
L1損失とは?平均絶対誤差の意味・計算方法・L2損失との違いを解説

AIの初心者
先生、「L1損失」って何を表す値なんですか?

AI専門家
L1損失は、予測値と実測値のズレを絶対値で測り、その平均を取る指標です。平均絶対誤差、英語ではMAEとも呼ばれます。
AIの初心者
差がプラスでもマイナスでも、ズレの大きさだけを見るということですね。
AI専門家
その通りです。外れ値の影響を受けにくいので、回帰問題やノイズを含むデータでよく使われます。
L1損失とは
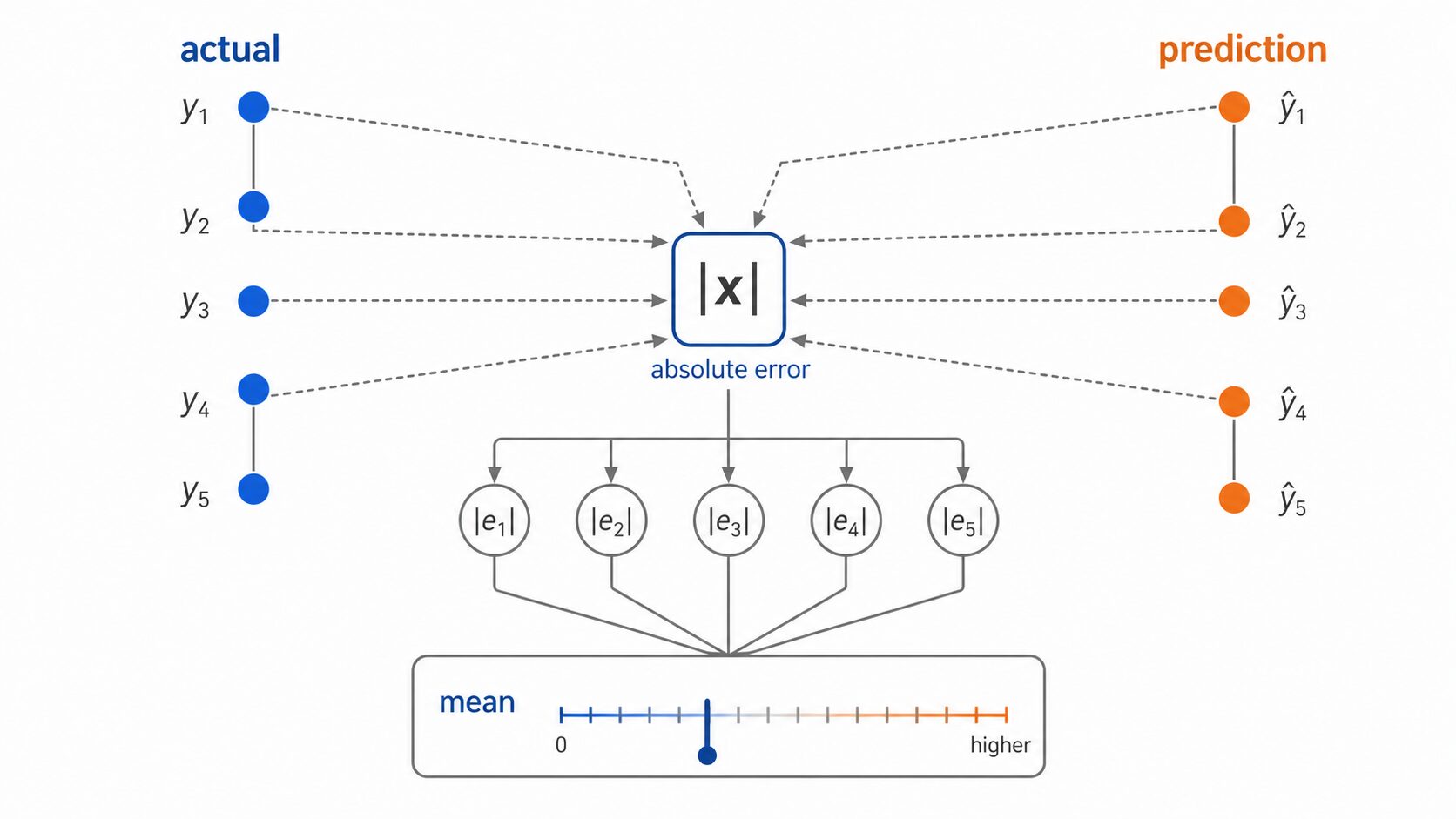
L1損失とは、予測値と実測値の差の絶対値を平均した損失関数です。平均絶対誤差(MAE)とほぼ同じ意味で使われ、モデルの予測が平均してどれくらい外れているかを直感的に表します。
L1損失とは
L1損失は、予測値と実測値のズレを絶対値で測り、その平均を取る指標です。たとえば実測値が100、予測値が110なら誤差は10です。実測値が120、予測値が100なら差は-20ですが、絶対値を取るので誤差は20として扱います。
式で書くと、L1損失は次のように表せます。
L1損失 = |予測値 – 実測値| の平均
