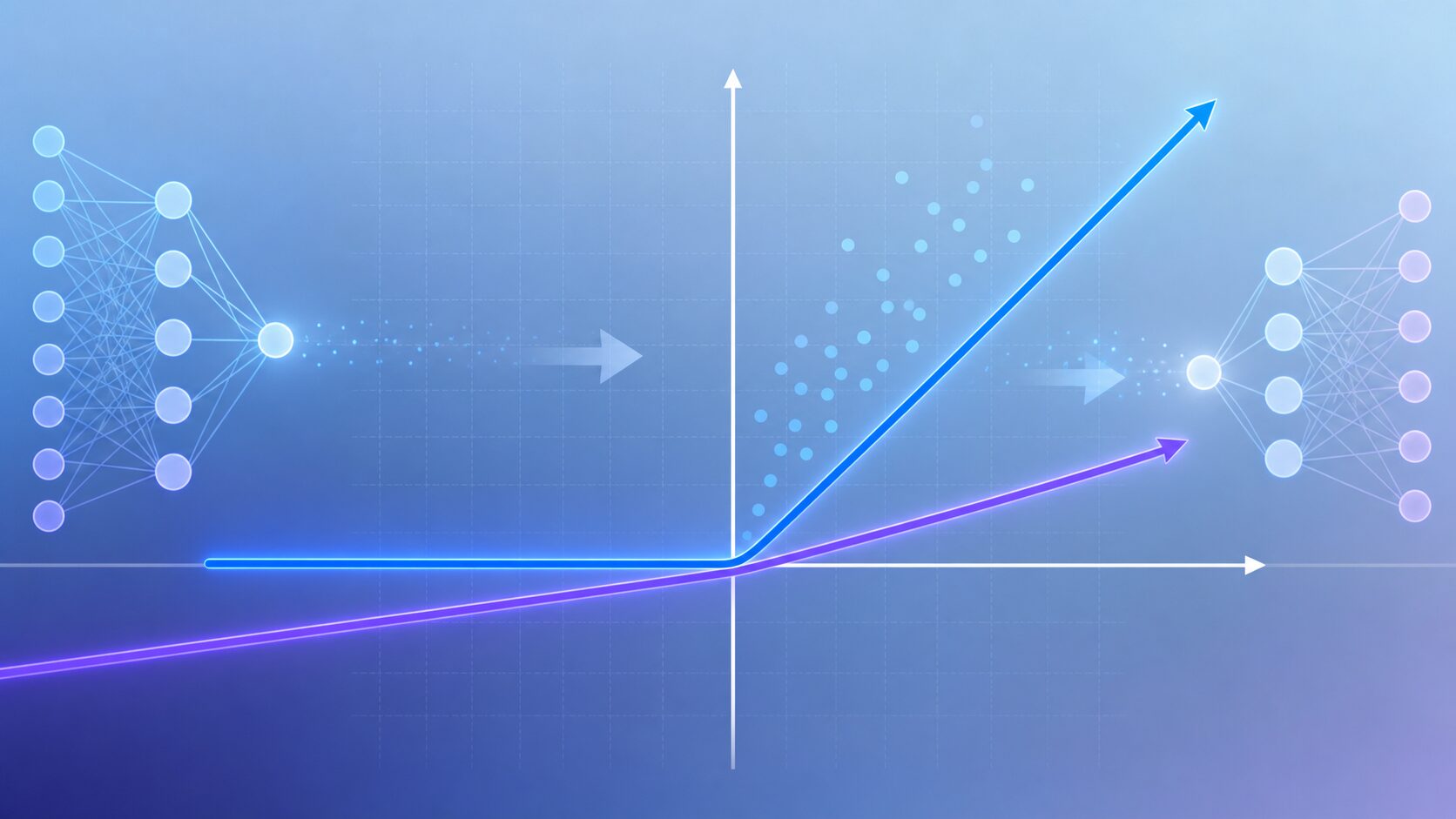
Leaky ReLUとは?ReLUとの違いと利点を初心者向けに解説

AIの初心者
「Leaky ReLU」って、普通のReLUと何が違うんですか?名前は似ていますが、使い分けがよくわかりません。

AI専門家
ReLUは、入力が0より大きいときはそのまま出力し、0以下のときは0を出力する活性化関数だよ。Leaky ReLUは、0未満の入力でも少しだけ値を通す点が違うんだ。
AIの初心者
0未満でも少しだけ通すと、学習にはどんな意味があるんですか?
