アルゴリズム
アルゴリズム ロジスティック回帰で予測
「ロジスティック回帰」とは、ある出来事が起こる確率を予測するための統計的な手法です。ものごとが起こるかどうかを、二者択一の選択肢で表す場合に用いられます。例えば、お客さんが商品を買うかどうか、生徒が試験に受かるかどうか、といった予測に使えます。
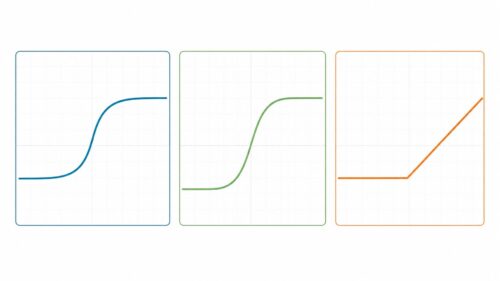
似たような手法に「線形回帰」がありますが、線形回帰は直線を使って予測を行います。一方、ロジスティック回帰は「ロジスティック関数」と呼ばれるS字型の曲線を使って確率を表します。このS字型の曲線のおかげで、確率は必ず0と1の間の値になります。0に近いほど起こる見込みが低く、1に近いほど起こる見込みが高いことを示します。
ロジスティック回帰を使う利点は、複数の要因を考慮に入れて確率を予測できることです。例えば、商品の購入を予測する場合、商品の値段だけでなく、お客さんの年齢や過去の購入履歴なども考慮できます。それぞれの要因がどのくらい影響するかを数値で表すことで、より正確な予測が可能になります。
ロジスティック回帰は様々な分野で活用されています。医療の分野では、病気の診断や治療方針の決定に役立てられています。金融の分野では、融資の審査やリスク管理に利用されています。マーケティングの分野では、顧客の購買行動の分析や広告の効果予測などにも使われています。このように、様々な場面で活用されることで、人々の暮らしをより良くすることに貢献しています。