ここで大切なのは、差の向きではなく大きさを見ることです。予測が実測より大きくても小さくても、どれくらい外れたかだけを評価します。そのため、売上予測、価格予測、需要予測のような回帰問題で使いやすい指標です。
| 用語 | 意味 |
|---|---|
| L1損失 | 予測値と実測値の差の絶対値を平均した値。 |
| 平均絶対誤差(MAE) | L1損失と同じ考え方で使われる代表的な評価指標。 |
| 絶対値 | 符号を除いた大きさ。-3も3も絶対値は3。 |
| 外れ値 | 他のデータから大きく離れた値。 |
損失関数としての役割
機械学習では、モデルの予測がどれくらい正解から外れているかを数値で測る必要があります。この役割を持つのが損失関数です。損失が小さいほど予測は正解に近く、損失が大きいほど予測は外れています。
学習では、モデル内部のパラメータを少しずつ調整しながら、損失関数の値を小さくしていきます。L1損失を使う場合、モデルは「平均的な絶対誤差」を小さくする方向に学習します。
L1損失の値は、元のデータと同じ単位で解釈しやすい点も特徴です。売上個数を予測しているなら「平均して何個ずれているか」、価格を予測しているなら「平均して何円ずれているか」と読めます。
L1損失の計算方法
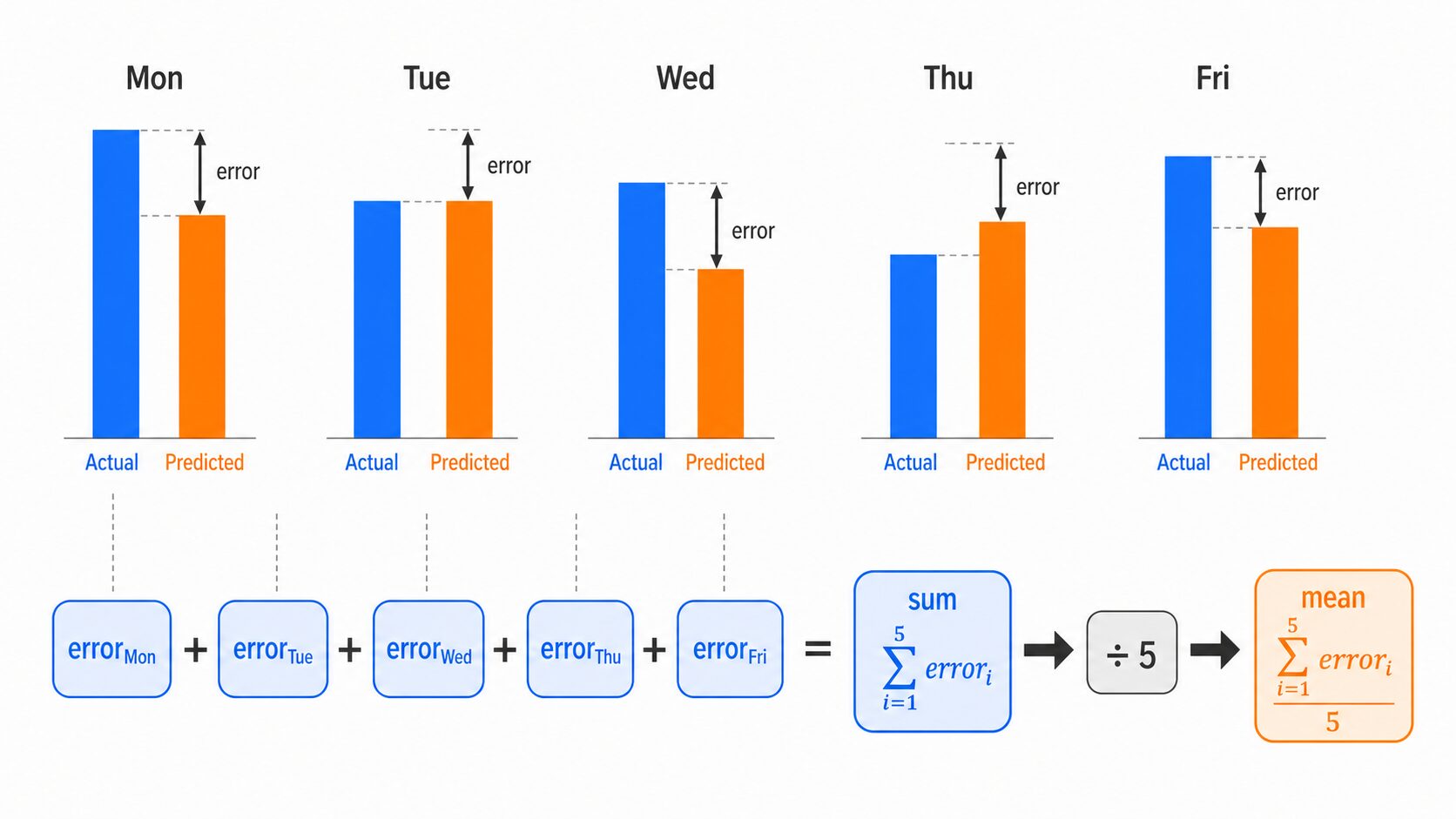
L1損失は、次の3ステップで計算できます。
1. 各データについて、予測値と実測値の差を出す
2. 差の絶対値を取る
3. すべての絶対値誤差を平均する
商品販売数の予測を例にすると、次のようになります。
| 曜日 | 実測値 | 予測値 | 差 | 差の絶対値 |
|---|---|---|---|---|
| 月 | 10 | 12 | -2 | 2 |
| 火 | 15 | 14 | 1 | 1 |
| 水 | 12 | 10 | 2 | 2 |
| 木 | 18 | 16 | 2 | 2 |
| 金 | 14 | 15 | -1 | 1 |
差の絶対値を合計すると、2 + 1 + 2 + 2 + 1 = 8です。データ数は5なので、L1損失は 8 ÷ 5 = 1.6 になります。つまり、このモデルは平均して1.6個ほど予測を外していると解釈できます。
L1損失とL2損失の違い
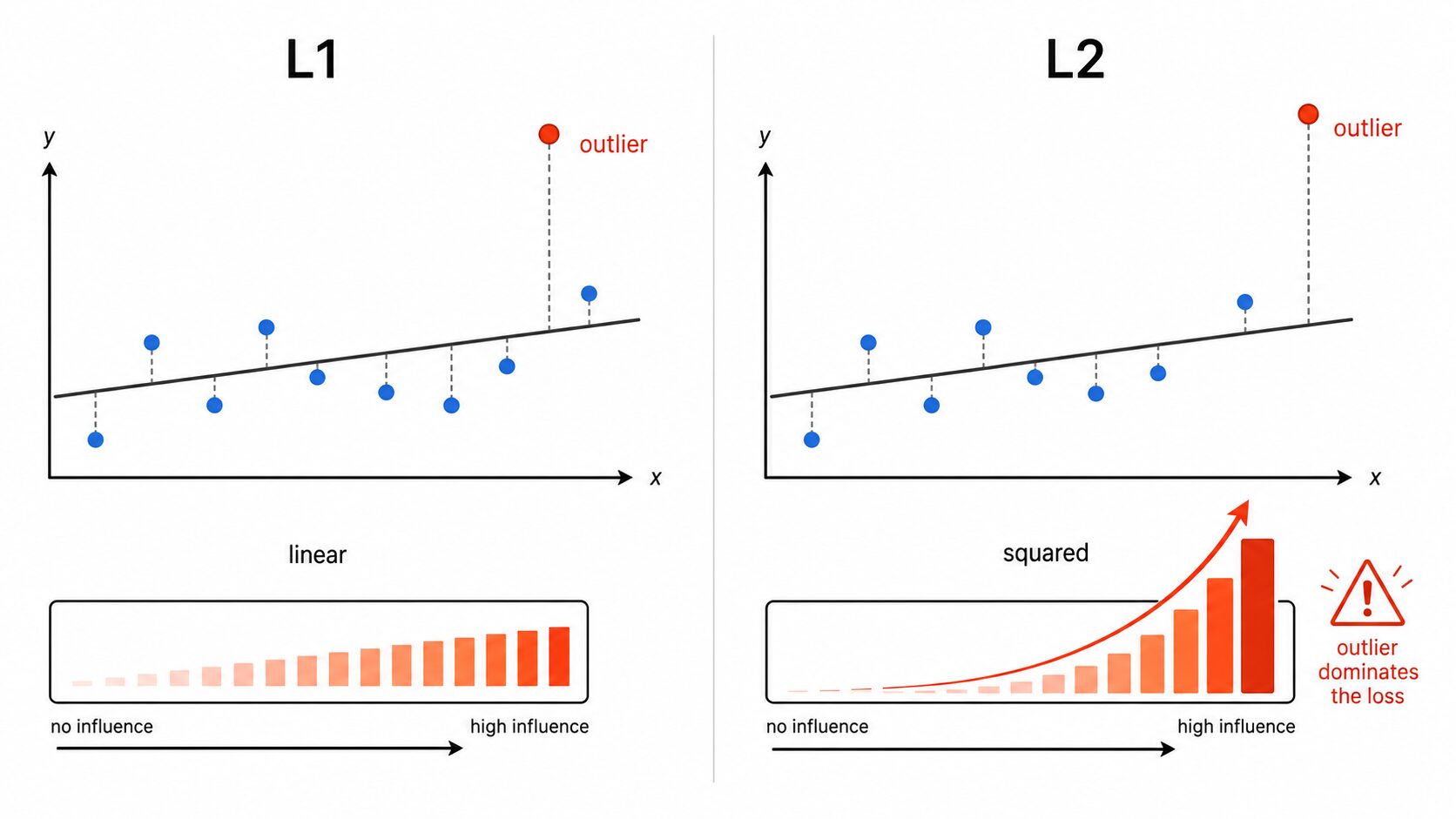