AI専門家
ReLUでは負の入力側の勾配が0になるため、一部のニューロンが更新されにくくなることがある。Leaky ReLUは負側にも小さな勾配を残し、その問題を軽くするために使われるんだ。
Leaky ReLU関数とは。
Leaky ReLU関数は、深層学習で使われる活性化関数の一種です。ReLUの「計算が軽い」「正の入力をそのまま通せる」という利点を保ちながら、負の入力で学習が止まりやすい弱点を補うために使われます。
Leaky ReLUとは?ReLUの弱点を補う活性化関数
Leaky ReLUは、ニューラルネットワークの各層で信号を変換する活性化関数の一つです。読み方は「リーキー・レル」または「リーキー・レルユー」とされることが多く、日本語では「漏れのあるReLU」と説明されることがあります。
通常のReLUは、入力が0より大きい場合は入力値をそのまま出力し、0以下の場合は0を出力します。仕組みが単純で計算が速いため、深層学習で広く使われてきました。しかし、入力が負の領域では出力も勾配も0になり、学習中に一部のニューロンがほとんど更新されなくなることがあります。
Leaky ReLUはこの弱点を補うため、入力が0未満のときも「完全に0」にはせず、入力値に小さな係数を掛けた値を返します。たとえば係数を0.01にすると、入力が-1のとき出力は-0.01です。これにより、負の入力側にも小さな変化が残り、学習の手がかりを保ちやすくなります。
活性化関数がニューラルネットワークに必要な理由

ニューラルネットワークは、入力データに重みを掛け、足し合わせ、その結果を次の層へ渡しながら学習します。このとき活性化関数は、各層の出力に非線形な変換を加える役割を持ちます。
もし活性化関数がなければ、層を何枚重ねても計算は基本的に線形変換の組み合わせになります。線形変換だけでは、画像の複雑な境界、文章の文脈、音声の細かな特徴のような曲がった関係を表現しにくくなります。
活性化関数を入れることで、モデルは単純な直線だけでなく、より複雑なパターンを表現できるようになります。シグモイド関数、tanh関数、ReLU、Leaky ReLU、ELUなどは、それぞれ出力範囲や勾配の性質が異なるため、モデルの目的や学習の安定性に応じて選ばれます。
ReLUの仕組みと「死んだニューロン問題」
ReLUは「Rectified Linear Unit」の略で、入力が正ならそのまま出力し、0以下なら0を出力します。数式で書くと、ReLUはおおよそ「0と入力値のうち大きいほうを返す関数」と考えられます。
ReLUが広く使われる理由は、計算が非常に軽く、正の入力側では勾配が保たれやすいからです。シグモイド関数やtanh関数では、入力が大きくなると勾配が小さくなり、深いネットワークで学習が進みにくくなることがあります。ReLUはその問題をある程度避けやすく、実装も簡単です。
