
モーメンタムとは?機械学習の最適化を速める仕組みをわかりやすく解説

AIの初心者
「モーメンタム」って、機械学習では何を意味する言葉ですか?

AI専門家
モーメンタムは、AIの学習を進めるときに「過去の進み方」を利用して、更新に勢いをつける方法だよ。坂を転がるボールが少し平らな場所を越えて進むように、学習が止まりやすい場所でも前へ進みやすくするんだ。
AIの初心者
平らに見える場所でも、前の勢いが残っていれば学習を続けられるということですか?
AI専門家
その通り。特に鞍点やプラトーのように勾配が小さくなる場所では、現在の傾きだけを見ると更新が弱くなる。モーメンタムは過去の更新方向を少し残すことで、学習の停滞を減らす働きをするんだ。
モーメンタムとは。
モーメンタムは、機械学習の最適化で使われる手法の一つです。現在の勾配だけでなく、過去の更新方向を「勢い」として利用し、パラメータをより安定して動かします。勾配降下法が苦手とする平坦な領域や鞍点で学習が止まりにくくなるため、深層学習でもよく使われます。
モーメンタムとは
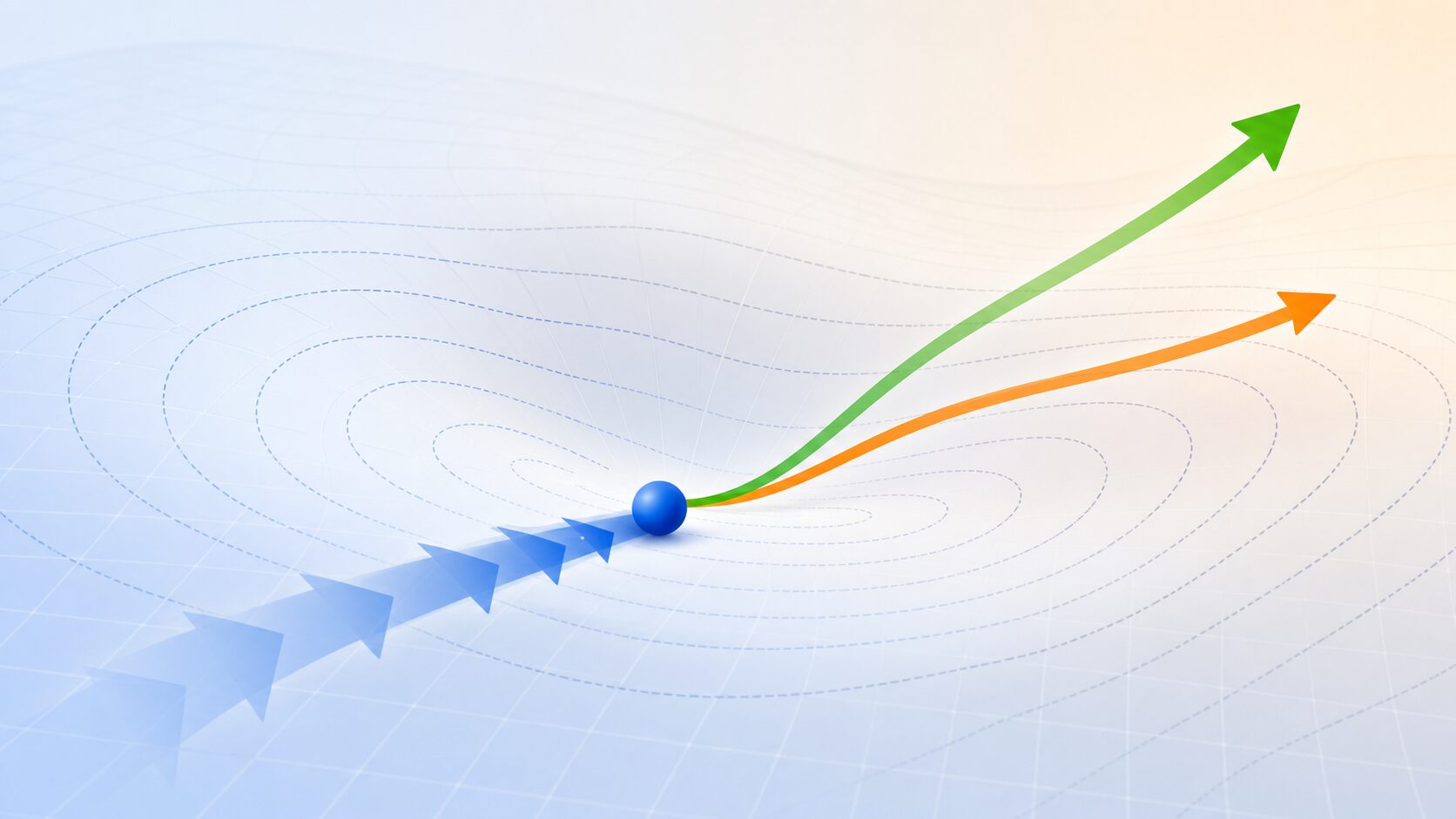
モーメンタムとは、機械学習の学習過程でパラメータを更新するときに、過去の更新方向を利用して動きに慣性を持たせる最適化手法です。英語の momentum は「勢い」や「運動量」を意味します。機械学習では、損失関数の値を小さくするために、重みやバイアスなどのパラメータを少しずつ調整します。この調整を効率よく進めるために使われるのがモーメンタムです。
通常の勾配降下法では、現在地点の勾配、つまり損失が大きく減る方向だけを見て次の更新方向を決めます。しかし、複雑な損失地形では、勾配が小さくなったり、左右に大きく揺れたりして、学習がなかなか前に進まないことがあります。モーメンタムは、過去に進んできた方向を少し残すことで、坂を転がるボールのように進行方向を保ちやすくします。
ここで大切なのは、モーメンタムが「勾配を無視する方法」ではないという点です。現在の勾配を使いながら、過去の更新量も混ぜて次の一歩を決めます。そのため、単純な勾配降下法よりも滑らかに進みやすく、深層学習のような大規模な最適化で役立ちます。
勾配降下法で学習が止まりやすい理由
勾配降下法は、損失関数の傾きを見て、損失が小さくなる方向へパラメータを更新する基本的な最適化手法です。考え方は分かりやすい一方で、損失関数の地形が複雑になると、いくつかの場所で学習が遅くなります。
代表的なのがプラトーです。プラトーは、損失関数の表面が広く平らに近い領域を指します。この領域では勾配が非常に小さくなるため、更新量も小さくなります。すると、まだ良い解に到達していないのに、学習が進んでいないように見える状態になります。
