AIサービス
AIサービス 画像で探す!類似画像検索の世界
今では、誰もが気軽に写真や絵を撮り、それを共有する時代になりました。その結果、インターネット上には、星の数ほどの画像データが溢れかえっています。これらの画像の中から、探し求めている一枚を見つけるのは、まるで大海原で一粒の真珠を探すようなものです。
従来の方法では、主に言葉を使って画像を探していました。例えば、「赤い花」や「白い猫」といった具合です。しかし、この方法には限界があります。もし、探したいものの名前が分からなかったり、複雑な形をしたものを探したい場合はどうでしょうか。言葉でうまく表現できないため、目的の画像にたどり着くのは困難です。
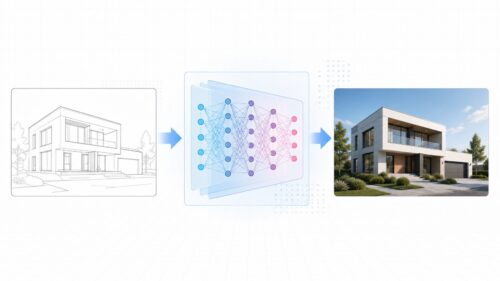
そこで登場するのが、類似画像検索という画期的な方法です。これは、言葉の代わりに画像を使って画像を探す技術です。例えば、赤い花の写真を使って検索すれば、似た色の花や形の花の画像を見つけることができます。まるで、お手本となる絵を見せて、似た絵を探してもらうような感覚です。
近年、この技術は目覚ましい進歩を遂げています。以前は、画像の色や形といった単純な特徴しか捉えることができませんでしたが、今では、画像に写っているものやその状況まで理解できるようになってきています。例えば、夕焼けの海の写真で検索すると、同じような雰囲気の夕焼けの風景や、海の景色が表示されるようになりました。
この技術のおかげで、私たちの生活はより便利で豊かになっています。インターネットショッピングで欲しい商品を見つける時や、旅行先で似た景色を探す時など、様々な場面で活用されています。今後、さらに精度が向上すれば、私たちの生活はさらに便利になることでしょう。