一方で、ReLUには死んだニューロン問題があります。学習の途中であるニューロンへの入力が負の領域に偏ると、その出力は0になり、勾配も0になります。勾配が0だと重みを更新する手がかりがなくなり、そのニューロンが以後ほとんど働かなくなる可能性があります。
| 活性化関数 | 主な特徴 | 利点 | 注意点 |
|---|---|---|---|
| シグモイド関数 | 出力を0から1の範囲に収める滑らかな関数 | 確率のように解釈しやすい | 入力が大きい領域で勾配が小さくなりやすい |
| tanh関数 | 出力を-1から1の範囲に収める滑らかな関数 | 中心が0に近く、シグモイドより扱いやすい場面がある | 勾配消失が起きることがある |
| ReLU | 正の入力はそのまま、0以下は0にする | 計算が軽く、深層学習で使いやすい | 負の入力側で勾配が0になる |
Leaky ReLUの数式とReLUとの違い
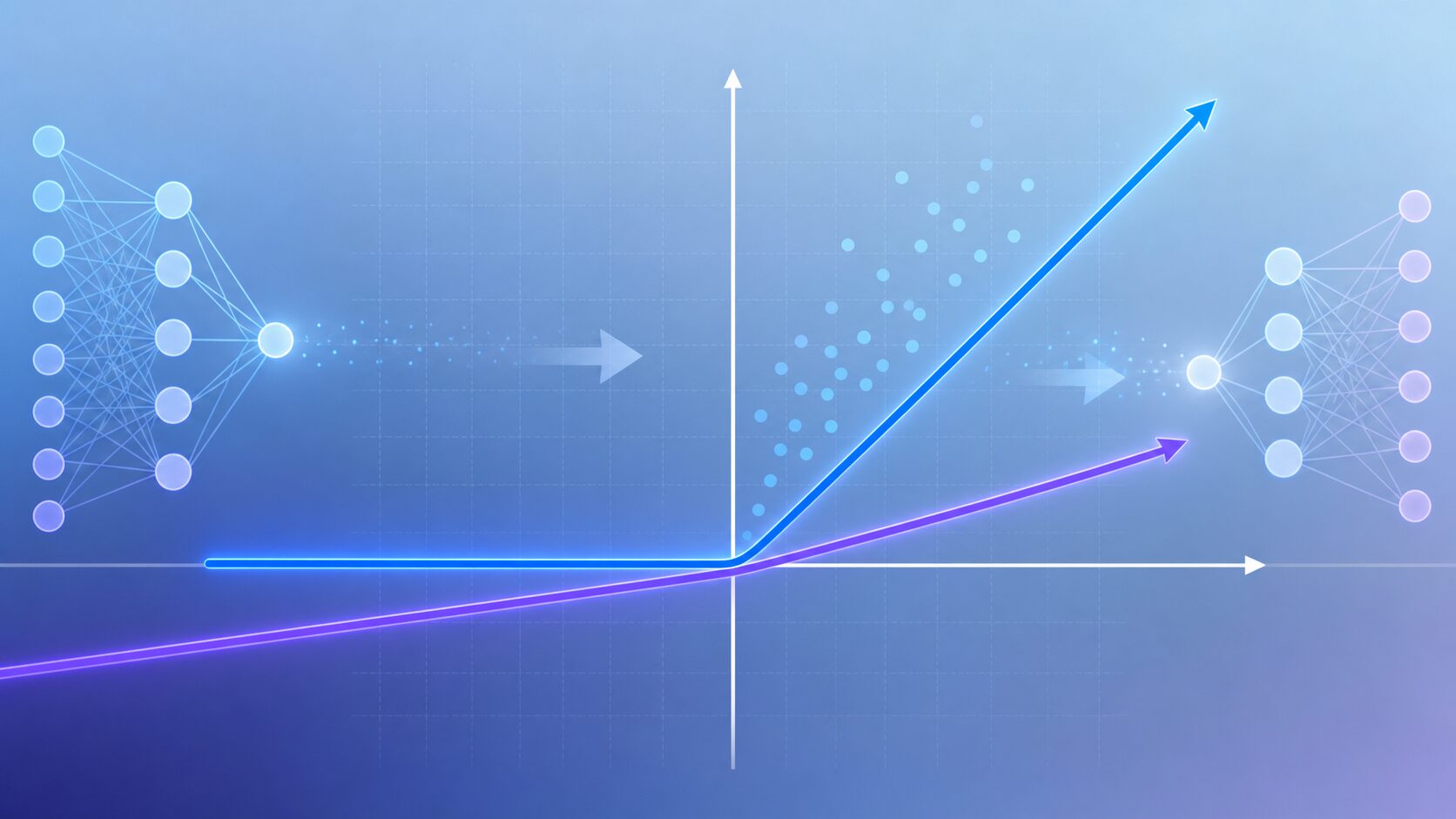
Leaky ReLUは、入力値をx、負の入力に掛ける小さな係数をαとすると、次のように表せます。
\(f(x)=\begin{cases}x & (x \geq 0)\\ \alpha x & (x < 0)\end{cases}\)ここでαは0.01などの小さな正の値に設定されることが多いです。xが5なら出力は5、xが-5でαが0.01なら出力は-0.05になります。ReLUなら-5の出力は0ですが、Leaky ReLUでは少しだけ負の値として残します。
重要なのは、負の入力側でも出力が変化するため、勾配が完全には0にならないことです。勾配とは、学習時に重みをどの方向へどれくらい動かすかを決める手がかりです。Leaky ReLUはこの手がかりを小さく残すことで、ReLUよりもニューロンが止まりにくい状態を作ります。
| 入力x | ReLUの出力 | Leaky ReLUの出力(α=0.01) |
|---|---|---|
| 3 | 3 | 3 |
| 0 | 0 | 0 |
| -1 | 0 | -0.01 |
| -10 | 0 | -0.1 |
パラメータαの意味と決め方
Leaky ReLUのαは、負の入力側でどれくらい値を漏らすかを決めるパラメータです。αが0なら通常のReLUと同じになり、αが大きくなるほど負の入力も強く出力に反映されます。
一般的には0.01、0.1、0.2などの小さな値が候補になります。ただし、常に0.01が最適とは限りません。データの性質、モデルの深さ、初期値、学習率、正則化の有無によって、良い値は変わります。
初心者が試す場合は、まずReLUを基準にし、死んだニューロン問題が疑われる場合や学習が不安定な場合にLeaky ReLUを比較対象として使うと判断しやすくなります。αを変えるときは、訓練データの損失だけでなく、検証データでの性能も見てください。訓練だけ良くなっても、未知のデータで悪化するなら実用上は良い設定とはいえません。
PReLU・ELUなど関連する改良型ReLUとの違い