もう一つ重要なのが鞍点です。鞍点は、ある方向から見ると谷の底のように見え、別の方向から見ると山の頂上のように見える点です。多次元の最適化では、鞍点は珍しいものではありません。現在の勾配だけを見る方法では、鞍点付近で進む方向が弱くなり、最小値ではない場所に長くとどまってしまうことがあります。
さらに、谷が細長い形をしている場合、勾配降下法は谷の左右へジグザグに振れながら進むことがあります。この動きは一歩ごとの更新を無駄にしやすく、学習時間を長くします。モーメンタムは、こうした停滞や揺れを抑え、全体として進むべき方向へ更新をそろえやすくします。
モーメンタムの仕組み
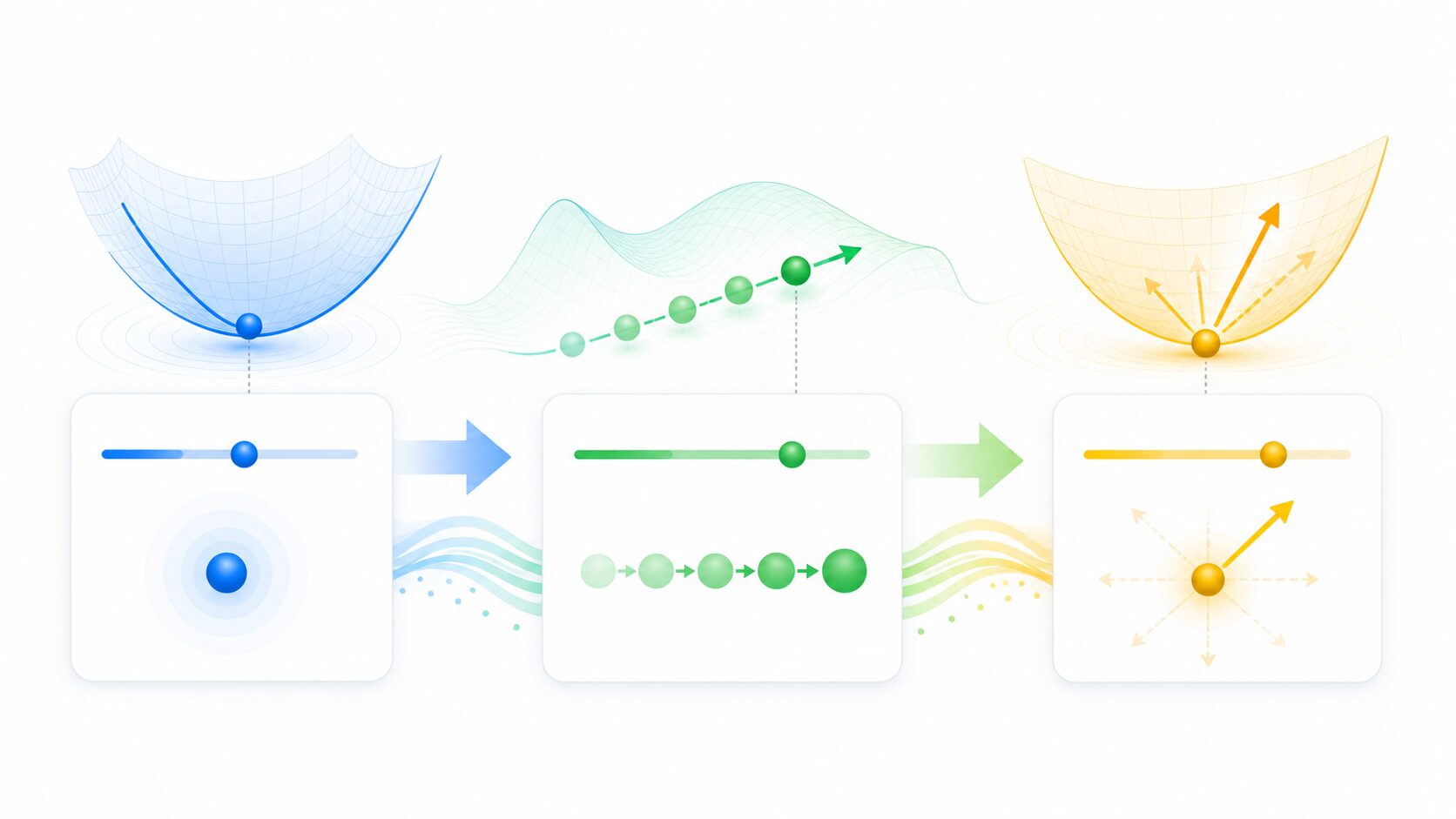
モーメンタムの基本は、過去の更新量を「速度」のような変数にためておき、次の更新に利用することです。現在の勾配だけで方向を決めるのではなく、これまでの移動方向を少しずつ残します。これにより、同じ方向の勾配が続く場合は更新が加速し、反対方向に揺れる成分は打ち消されやすくなります。
坂道のボールで考えると分かりやすくなります。ボールは斜面を下るほど速度を持ち、少し平らな場所に入ってもすぐには止まりません。同じように、モーメンタムを使った最適化では、過去に下ってきた方向の情報が残るため、プラトーや鞍点の近くでも更新が完全には弱まりにくくなります。
ただし、過去の情報をすべて同じ重みで持ち続けるわけではありません。古い情報は徐々に小さくし、新しい勾配を反映させます。この古い情報をどれくらい残すかを決める値が、減衰率やモーメンタム係数と呼ばれるパラメータです。値が大きいほど過去の勢いを強く残し、値が小さいほど現在の勾配を重視します。
更新式とパラメータの読み方

\(
v_t = \mu v_{t-1} – \eta \nabla L(\theta_t)
\)
\(
\theta_{t+1} = \theta_t + v_t
\)
モーメンタムの更新式では、よく v のような速度変数を使います。上の式で、v_t は今回の更新量、v_{t-1} は前回までの更新量、\mu はモーメンタム係数、\eta は学習率、\nabla L(\theta_t) は現在の損失関数の勾配です。
\mu v_{t-1} は、過去の勢いをどれくらい残すかを表します。たとえば \mu = 0.9 なら、前回までの更新量をかなり強く残します。一方、-\eta \nabla L(\theta_t) は、現在の勾配に基づく通常の更新方向です。この二つを足し合わせて、新しい更新量 v_t を作ります。
初心者が混乱しやすいのは、モーメンタム係数と学習率の役割です。学習率は「今回の勾配にどれくらい反応するか」を決めます。モーメンタム係数は「過去の更新方向をどれくらい残すか」を決めます。どちらも更新の大きさに影響するため、片方だけを見て調整すると、更新が大きすぎたり小さすぎたりすることがあります。