L1損失とよく比較されるのがL2損失です。L2損失は、予測値と実測値の差を二乗してから平均します。差を二乗するため、大きな誤差ほど強く罰する性質があります。
この違いは、外れ値があるときに特に重要です。L1損失では誤差が10なら10、誤差が100なら100として扱います。一方、L2損失では誤差が10なら100、誤差が100なら10000になります。外れ値の影響が一気に大きくなるため、モデルが外れ値に引っ張られやすくなります。
| 項目 | L1損失 | L2損失 |
|---|---|---|
| 計算方法 | 差の絶対値を平均する。 | 差の二乗を平均する。 |
| 外れ値の影響 | 比較的受けにくい。 | 受けやすい。 |
| 誤差への反応 | 誤差の大きさに比例して増える。 | 大きな誤差ほど急激に増える。 |
| 最適化 | ゼロ付近で微分できない点がある。 | 滑らかで扱いやすい。 |
| 向いている場面 | 外れ値やノイズがあるデータ。 | 外れ値が少なく、滑らかな予測を重視するデータ。 |
どちらが常に優れているわけではありません。外れ値に強いモデルを作りたいならL1損失が有力です。一方、外れ値が少なく、滑らかに最適化したい場合はL2損失が扱いやすいことがあります。
L1損失が向いている場面
