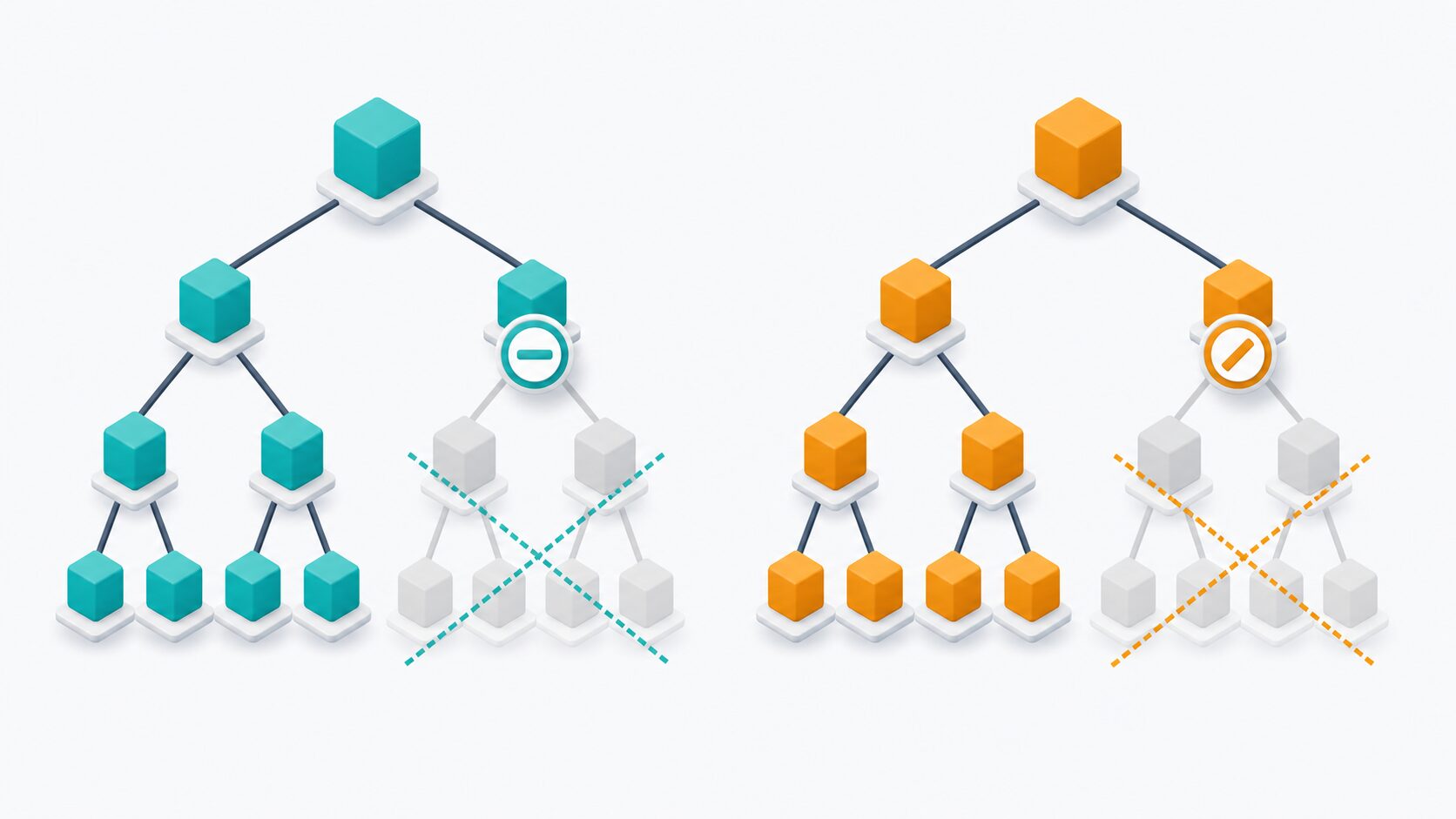
ゲームAIは、現在の盤面から次に選べる手を枝として広げ、その先で相手が選べる手、さらに自分が選べる手を順に調べます。このような分岐の集まりをゲーム木と呼びます。
一手ごとに平均して \(b\) 通りの選択肢があり、\(d\) 手先まで読む場合、単純な探索で調べる局面数はおおまかに \(b^d\) まで増えます。たとえば各局面で3通りの手があり、5手先まで読むなら \(3^5=243\) 通り、10手先なら \(3^{10}=59049\) 通りです。
実際の将棋やチェスでは候補手がさらに多くなります。読む深さを少し伸ばすだけで局面数が爆発的に増えるため、すべてを評価する方法だけでは現実的な時間内に良い手を選びにくくなります。αβ法は、この問題を「結果に影響しない枝を読まない」という発想で軽くします。
| 方法 | 考え方 | 弱点 |
|---|---|---|
| ミニマックス法 | 自分は最大、相手は最小の評価値を選ぶとして全体を評価する | 候補手と探索深さが増えるほど計算量が大きくなる |
| αβ法 | ミニマックス法の結論を変えない範囲で不要な枝を打ち切る | 良い探索順序でないと枝刈り効果が小さくなる |
α値とβ値の考え方

αβ法の中心になるのが \(\alpha\) と \(\beta\) です。どちらも探索中に更新される境界値で、今見ている枝をこれ以上調べる価値があるかを判断するために使います。
\(\alpha\) は、自分がすでに確保できると分かっている評価値の下限です。最大化する側から見ると、「少なくともこの値以上の手は見つかっている」という基準になります。一方、\(\beta\) は、相手側が許す評価値の上限です。最小化する側から見ると、「これより悪い結果を選ぶ必要はない」という基準として働きます。
探索中に \(\alpha\) が \(\beta\) 以上になった場合、その先を調べても親の選択は変わりません。この状態を手がかりに枝を切ることで、評価する局面を減らします。
| 値 | 意味 | 直感的な見方 |
|---|---|---|
| \(\alpha\) | 最大化側がこれまでに確保できると分かった下限 | 自分にとって、少なくともこの程度は取れるという基準 |
| \(\beta\) | 最小化側がこれまでに許す上限 | 相手が、これ以上自分を有利にしないという基準 |
| 枝刈り条件 | \(\alpha \ge \beta\) になったら残りの枝を省ける | この先を読んでも選択が変わらない |
αカットとβカットの具体例

αカットとβカットは、説明する本や実装の流儀によって呼び方が少し揺れることがあります。初心者は名称だけで覚えるより、最大化ノードと最小化ノードのどちらで、なぜ残りを見なくてよいのかを押さえるほうが理解しやすくなります。
最大化ノードでは、自分にとって評価値が高い手を選びます。ある枝を調べている途中で、その枝の値が相手側の上限 \(\beta\) 以上になると、相手はその手順を選ばせてくれません。したがって、その枝の残りを調べる必要がなくなります。
最小化ノードでは、相手が自分にとって評価値の低い手を選ぶと考えます。ある枝の値が自分側の下限 \(\alpha\) 以下になると、自分はそれより良い選択をすでに持っているため、その枝は親の判断に影響しません。
たとえば、すでに自分が評価値5の手を見つけているとします。別の候補を調べた結果、相手が評価値3に落とせることが分かったなら、その候補をさらに細かく読む必要はありません。自分は評価値5の手を選べばよいからです。このように、相手の最善応答を考えることで「選ばれない枝」を見つけます。
| 場面 | 判断 | 枝刈りできる理由 |
|---|---|---|
| 最大化ノード | より高い評価値を探す | 相手が許さないほど良い値に達した枝は、それ以上読んでも採用されない |
| 最小化ノード | より低い評価値を探す | 自分がすでにもっと良い選択を持つ枝は、親の判断を変えない |
実装に必要な要素
αβ法をプログラムとして動かすには、ゲームの状態を表すデータ、合法手を列挙する処理、手を進めた次の状態を作る処理、局面を数値化する評価関数が必要です。
