L1正則化:モデルをシンプルにする魔法

AIの初心者
先生、「L1正則化」って、パラメータを減らすことで次元圧縮するって言うけど、どうしてパラメータが減るんですか?

AI専門家
良い質問だね。L1正則化では、損失関数にパラメータの絶対値の和を足したものを最小化しようとするんだ。この「パラメータの絶対値の和」の部分がポイントだよ。
AIの初心者
パラメータの絶対値の和ですか? どうしてそれがパラメータを減らすことに繋がるんでしょう?
AI専門家
例えば、損失関数の値を小さくするためにパラメータを調整するとする。L1正則化がない場合は、パラメータは0ではない小さな値に落ち着くことが多い。しかし、L1正則化がある場合は、パラメータの絶対値を小さくする力が働く。その結果、パラメータが0になりやすく、結果として使われるパラメータの数が減る、つまり次元が圧縮されるんだよ。
L1正則化とは。
人工知能の分野でよく使われる「L1正則化」について説明します。L1正則化とは、モデルが学習しすぎるのを防ぐための手法の一つです。通常、正則化では、損失関数と正則化項の和を最小にするように調整しますが、L1正則化の特徴は、正則化項がパラメータの絶対値の合計で表されることです。そのため、パラメータの値がゼロになりやすく、結果としてパラメータの数が減ります。これは、次元圧縮につながります。
過学習を防ぐ仕組み

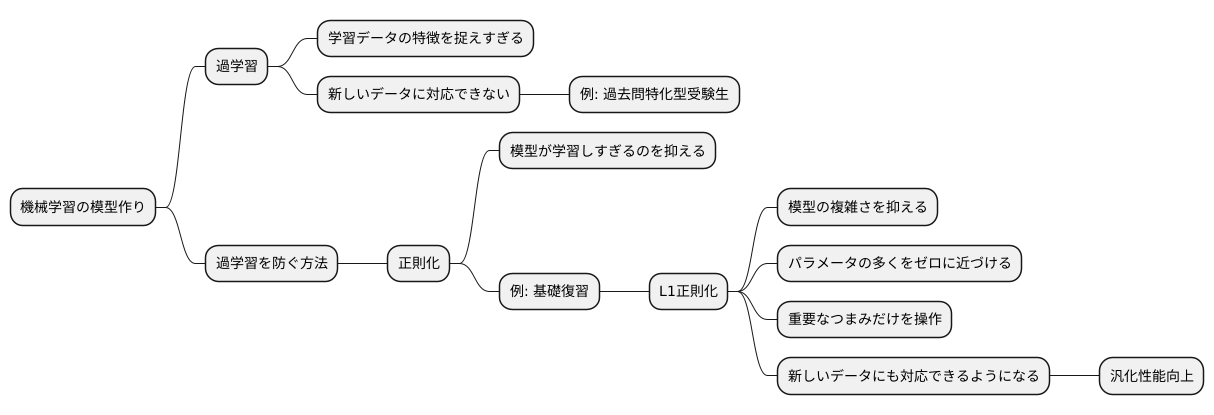
機械学習の模型作りでは、学習しすぎるという問題によく直面します。これは、作った模型が、学習に使ったデータの特徴を捉えすぎることで起こります。例えるなら、特定の年の過去問を完璧に解けるように勉強した受験生が、本番の試験では応用問題に対応できず、良い点数が取れないようなものです。学習に使ったデータでは良い結果が出ても、新しいデータではうまくいかない、これが過学習です。
この過学習を防ぐための方法の一つに、正則化というものがあります。正則化は、模型が学習しすぎるのを抑えるための工夫のようなものです。受験生の例で言えば、過去問だけでなく、教科書の基本的な内容もしっかりと復習させるようなものです。正則化には色々な種類がありますが、中でもL1正則化は強力な手法として知られています。
L1正則化は、模型の複雑さを抑える働きをします。模型を作る際には、たくさんの調整つまみのようなものがあり、これらをパラメータと呼びます。L1正則化は、これらのパラメータの多くをゼロに近づけることで、模型を単純化します。たくさんのつまみを複雑に操作するよりも、重要なつまみだけを操作する方が、模型の動きが分かりやすく、新しいデータにも対応しやすくなります。
このように、L1正則化は、模型が学習データに過度に適応するのを防ぎ、新しいデータにも対応できる能力、すなわち汎化性能を高めるために役立ちます。複雑で扱いにくい模型を、シンプルで扱いやすい模型に変える、まるで魔法の杖のような役割を果たすのです。
正則化項の役割

