最適なモデル選び:情報量規準の活用

AIの初心者
先生、「えーあい」のモデルを選ぶときに、「情報量規準」ってのが大事って聞いたんですけど、どういうものなんですか? 精度が高ければいいんじゃないんですか?

AI専門家
良い質問だね。確かに、精度が高いことは重要だけど、それだけを見てモデルを選ぶと、問題が起こることがあるんだ。例えば、練習問題を完璧に暗記した生徒を想像してみて。練習問題は満点だけど、新しい問題が出たら解けないよね? それと同じで、「えーあい」も、学習に使ったデータにだけぴったり合うように作られてしまうことがある。これを過学習と言うんだ。情報量規準は、この過学習を防ぐために使うんだよ。
AIの初心者
なるほど。じゃあ、情報量規準はどうやって過学習を防ぐんですか?
AI専門家
情報量規準は、モデルの複雑さとデータの量を両方見て、バランスの良いモデルを選ぶためのものなんだ。モデルが複雑すぎると、過学習しやすくなる。情報量規準は、複雑すぎるモデルにペナルティを与えることで、過学習を防いでいるんだよ。値が小さいほど良いモデルと考えられるから、AICやBICなどの情報量規準を比較して、一番小さい値のモデルを選ぶと良いんだ。
モデルの選択と情報量とは。
人工知能に関わる言葉で「模型の選び方と情報量」について説明します。より良い模型を選ぶための目安として、AIC(赤池情報量規準)やBIC(ベイズ情報量規準)といった情報量の基準があります。模型の良し悪しを判断する基準として一番よく使われるのは正確さですが、正確さの高い模型でも、もとのデータに過剰に適合してしまっているのではないかという心配が出てきます。これを解決するために、情報量の基準を用いて、模型の複雑さとデータの量のバランスをうまく調整します。基本的に、情報量の基準の値が小さいほど良い模型です。
モデル選択の難しさ

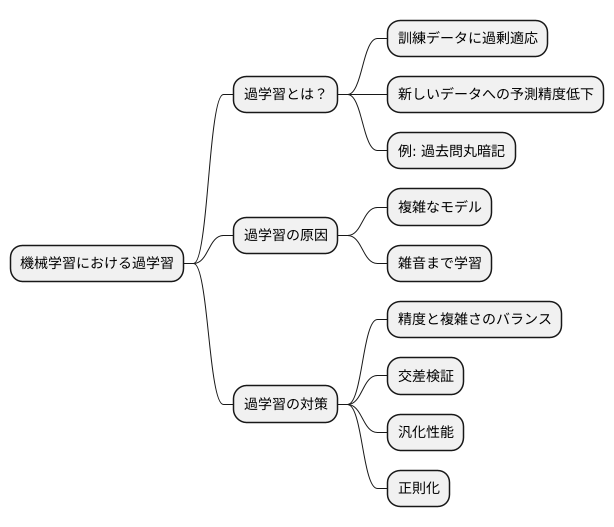
機械学習では、目的に合った適切な予測模型を選ぶことがとても大切です。精度の良い予測模型を作ろうとするあまり、特定の訓練データにだけ過剰に適応した、いわゆる「過学習」の状態に陥ることがあります。過学習とは、訓練データにぴったり合いすぎて、新しいデータに対する予測精度が落ちてしまう現象です。
例えるなら、試験対策で過去問ばかりを解き、解答を丸暗記したとします。過去問と同じ問題が出れば満点を取れるかもしれませんが、少し違う問題や応用問題には対応できません。これと同じように、過学習した予測模型は、訓練データでは高い精度を示しますが、未知のデータでは期待通りの性能を発揮しません。
過学習を避けるには、予測精度だけでなく、模型の複雑さも考える必要があります。複雑な模型は、たくさんの調整可能な要素を持っています。これは、複雑な関数を使ってデータを表現できることを意味しますが、同時に、データの中に含まれる本来意味のない細かな変動(雑音)まで学習してしまう危険性も高まります。雑音まで学習してしまうと、真のデータの規則性を捉えられなくなり、未知のデータへの対応力が低下します。
適切な模型を選ぶには、精度と複雑さのバランスを取ることが重要です。例えば、交差検証という手法を用いて、複数の模型の性能を比較し、最も汎化性能の高い模型を選びます。汎化性能とは、未知のデータに対する予測性能のことです。また、正則化という手法を用いて、模型の複雑さを調整することも有効です。正則化は、模型の複雑さにペナルティを科すことで、過学習を抑える効果があります。
このように、様々な手法を駆使して、過学習を防ぎ、最適な模型を選択することが、機械学習では求められます。
情報量規準とは