モーメンタムを使うメリット
モーメンタムの大きなメリットは、学習の停滞を減らし、最適化を速めやすいことです。プラトーのような勾配が小さい場所でも、過去の更新方向が残っていれば、完全に止まらずに進めます。鞍点付近でも、現在の勾配だけに頼るより抜け出しやすくなります。
また、細長い谷のような地形では、勾配降下法が左右へ揺れながら進むことがあります。モーメンタムは、繰り返し反対方向に出る成分を弱め、同じ方向に続く成分を強めるため、更新経路が滑らかになります。結果として、同じ学習回数でも損失が下がりやすくなることがあります。
深層学習ではパラメータ数が多く、損失地形も高次元で複雑です。そのため、単純な勾配降下法よりも、過去の情報を使う最適化手法が重要になります。モーメンタムは仕組みが比較的単純で理解しやすく、SGDと組み合わせた SGD with momentum として多くの実装で利用できます。
実装で見るポイントと注意点
多くの深層学習フレームワークでは、最適化アルゴリズムの設定として momentum を指定できます。たとえば、SGDに momentum=0.9 のような値を与えると、過去の更新方向を強めに利用する設定になります。実務や学習用のサンプルでもよく見かける値ですが、どの問題でも必ず最適という意味ではありません。
注意点は、勢いが強すぎると最小値の近くを通り過ぎたり、損失が振動したりすることです。特に学習率が大きい場合、モーメンタムによって更新量も大きくなり、安定しないことがあります。損失が発散する、精度が急に悪化する、学習曲線が大きく波打つといった場合は、学習率やモーメンタム係数を見直す必要があります。
もう一つの注意点は、モーメンタムだけですべての最適化問題が解決するわけではないことです。データの前処理、初期値、バッチサイズ、正則化、学習率スケジュールなども学習の安定性に影響します。モーメンタムは強力な道具ですが、ほかの設定と組み合わせて調整するものとして理解すると実装で扱いやすくなります。
代表的な適用例

モーメンタムは、画像認識、自然言語処理、音声認識など、さまざまな機械学習の分野で使われます。特に、ニューラルネットワークの層が深くなり、損失地形が複雑になるほど、最適化を安定させる工夫が重要になります。
画像認識では、畳み込みニューラルネットワーク、いわゆるCNNの学習で使われることがあります。CNNは多数のフィルタや層を持つため、パラメータ空間が大きくなります。モーメンタムを使うと、更新方向が安定しやすくなり、学習が進みにくい場所を抜けやすくなります。