Leaky ReLUの考え方をさらに広げた活性化関数もあります。代表例がPReLUとELUです。PReLUは「Parametric ReLU」の略で、Leaky ReLUのαを固定値にせず、学習によって調整します。データに合わせて負側の傾きを学べるため、より柔軟ですが、学習するパラメータが増える点には注意が必要です。
ELUは「Exponential Linear Unit」の略で、負の入力側を直線ではなく滑らかな曲線で扱います。出力の平均を0に近づけやすいなどの利点が語られる一方、ReLUやLeaky ReLUより計算は少し複雑になります。
| 関数 | 負の入力での挙動 | 使いどころの考え方 |
|---|---|---|
| ReLU | 0を出力する | まず試しやすい標準的な選択肢 |
| Leaky ReLU | α倍した小さな負の値を出力する | ReLUでニューロンが止まりやすいときの候補 |
| PReLU | 学習されたαで負側の傾きを決める | αを固定したくない場合の候補 |
| ELU | 負側を指数関数的な曲線で出力する | 滑らかな負側の挙動を試したい場合の候補 |
Leaky ReLUが使われる場面と注意点

Leaky ReLUは、画像認識、自然言語処理、音声認識など、深層学習のさまざまなモデルで中間層の活性化関数として使われます。特に、ReLUを使ったときに一部のユニットが活性化しにくい、学習が途中で停滞する、負の入力側の情報を少し残したいといった場合に検討されます。
ただし、Leaky ReLUは万能ではありません。ReLUより常に精度が高いわけではなく、タスクによってはReLUのほうが十分に機能することもあります。モデルの性能は活性化関数だけでなく、データ量、前処理、ネットワーク構造、学習率、バッチ正規化、正則化など多くの要素で決まります。
実務や学習では、ReLUを基準線として置き、Leaky ReLU、PReLU、ELUなどを比較すると理解しやすくなります。比較するときは、同じデータ分割、同じ評価指標、同じ学習条件で確認することが大切です。条件が変わると、活性化関数の差なのか、別の要因による差なのか判断しにくくなります。
まとめ
Leaky ReLUは、ReLUの単純さと計算の軽さを保ちながら、負の入力側にも小さな勾配を残す活性化関数です。ReLUで問題になりやすい死んだニューロン問題を軽減できるため、深層学習モデルの選択肢として知っておく価値があります。
ポイントは、Leaky ReLUが「負の入力を完全には捨てない」ことです。αという小さな係数によって負側の傾きを決め、学習時の更新の手がかりを残します。ただし、最適な活性化関数はタスクやモデルによって変わるため、ReLUやPReLU、ELUと比較しながら検証する姿勢が重要です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月12日 | ReLUとの差分、αの扱い、関連関数との比較を補って更新 |