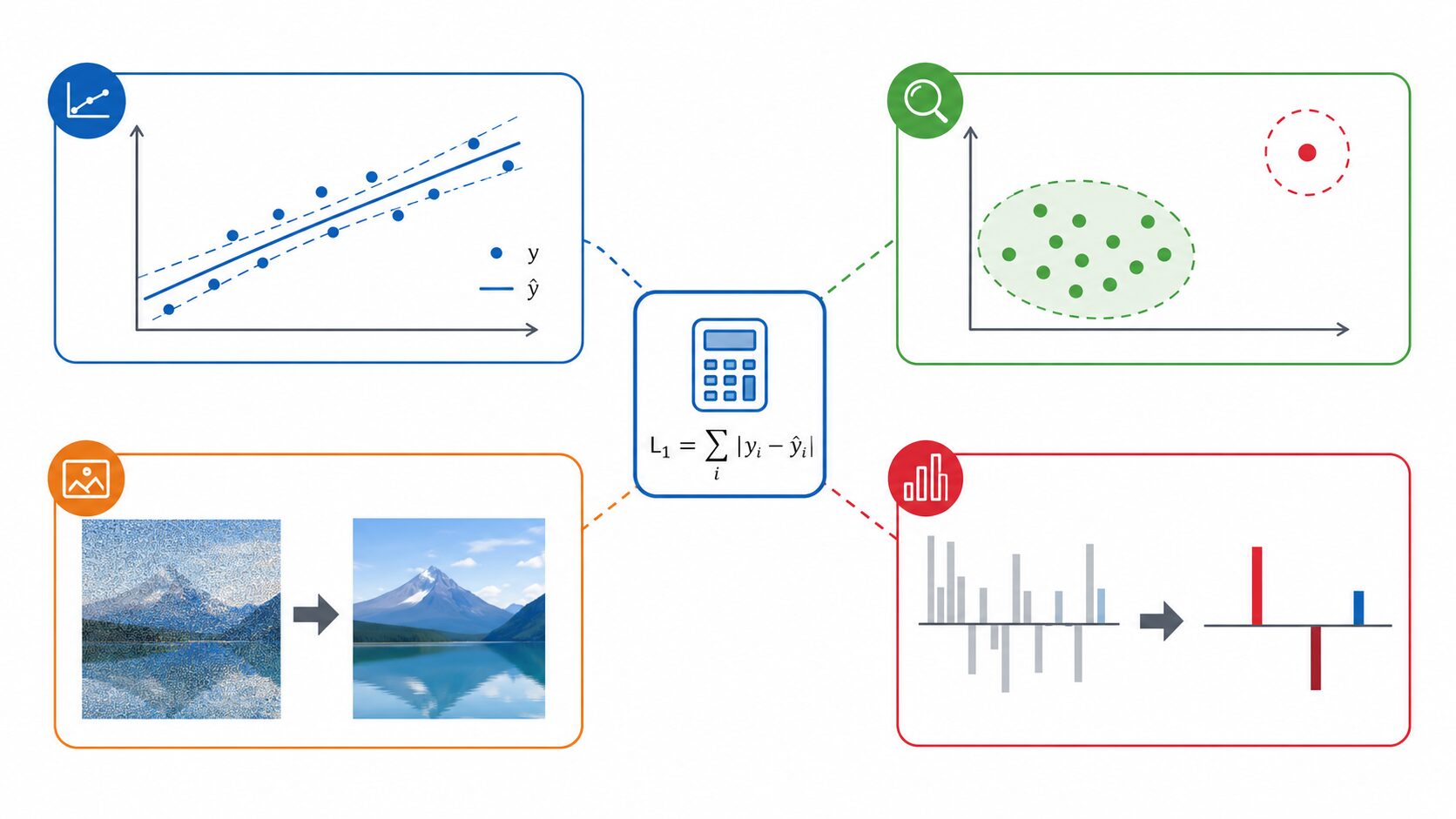
L1損失は、外れ値やノイズの影響を抑えたい場面で役立ちます。代表的な使いどころは次の通りです。
| 用途 | 使われる理由 |
|---|---|
| 回帰問題 | 売上、価格、需要などの予測誤差を直感的な単位で評価できる。 |
| 異常検知 | 通常データからのズレを測りつつ、極端な値への過剰反応を抑えられる。 |
| 画像ノイズ除去 | ノイズのような局所的な外れ値に引っ張られにくい。 |
| スパースモデリング | 一部の係数をゼロに近づけ、重要な特徴だけを残す考え方と相性がよい。 |
特に、データに外れ値が含まれる可能性が高い場合は、L1損失を候補に入れる価値があります。センサー値、売上データ、ユーザー行動データのように、急な変動や記録ミスが混ざるデータでは、L2損失だけでなくL1損失も比較すると判断しやすくなります。
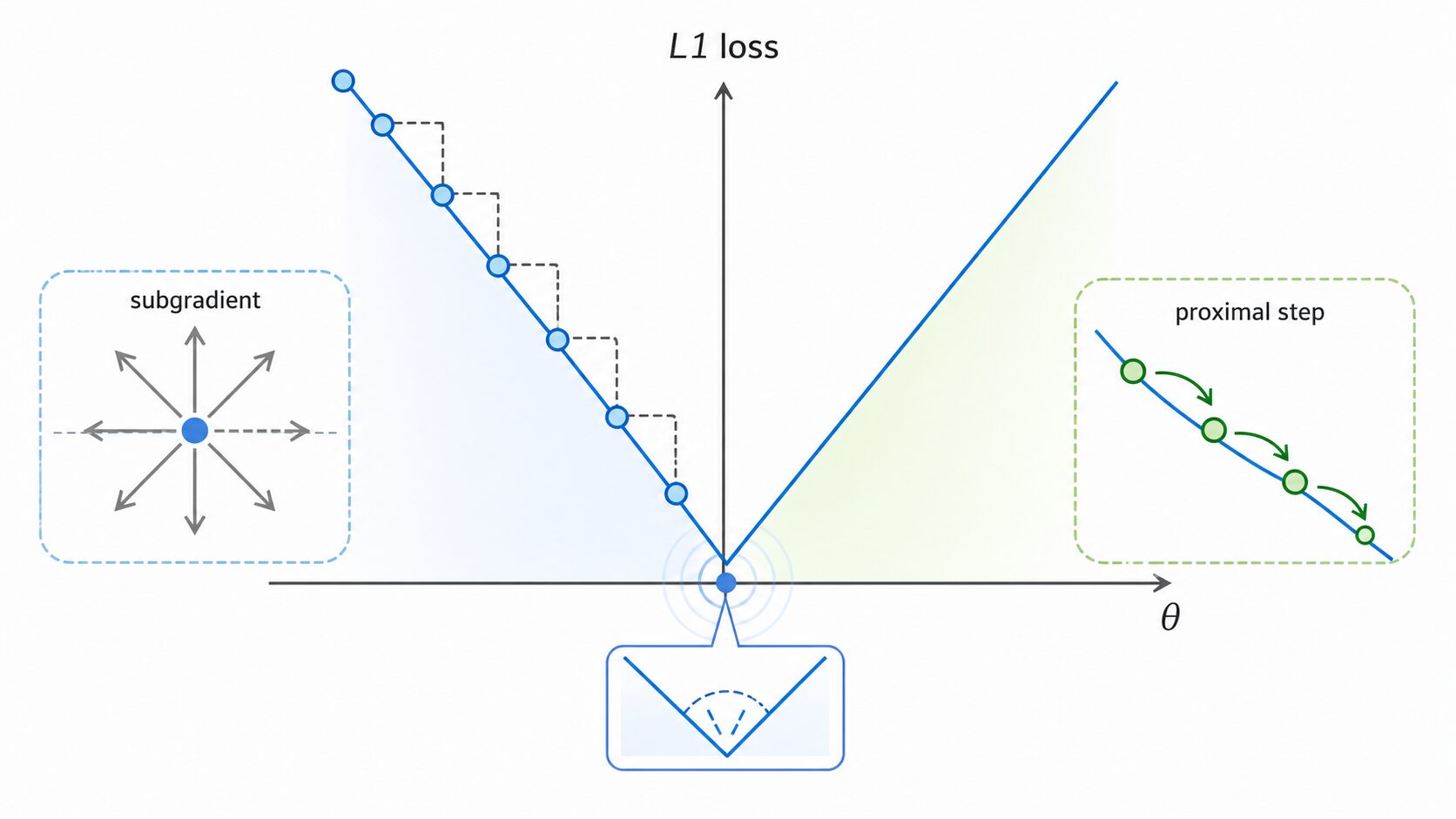
最適化での注意点
L1損失には、ゼロの位置でグラフが折れ曲がるという特徴があります。絶対値の関数は、0を境に傾きが急に切り替わるため、その点では通常の意味で微分できません。