自然言語処理や音声認識でも、系列データを扱うモデルの学習では勾配が不安定になることがあります。RNN、Transformer、そのほかの深層モデルでは、学習率や正則化と合わせて最適化手法を選ぶことが性能に影響します。現在はAdamなどの適応的最適化手法が使われる場面も多いですが、モーメンタムの考え方はそれらを理解する土台にもなります。
関連手法との違い
| 手法 | 主な特徴 | 初心者向けの見方 |
|---|---|---|
| 通常の勾配降下法 | 現在の勾配だけを見て更新する | 考え方は単純だが、停滞やジグザグが起きやすい |
| SGD | データの一部を使って勾配を計算する | 大規模データで使いやすいが、更新にばらつきが出る |
| SGD with momentum | SGDに過去の更新方向を加える | 進む方向に勢いを持たせ、学習を滑らかにする |
| ネステロフ加速勾配法 | 勢いで進んだ先を見越して勾配を評価する | モーメンタムを少し先読みするように改良した方法 |
| Adam | 勾配の平均とばらつきを使って更新量を調整する | 過去の勾配をならす発想を含む、より自動調整寄りの手法 |
ネステロフ加速勾配法は、モーメンタムの代表的な改良版です。通常のモーメンタムが「現在地点で勾配を見て、過去の勢いを足す」のに対し、ネステロフ法は「勢いで少し進んだ先」を想定して勾配を見ます。この違いにより、進みすぎを抑えやすくなる場合があります。
Adamは、モーメンタムと同じように過去の勾配を利用しますが、勾配の大きさのばらつきも考慮して各パラメータの更新量を調整します。そのため、実務ではAdamが手軽に使われることも多いです。ただし、モーメンタムを理解しておくと、Adamなどの最適化手法がなぜ過去の勾配を記録するのかも把握しやすくなります。
まとめ
モーメンタムは、機械学習の最適化で過去の更新方向を利用し、パラメータ更新に勢いを持たせる手法です。現在の勾配だけに頼る勾配降下法では、プラトーや鞍点で学習が遅くなることがあります。モーメンタムは過去の進み方を減衰させながら残すことで、停滞を減らし、更新方向を安定させます。
式で見ると、速度変数に過去の更新量と現在の勾配を組み合わせて、次のパラメータ更新を決めています。モーメンタム係数は過去の勢いの残し方、学習率は現在の勾配への反応の強さを決める値です。どちらも学習の安定性に関わるため、実装では損失の推移を見ながら調整することが大切です。
画像認識や自然言語処理などの深層学習では、モーメンタムの考え方が広く活用されています。SGD with momentum、ネステロフ加速勾配法、Adamなどの関連手法を理解するうえでも、まずは「過去の勾配を利用して学習に勢いを与える」という基本を押さえておくとよいでしょう。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月17日 | 更新式と関連手法を補い、最適化での役割を追いやすく調整 |