機械学習では、学習に使うデータに過剰に適合してしまう「過学習」という問題がよく起こります。この過学習を防ぎ、予測精度を高めるための重要な手法の一つに「正則化」があります。正則化は、モデルが複雑になりすぎるのを防ぐ役割を果たします。
正則化を実現するために、「正則化項」と呼ばれる値を損失関数に加えます。損失関数とは、モデルの予測値と実際の値とのずれを表す指標で、この値が小さいほど予測精度が高いことを示します。正則化項は、モデルのパラメータの大きさに関する指標で、この値が大きいほどモデルが複雑であると考えられます。
L1正則化では、正則化項としてパラメータの絶対値の和を用います。損失関数にこの正則化項を加えることで、パラメータの値がゼロに近い値に抑えられます。いくつかのパラメータの値がゼロになることで、モデルが単純化され、過学習が抑制されるのです。
損失関数と正則化項は、モデルの予測精度と複雑さのバランスを保つために重要な役割を果たします。例えるなら、損失関数は料理の味、正則化項は料理の見た目のようなものです。味が良いだけでなく、見た目も美しく整っていることが理想的です。正則化項の重みは、料理の味付けのさじ加減のようなもので、この重みを調整することで、予測精度とモデルの複雑さのバランスを調整し、最適なモデルを作ることができます。重みが小さいとモデルは複雑になりやすく、重みが大きいとモデルは単純になりやすいです。
適切な重みを見つけることは、高精度な予測モデルを作る上で非常に重要です。様々な重みを試して、最適なバランスを見つける必要があります。データの性質やモデルの構造によって最適な重みは異なるため、試行錯誤しながら調整していくことが求められます。
| 用語 | 説明 | 例え |
|---|---|---|
| 過学習 | 学習データに過剰に適合し、新しいデータへの予測精度が低下する問題 | – |
| 正則化 | 過学習を防ぎ、予測精度を高める手法。モデルが複雑になりすぎるのを防ぐ。 | – |
| 正則化項 | モデルの複雑さを表す指標。損失関数に加える。 | 料理の見た目 |
| 損失関数 | モデルの予測値と実際の値のずれを表す指標。小さいほど予測精度が高い。 | 料理の味 |
| L1正則化 | 正則化項としてパラメータの絶対値の和を用いる正則化手法。 | – |
| 正則化項の重み | モデルの複雑さと予測精度のバランスを調整するパラメータ。 | 味付けのさじ加減 |
パラメータを減らす

多くの場合、機械学習のモデルは、複雑になればなるほど正確になると考えられています。しかし、あまりに複雑なモデルは、過学習という問題を引き起こし、新しいデータに対してうまく対応できなくなってしまいます。そこで、モデルをシンプルにするための様々な工夫が凝らされています。その一つが正則化という手法で、正則化には様々な種類がありますが、L1正則化はモデルをシンプルにするための強力な手法です。
L1正則化は、モデルのパラメータにペナルティを科すことで、モデルの複雑さを抑えます。具体的には、パラメータの絶対値の合計を損失関数に加えます。このペナルティにより、L1正則化は他の正則化手法とは異なり、パラメータを単に0に近づけるだけでなく、完全に0にすることができます。まるで彫刻家がノミで石を削るように、不要なパラメータを削ぎ落としていくのです。
パラメータが0になるということは、そのパラメータに対応する変数はモデルにとって重要ではないということを意味します。つまり、L1正則化は、モデルにとって本当に必要な変数だけを残し、不要な変数を排除する役割を果たします。これにより、モデルのパラメータ数が減少し、モデルがシンプルになります。
モデルがシンプルになると、いくつかの利点が生まれます。まず、計算量が減り、処理速度が向上します。次に、モデルの解釈性が向上します。複雑なモデルは、なぜその予測結果になったのかを理解するのが難しいですが、シンプルなモデルであれば、どの変数がどれくらい影響を与えているのかを把握しやすくなります。また、過学習のリスクを減らし、新しいデータに対しても安定した予測が可能になります。
このように、L1正則化は、まるで不要な枝葉を切り落とす剪定のように、モデルをシンプルで美しく整え、より良い予測を実現するための強力な手法と言えるでしょう。

次元圧縮の効果

たくさんの情報を持つデータは、時に扱うのが大変です。まるでたくさんの荷物を持った旅行者のようです。必要なものもあれば、そうでないものもあります。次元圧縮は、このたくさんの荷物から本当に必要なものだけを選び出す、整理整頓のような作業です。
データが持つ情報の量は、次元と呼ばれる数値で表されます。次元が多いほど、情報は豊富ですが、同時に不要な情報、いわゆる雑音も多くなります。この雑音は、データの全体像をぼやけさせ、コンピュータにとっても大きな負担となるのです。次元圧縮は、この雑音を減らし、本当に必要な情報だけを残すことで、データの見通しを良くする技術です。
次元を減らす方法はいくつかありますが、その一つにL1正則化と呼ばれる方法があります。L1正則化は、まるで魔法の箒のように、データの中に潜む不要な情報を一掃してくれます。具体的には、データの特徴を表す数値をいくつか0にすることで、情報の量を減らします。数値が0になるということは、その情報が不要であると判断されたことを意味します。
L1正則化を用いることで、データの整理整頓だけでなく、コンピュータの負担も軽減できます。なぜなら、扱う情報が減るため、計算に要する時間が短縮されるからです。さらに、雑音が減ることで、データの本質的な部分がより鮮明になり、分析の精度も向上します。まるで旅行者が不要な荷物を捨てて身軽になるように、データも次元圧縮によって軽くなり、より扱いやすくなるのです。
このように、次元圧縮は、データ分析において非常に重要な役割を果たします。高次元データの課題を解決し、より効率的で精度の高い分析を実現する、まさに魔法の技術と言えるでしょう。

