 アルゴリズム
アルゴリズム 幅優先探索で迷路を解くとは?仕組み・最短経路・注意点をわかりやすく解説
迷路は、昔から多くの人を惹きつけてきた、考えさせる遊びの一つです。入り組んだ道筋から出口を見つけるという行為は、易しいものから非常に難しいものまで、様々な難しさを与えてくれます。遊戯としてだけでなく、計算機の世界でも、迷路は大切な役割を担っています。計算の手順の効率や、問題を解く力を測るための題材として、まさにうってつけなのです。
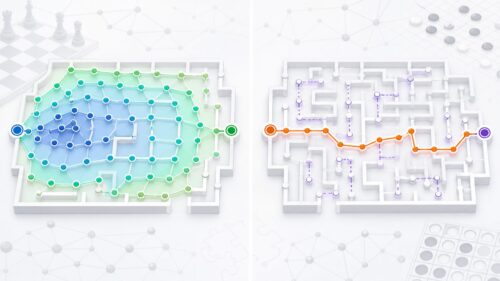
迷路を解く方法はいろいろありますが、中でも基本となるやり方のひとつに「幅優先探索」というものがあります。これは、出発点から近い場所から順番に、行ける範囲をできるだけ広く調べていく方法です。水たまりに水がゆっくり広がっていく様子を思い浮かべてみてください。一歩一歩、確実に調べられる範囲を広げていくことで、最後には出口にたどり着くことができるのです。
具体的には、まず出発点を記憶します。次に、出発点からすぐに行ける場所を全て調べ、まだ訪れたことのない場所を記憶します。そして、記憶した場所から、さらにその隣にある訪れたことのない場所を探し、また記憶します。これを繰り返すことで、出発点から近い順に、迷路全体をくまなく調べていくことができます。あたかも波紋のように、探索の範囲が徐々に広がっていく様子が想像できるでしょう。
この幅優先探索の利点は、必ず出口にたどり着けることです。もし出口が存在するならば、この方法できちんと探索を続ければ、必ず見つけることができます。ただし、迷路が非常に複雑な場合、探索範囲が広くなりすぎて、多くの記憶領域が必要になることがあります。これは、計算機の負担が大きくなることを意味します。しかし、確実に解を見つけられるという点で、幅優先探索は迷路を解くための基本的な、そして強力な方法と言えるでしょう。