機械学習では勾配降下法のように、損失関数の傾きを使ってパラメータを更新する手法がよく使われます。そのため、L1損失をそのまま扱うと、微分できない点で工夫が必要になります。
実務では、劣勾配法や近接勾配法のような方法が使われます。劣勾配法は、微分できない点でも更新方向を定義して進める考え方です。近接勾配法は、L1正則化のような折れ曲がった項を含む最適化でよく使われる方法です。
ただし、初心者がまず押さえるべきなのは、L1損失には「外れ値に強い」という利点と、「最適化で少し扱いにくい」という注意点があることです。この2つをセットで理解すると、L1損失を選ぶ理由が見えやすくなります。
L1損失を使うときの判断ポイント
L1損失を使うかどうかは、データの性質と目的で決めます。外れ値がある、誤差を元の単位で読みたい、過剰に大きな誤差へ反応したくない、という条件に当てはまるならL1損失は有力です。
一方で、外れ値が少なく、滑らかな損失関数で効率よく最適化したい場合は、L2損失の方が向いていることもあります。実際の開発では、L1損失とL2損失の両方を試し、検証データで性能を比較するのが現実的です。
| 状況 | 候補 |
|---|---|
| 外れ値が多い | L1損失を検討する。 |
| 大きな誤差を特に強く罰したい | L2損失を検討する。 |
| 誤差を元の単位で説明したい | L1損失が分かりやすい。 |
| 滑らかな最適化を重視したい | L2損失が扱いやすい。 |
まとめ
L1損失は、予測値と実測値の差の絶対値を平均した損失関数です。平均絶対誤差(MAE)とも呼ばれ、モデルが平均してどれくらい外れているかを直感的に理解できます。
L1損失の強みは、外れ値の影響を受けにくいことです。差を二乗するL2損失と比べると、大きな誤差に過剰反応しにくいため、ノイズを含むデータやロバストな予測モデルに向いています。
一方で、絶対値を使うためゼロ付近で微分できない点があり、最適化では劣勾配法や近接勾配法などの工夫が必要になる場合があります。L1損失は、外れ値への強さ、解釈しやすさ、最適化の扱いやすさを比較しながら選ぶことが大切です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初版公開。 |
| 2026年4月28日 | L1損失の定義、計算例、L2損失との比較、応用例、最適化の注意点を整理して更新。 |