様々な応用

L1正則化は、様々な分野で活用されている汎用性の高い技術です。具体的には、画像に写っているものを判別する画像認識や、人間が日常的に使っている言葉をコンピュータに理解させる自然言語処理、病気の有無や種類を判断する医療診断など、多岐にわたる分野で応用されています。
特に、L1正則化は、データの次元数が多い場合に役立ちます。次元数が多いとは、例えば、ある人の健康状態を診断するために、身長、体重、血圧、心拍数など、たくさんの種類のデータが必要となる場合です。このようなたくさんの種類のデータのことを特徴量と呼びます。特徴量の数が多すぎると、コンピュータが学習する際に、時間や計算資源を多く必要とします。また、過学習と呼ばれる、学習データだけに特化した結果となり、新しいデータに対して精度が悪くなる現象も起こりやすくなります。
L1正則化を用いると、本当に必要な特徴量だけを選び出し、それ以外の重要度の低い特徴量の影響を少なくすることができます。この特徴量の選び出しを特徴量選択と呼びます。不要な特徴量を削ることで、計算の負担を軽くし、過学習を防ぎ、精度の高いモデルを作ることができます。
このように、L1正則化は、高次元データの解析や特徴量選択において威力を発揮します。例えるならば、職人が様々な道具を使いこなすように、L1正則化は、様々な問題を解決するための柔軟性を備えています。今後も、機械学習の発展に大きく貢献していくことが期待されています。
| L1正則化の特徴 | 詳細 |
|---|---|
| 汎用性の高さ | 画像認識、自然言語処理、医療診断など、多岐にわたる分野で応用 |
| 高次元データへの有効性 | 多数の特徴量を持つデータに対し、計算コストや過学習の抑制に効果的 |
| 特徴量選択 | 重要な特徴量のみを選び出し、不要な特徴量の影響を軽減 |
| 効果 | 計算負荷の軽減、過学習の防止、精度の高いモデル構築 |
| 柔軟性 | 様々な問題への適用が可能 |
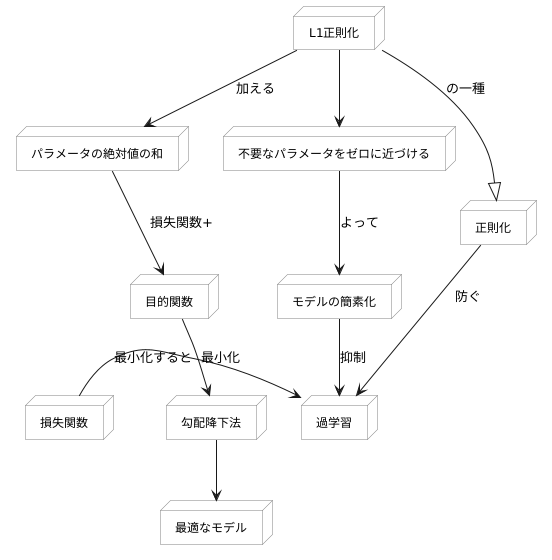
計算方法

計算方法は、まず損失関数を用意することから始まります。損失関数とは、予測と実際の値の差を測る指標のことです。この損失関数を最小にすることで、予測の精度を高めることができます。しかし、ただ損失関数を最小にするだけでは、過学習と呼ばれる問題が起こる可能性があります。過学習とは、学習データに過剰に適合しすぎて、未知のデータに対する予測精度が低下する現象です。
この過学習を防ぐために、正則化という手法を用います。L1正則化は、正則化の方法の一つで、モデルのパラメータの絶対値の和を損失関数に加えることで実現します。パラメータとは、モデルの挙動を調整する値のことです。L1正則化によって、不要なパラメータをゼロに近づける効果があります。これは、まるで木の枝を剪定するように、モデルを簡素化し、過学習を抑えることに繋がります。
具体的には、損失関数にL1正則化項を加えたものを新たな目的関数として設定します。そして、この目的関数を最小にするパラメータを求めることで、最適なモデルを得ることができます。この最適なパラメータを求める際には、勾配降下法などの最適化手法を用います。勾配降下法は、山の斜面を下るように、目的関数の値が小さくなる方向にパラメータを少しずつ更新していく手法です。L1正則化項は絶対値を含むため、微分不可能な点が存在しますが、様々な工夫によって最適化を行うことが可能です。
このように、L1正則化は一見単純な計算で実現されますが、過学習の抑制という大きな効果をもたらします。これは、少ない労力で大きな成果を生み出す、まさに「シンプルイズベスト」を体現した手法と言えるでしょう。