アルゴリズム
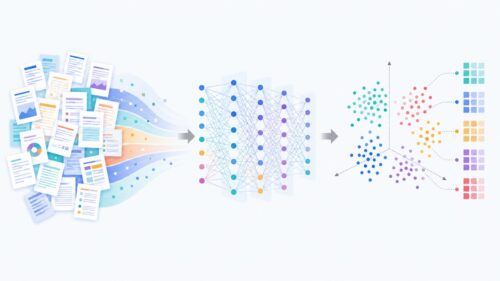
アルゴリズム 人工ニューラルネットワーク:脳の仕組みを模倣
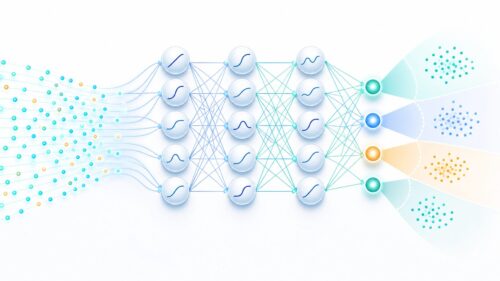
人間の脳の仕組みをまねて作られた計算方法、それが人工神経回路網です。よく人工神経回路網と略されます。私たちの脳は、たくさんの神経細胞が複雑につながり合ってできています。それぞれの神経細胞は、受け取った情報を処理して、次の神経細胞に伝えます。この神経細胞のつながりこそが、私たちが考えたり、感じたり、行動したりするもとになっているのです。人工神経回路網もこれと同じように、小さな計算単位をたくさんつなぎ合わせることで作られています。それぞれの計算単位は、簡単な計算しかできませんが、それらが協力して働くことで、複雑な問題を解くことができるのです。
たとえば、たくさんの写真の中から、猫が写っている写真だけを選び出すという問題を考えてみましょう。人間なら簡単に見分けられますが、コンピュータにとっては難しい問題です。しかし、人工神経回路網を使えば、この問題を解くことができます。まず、たくさんの猫の写真を人工神経回路網に学習させます。すると、人工神経回路網は、猫の特徴を少しずつ覚えていきます。そして、新しい写真を見せると、それが猫かどうかを判断できるようになるのです。これは、まるで人間が猫の見分け方を学ぶのと同じです。最初はよく分からなくても、たくさんの猫を見るうちに、猫の特徴を捉えられるようになるのと同じ仕組みです。
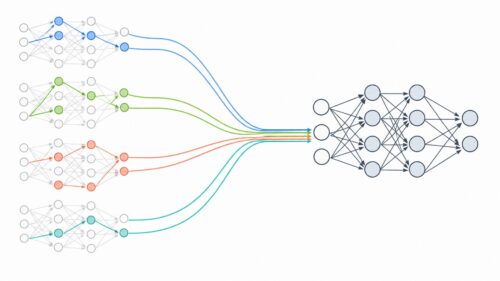
人工神経回路網は、画像認識だけでなく、音声認識や自然言語処理など、様々な分野で応用されています。今後ますます発展していくことが期待される技術の一つです。まるで人間の脳のように、自ら学習し、成長していく人工神経回路網は、未来の社会を大きく変える可能性を秘めていると言えるでしょう。