基本形は再帰関数で書かれることが多く、最大化する手番では候補手の中から最も高い値を選び、最小化する手番では最も低い値を選びます。探索の途中で \(\alpha\) と \(\beta\) を更新し、\(\alpha \ge \beta\) になったら残りの候補を調べずに戻ります。
function alphabeta(state, depth, alpha, beta, maximizing):
if depth == 0 or game_is_over(state):
return evaluate(state)
if maximizing:
value = -infinity
for move in legal_moves(state):
value = max(value, alphabeta(next_state(state, move), depth - 1, alpha, beta, false))
alpha = max(alpha, value)
if alpha >= beta:
break
return value
value = infinity
for move in legal_moves(state):
value = min(value, alphabeta(next_state(state, move), depth - 1, alpha, beta, true))
beta = min(beta, value)
if alpha >= beta:
break
return valueこの疑似コードで重要なのは、枝刈りしても評価の意味が変わらないことです。省略しているのは「結果に関係しない候補」であって、都合よく悪い情報を無視しているわけではありません。
さらに効率化するための工夫
αβ法の効果は、候補手を調べる順序に大きく左右されます。良さそうな手を先に調べると \(\alpha\) や \(\beta\) が早く厳しい値になり、後続の枝を切りやすくなります。逆に悪い順序で調べると、ミニマックス法に近い量を読むこともあります。
実務的には、評価が高そうな手を先に並べるムーブオーダリング、同じ局面の再計算を避ける置換表、浅い探索結果を使って深い探索の順序を決める反復深化などが使われます。これらはαβ法そのものとは別の工夫ですが、組み合わせることで探索速度を大きく改善できます。
また、探索深さを深くすれば必ず強くなるわけではありません。評価関数が局面の良し悪しをうまく表せていなければ、深く読んでも誤った評価を広げるだけになることがあります。ゲームAIでは、探索アルゴリズムと評価関数の両方を調整する必要があります。
学習時につまずきやすい注意点
まず、αβ法は「一部を見ないから精度が落ちる方法」ではありません。正しい条件で枝刈りする限り、ミニマックス法と同じ値を返します。違いは調べる順序と量であり、最終的な判断の基準はミニマックス法と同じです。
次に、\(\alpha\) と \(\beta\) の意味を固定的な「自分の値」「相手の値」とだけ覚えると混乱しやすくなります。実装では、最大化側が更新する下限、最小化側が更新する上限として見ると追いやすくなります。
最後に、αβ法はあらゆるAI問題にそのまま使える万能手法ではありません。特に、相手の行動が確率的なゲーム、情報が隠れているゲーム、複数人が異なる目的で動く問題では、別の探索法や評価方法が必要になることがあります。
まとめ
αβ法は、ミニマックス法の考え方を保ちながら、探索結果に影響しない枝を省くことでゲーム木探索を効率化する方法です。ポイントは、\(\alpha\) と \(\beta\) を使って、これ以上読んでも選択が変わらない場面を見つけることです。
ミニマックス法との関係、α値とβ値の役割、枝刈り条件、探索順序の重要性を押さえると、将棋やチェスのようなゲームAIでなぜαβ法が使われるのかが理解しやすくなります。実装する際は、評価関数や候補手の並べ方も含めて調整すると、より実用的な探索に近づきます。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年6月11日 | 枝刈り条件と実装時の判断ポイントを補い構成を調整 |