アルゴリズム
アルゴリズム サポートベクターマシンによる分類
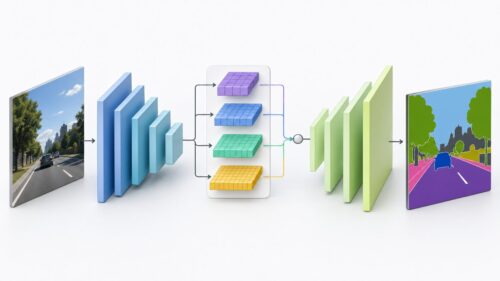
近ごろ、人工知能技術が急速に発展し、身の回りにあふれる膨大な量の情報を整理し、活用する必要性が高まっています。あらゆる分野で集められるデータは、そのままでは宝の持ち腐れで、価値ある情報へと変換しなければなりません。そのために欠かせない技術の一つが、データをある規則に従ってグループ分けする「分類」と呼ばれる手法です。様々な分類手法の中でも、サポートベクターマシンは高い正確さと幅広い応用力を兼ね備え、多くの場面で活用されています。
サポートベクターマシンは、データの集合を最もよく分割する境界線をみつけることを目的としています。想像してみてください、赤い玉と青い玉が沢山混ざって散らばっている様子を。サポートベクターマシンは、これらの玉を赤い玉のグループと青い玉のグループに、最も効率よく分離する線を見つけるのです。この線は、単なる直線ではなく、複雑に曲がりくねった面になることもあります。データが複雑に絡み合っている場合でも、サポートベクターマシンは適切な境界線を描き、正確に分類することができます。
この手法の大きな利点は、未知のデータに対しても高い予測精度を誇ることです。つまり、赤い玉と青い玉を分ける線を一度見つければ、その後、新たに現れた玉がどちらのグループに属するのかを高い確率で予測できます。この精度の高さは、複雑な問題を解く上で非常に重要です。例えば、手書きの文字を認識したり、医療画像から病気を診断したりするなど、様々な分野で応用されています。さらに、サポートベクターマシンは、様々な種類のデータに対応できる柔軟性も持ち合わせています。数値データだけでなく、画像や文章といった様々な形式のデータを扱うことができるため、応用範囲が非常に広い手法と言えるでしょう。