アルゴリズム
アルゴリズム サンプリング手法とは?AI・統計での意味と生成モデルでの使い方を解説
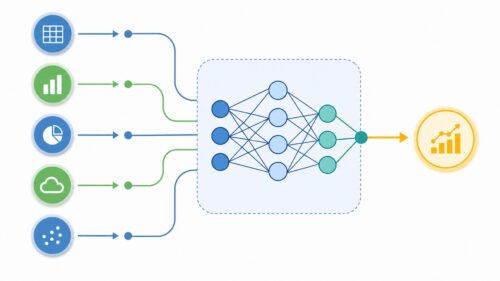
サンプリング手法とは、ある集団全体の特徴を理解するために、その集団から一部を選び出す方法のことです。まるで、大きな鍋で作ったスープの味を確かめるために、一杯だけお椀に注いで味見をするようなものです。全部飲む必要はなく、少しだけ味見すれば全体の味を推測できますよね。統計や機械学習の世界では、このサンプリング手法が欠かせません。
例えば、国勢調査を想像してみてください。全国民一人ひとりに調査するのは、大変な手間と費用がかかります。そこで、サンプリング手法を用いて、全国民の中から代表的な人を選び出し、その人たちに調査を行います。選ばれた人たちの回答から、全国民全体の傾向や特徴を推測するのです。これがサンプリング手法の威力です。全体を調べることなく、一部の情報から全体像を把握できるため、時間と費用を大幅に節約できます。
サンプリング手法には様々な種類があります。例えば、「無作為抽出法」は、集団の誰でも同じ確率で選ばれるように工夫した方法です。くじ引きのようなイメージです。一方、「層化抽出法」は、集団をいくつかのグループに分け、それぞれのグループから代表を選び出す方法です。例えば、年齢層ごとにグループ分けし、各年齢層から代表を選び出すことで、より正確な全体像を捉えることができます。どのサンプリング手法を選ぶかは、調査の目的や対象集団の特性によって異なります。適切なサンプリング手法を選ぶことで、より正確で効率的な調査が可能になります。まるで、料理によって味見の方法を変えるように、状況に合わせて最適な方法を選ぶことが重要です。