情報量規準とは、統計モデルの良し悪しを評価するための指標です。統計モデルは、データの背後にある構造や関係性を表現するために用いられますが、単にデータによく合うモデルが良いモデルとは限りません。複雑すぎるモデルは、現在のデータにはよく合っても、将来のデータに対する予測精度が低い可能性があります。これを「過学習」といいます。情報量規準は、データへの当てはまりの良さだけでなく、モデルの複雑さも考慮することで、過学習を避けて本当に良いモデルを選択することを目指しています。
情報量規準は、大きく分けて二つの要素から成り立っています。一つは、モデルがデータをどれくらいうまく説明できるかを示す「当てはまりの良さ」です。これは、一般的に「対数尤度」という指標で測られます。対数尤度が大きいほど、モデルがデータをうまく説明できていることを意味します。もう一つは、モデルの複雑さを表す「ペナルティ項」です。モデルが複雑になるほど、つまり説明に使う変数が増えるほど、このペナルティ項は大きくなります。
代表的な情報量規準として、AIC(赤池情報量規準)とBIC(ベイズ情報量規準)があります。どちらも、対数尤度からペナルティ項を引いた値で計算されます。値が小さいほど良いモデルとされます。AICとBICの違いは、ペナルティ項の重み付けにあります。BICはAICに比べてペナルティ項の重みが大きいため、より単純なモデルを選びやすい傾向があります。データの性質や解析の目的に合わせて、AICとBICを使い分けることが重要です。
このように、情報量規準は、当てはまりの良さと複雑さのバランスをとりながら、最適なモデルを選択するための強力な道具です。さまざまなモデルを比較検討する際に、情報量規準は客観的な判断基準を提供してくれます。
| 情報量規準 | 統計モデルの良し悪しを評価する指標 |
|---|---|
| 目的 | 過学習を避けて本当に良いモデルを選択する |
| 構成要素 |
|
| 種類 |
|
| AICとBICの違い | BICはAICよりペナルティ項の重みが大きく、単純なモデルを選びやすい |
| 評価方法 | 値が小さいほど良いモデル |
情報量規準の使い方

統計モデルを選ぶとき、色々なモデルの中からどれが一番いいのかを決めるのは難しい問題です。そこで情報量規準という便利な道具を使います。情報量規準を使うと、データに一番合ったモデルを選ぶことができます。
情報量規準には色々な種類がありますが、よく使われるのはAIC(赤池情報量規準)とBIC(ベイズ情報量規準)です。モデルを選ぶ手順は、まず候補となる色々なモデルを用意します。例えば、あるデータに対して直線の式で表されるモデルと、曲線の式で表されるモデルを考えます。次に、それぞれのモデルでAICとBICの値を計算します。そして、AICやBICの値が小さい方のモデルを選びます。値が小さいほど、そのモデルがデータの特徴をよく捉えていると考えられます。
情報量規準を使う際の注意点として、AICやBICは相対的な値であることが挙げられます。つまり、異なるデータで計算したAICやBICの値を比べて、どちらのモデルが良いかを判断することはできません。例えば、Aさんのデータで計算したAICと、Bさんのデータで計算したAICを比較しても意味がありません。同じデータを使って計算したAICやBICの値でなければ、モデルの良し悪しを比較することはできないのです。
同じデータを使って複数のモデルを比べる際には、AICとBICどちらを使っても構いません。ただし、BICはAICよりも単純なモデルを選ぶ傾向があります。単純なモデルは解釈しやすいため、理解しやすいモデルが良い場合はBICを基準に選ぶと良いでしょう。
このように情報量規準は、データに合った統計モデルを選ぶための強力な道具となります。しかし、情報量規準はあくまでもモデル選択の目安となる一つの指標に過ぎません。モデルを選ぶ際には、情報量規準だけでなく、専門的な知識や経験も踏まえて総合的に判断することが大切です。
| 項目 | 内容 |
|---|---|
| 情報量規準 | データに合った統計モデルを選ぶための指標。AICとBICがよく使われる。 |
| モデル選択の手順 | 1. 候補となるモデルを用意する 2. 各モデルでAICとBICを計算する 3. AIC/BICが小さいモデルを選ぶ |
| AIC/BICの値 | 小さいほど、モデルがデータの特徴をよく捉えている。相対的な値なので、異なるデータで得られた値を比較しても意味がない。 |
| AICとBICの違い | BICはAICよりも単純なモデルを選ぶ傾向がある。 |
| 注意点 | 情報量規準はモデル選択の目安となる一つの指標であり、専門知識や経験も踏まえて総合的に判断する必要がある。 |
情報量規準の限界

