 アルゴリズム
アルゴリズム αβ法とは?ミニマックス探索を効率化する枝刈りの仕組み
遊びの中の機械の知恵作りでは、機械に一番良い打ち手を考えさせることが大切です。盤上の様子を見て、打てる手を調べることで、機械は勝ちを目指します。しかし、遊びが複雑になると、調べる手の数はとても多くなり、使える時間内で計算を終えることが難しくなります。そこで、調べ方を工夫して速くするやり方がいろいろ考えられてきました。その中でも、αβ読み方というやり方は、よく使われるやり方の一つです。無駄な調べ物を省くことで計算の量を減らし、すばやく決断できるようにします。
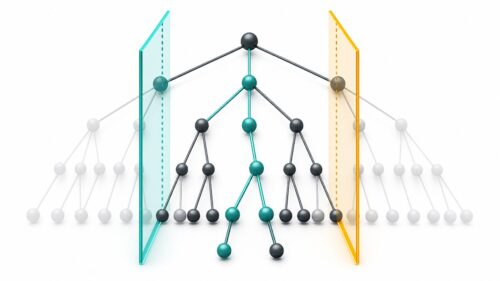
このαβ読み方は、木を育てるように枝分かれした図を使って考えます。木の根の部分は今の盤の状態を表し、枝は次に打てる手を表します。枝の先には、さらに次の手、そのまた次の手…と続いていきます。この木全体を調べるのは大変なので、αβ読み方では、明らかに良くない手は途中で調べずに切り捨てていきます。
αβ読み方の肝は、α値とβ値という二つの値にあります。α値は、これまでに調べた中で、自分にとって一番良い値です。β値は、相手にとって一番良い値です。自分と相手は交互に手を打つので、相手にとって良い手は、自分にとって悪い手になります。
調べを進めていく中で、ある手の評価値がβ値よりも悪くなった場合、その枝はそれ以上調べる必要がありません。なぜなら、相手はβ値以上の良い手を持っているはずなので、その悪い手を選んでくれるからです。同様に、ある手の評価値がα値よりも良くなった場合、その枝はそれ以上調べる必要がありません。なぜなら、自分はα値以上の良い手を見つけたので、それよりも悪い手を選ぶ必要はないからです。
このように、α値とβ値をうまく使うことで、無駄な枝をどんどん切り捨てていくことができます。結果として、全部調べなくても、一番良い手を早く見つけることができます。このαβ読み方は、いろいろな遊びに使われており、機械の知恵を強くするために役立っています。