 アルゴリズム
アルゴリズム 必勝法への道!ミニマックス法とは?意味・仕組み・活用例をわかりやすく解説
勝負の世界では、誰もが勝利を望みます。簡単な遊び事なら、経験と勘で勝てるかもしれません。しかし、囲碁や将棋のように複雑なゲームでは、常に最善の手を打つことは至難の業です。あらゆる可能性を考え、最適な戦略を選ぶには、膨大な思考力が必要です。もし、そんな複雑な思考を機械的に行う方法があるとしたらどうでしょうか。
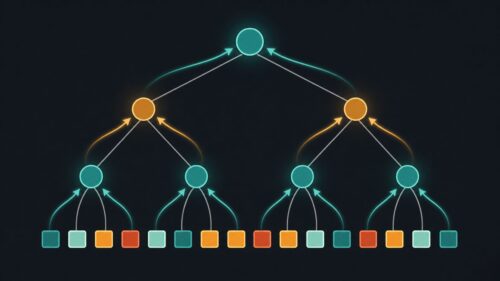
今回ご紹介する「ミニマックス法」は、まさにそのような夢のような思考を実現に近づける手法です。これは、ゲームの展開を木構造のように枝分かれさせて、将来起こりうる様々な局面を先読みするものです。そして、自分が有利になるように、相手が不利になるように、最善の手を探し出します。まるでコンピュータが何十手も先を読んで、勝利への道筋を描いているかのようです。
この手法では、自分の番では最大の利益を得られる手を選び、相手の番では自分に最も不利、つまり相手にとって最も有利な手を想定します。このように、互いに最善を尽くすことを前提に、ゲームの展開を予測していくのです。もちろん、実際のゲームでは全ての可能性を検討することは不可能です。そこで、ある程度の深さまで探索し、それ以降は評価関数を使って局面の良し悪しを判断します。
ミニマックス法は、コンピュータがどのようにゲームを攻略するのか、その秘密の一端を垣間見せてくれます。完璧ではありませんが、複雑なゲームにおいても効果的な戦略を立てるための強力な道具と言えるでしょう。この手法を理解することで、ゲームの奥深さを改めて認識し、より戦略的にゲームを楽しむことができるはずです。