情報量規準とは、統計モデルの良さを評価するための指標で、AIC(赤池情報量規準)やBIC(ベイズ情報量規準)などが広く知られています。これらの規準は便利な反面、いくつかの重要な限界も持ち合わせています。まず、情報量規準はモデルの真の良さを完璧に測るものではなく、あくまで近似的な評価に過ぎません。現実のデータは複雑で、真のモデルがどのようなものかを知ることは不可能です。情報量規準は、限られた候補の中から、現実に近いと考えられるモデルを選ぶための道具であり、真のモデルそのものを特定することはできません。
次に、情報量規準は大量のデータがあって初めてその効力を発揮します。データが少ない状況では、情報量規準の値が不安定になり、誤ったモデル選択につながる恐れがあります。これは、少ないデータではモデルの複雑さを適切に評価できないからです。小さな標本から得られた情報だけで、複雑なモデルが本当に必要なのか、それとも単純なモデルで十分なのかを判断するのは難しいと言えるでしょう。
さらに、情報量規準はモデルがあらかじめ設定した仮定を満たしていることを前提としています。例えば、AICやBICはデータが正規分布に従うことを暗黙のうちに仮定しています。もしデータが正規分布ではない場合、これらの規準を用いたモデル選択は不適切な結果をもたらす可能性があります。現実のデータは必ずしも正規分布に従うとは限らないため、データの分布をよく観察し、モデルの仮定が妥当かどうかを確認することが重要です。
このように、情報量規準には限界があるため、これらの限界を理解した上で、他の統計的手法と組み合わせて慎重に活用していく必要があります。
| 情報量規準の限界 | 詳細 |
|---|---|
| 近似的な評価 | 真のモデルを知ることは不可能であり、情報量規準はあくまで現実に近いと考えられるモデルを選ぶための近似的な評価ツール。 |
| データ量の必要性 | データが少ないと情報量規準の値が不安定になり、誤ったモデル選択につながる可能性がある。 |
| モデルの仮定 | 情報量規準はモデルがあらかじめ設定した仮定(例:正規分布)を満たしていることを前提としており、仮定が満たされていない場合、不適切な結果になる可能性がある。 |
| 注意点 | 限界を理解した上で、他の統計的手法と組み合わせて慎重に活用する必要がある。 |
まとめ

機械学習では、数多くの種類の学習器から最適なものを選ぶことが、結果の良し悪しを大きく左右します。この学習器の選択を「モデル選択」と言い、精度の高い予測を行うためには欠かせない作業です。モデル選択を適切に行うための有力な道具の一つが、情報量規準です。情報量規準を使うことで、データとの適合度とモデルの複雑さのバランスを見極めながら、最適なモデルを選ぶことができます。
情報量規準には様々な種類がありますが、代表的なものとして赤池情報量規準(AIC)とベイズ情報量規準(BIC)があります。AICは、予測の良さを重視する規準です。一方で、BICはモデルの簡潔さをより重視する規準です。どちらの規準も、モデルがデータにどれだけ良く適合しているかを示す適合度と、モデルの複雑さを表す項から計算されます。適合度は高ければ高いほど良いのですが、複雑すぎるモデルは、学習データに過剰に適合してしまい、未知のデータに対する予測性能が低下する「過学習」と呼ばれる状態に陥りやすくなります。情報量規準は、この適合度と複雑さのバランスをうまくとることで、過学習を起こしにくいモデルを選択するのに役立ちます。
情報量規準は強力な道具ですが、万能ではありません。例えば、データの性質やモデルの種類によっては、情報量規準が最適なモデルを選択できない場合もあります。また、情報量規準は相対的な比較を行うための指標であるため、単独でモデルの絶対的な性能を評価することはできません。そのため、情報量規準だけに頼るのではなく、他の評価指標と組み合わせて使うことが重要です。例えば、交差検証法といった手法と併用することで、より信頼性の高いモデル選択ができます。
未知のデータに対しても高い予測性能を持つモデルを作るためには、情報量規準を正しく理解し、適切に使うことが欠かせません。情報量規準を用いることで、過学習を防ぎ、より良い予測モデルを構築することが可能になります。そして、データからより多くの知見を引き出し、様々な課題の解決に役立てることができます。
| 情報量規準 | 説明 | 特徴 |
|---|---|---|
| AIC (赤池情報量規準) | モデル選択のための指標。予測の良さを重視 | データへの適合度を重視。過学習のリスクあり |
| BIC (ベイズ情報量規準) | モデル選択のための指標。モデルの簡潔さを重視 | モデルの簡潔さを重視。過学習のリスクが低い |
| 情報量規準の構成要素 | 説明 |
|---|---|
| 適合度 | モデルがデータにどれだけ適合しているかを示す指標。高ければ高いほど良い |
| 複雑さ | モデルの複雑さを表す項。複雑すぎると過学習のリスクが高まる |
| 情報量規準を使う上での注意点 |
|---|
| 万能ではない。データの性質やモデルの種類によっては最適なモデルを選択できない場合もある |
| 相対的な比較を行うための指標。単独でモデルの絶対的な性能を評価することはできない |
| 他の評価指標と組み合わせて使うことが重要(例: 交差検証法) |