RLHF:人間と共に進化するAI

AIの初心者
「RLHF」って難しそうだけど、一体どんなものなんだろう? なんか、人間がAIの学習を助けるって聞いたんだけど…

AI専門家
そうだね。「RLHF」は人間からの助言でAIがより賢くなる学習方法なんだ。AIに「お手本」と「採点係」を与えるようなものだよ。具体的には三つの段階があるんだ。
AIの初心者
お手本と採点係…? 三段階ってどんな段階?
AI専門家
まず、お手本を見せる段階では、AIに模範解答と質問のセットをたくさん学習させる。次に、採点係の段階では、AIにいくつか回答を作らせて、人間がそれぞれの回答を良い順に並べる。そして最後に、その順位に基づいてAIがもっと良い回答をできるように学習するんだ。この三段階でAIは人間が喜ぶような回答を学習していくんだよ。
RLHFとは。
「人工知能」についての言葉である『人間からの反応を基にした強化学習』(英語ではReinforcement Learning with Human Feedbackと書き、RLHFと略します)について説明します。これは、人工知能が人間の意図に沿うように学習(アラインメントともいいます)するための一つの方法です。人工知能が出した結果に対して、人間が意見を伝えることで、さらに学習を進めます。これは、通常の微調整の後に行われることが多く、この二つを合わせて広い意味での微調整と呼ばれることもあります。具体的な方法はおおまかに3つの段階に分かれています。第一段階では、質問とそれに対する模範的な回答の組み合わせを使って、教師あり学習を行います。第二段階では、人工知能に同じ質問に対して複数の回答を作らせ、人間がそれらの回答を良い順に並べます。この順番に基づいて、報酬モデルを学習させます。第三段階では、第一段階と第二段階の結果を用いて、強化学習を行います。
人間による学習

人間による学習、すなわち人間からの教えを受けながら学ぶ方法について説明します。これは専門的には「RLHF」(強化学習と人間の反応、という意味の英語の略語)と呼ばれています。この方法は、人工知能が人間の思い描いた通りに動くようにするための学習方法です。
従来の機械学習では、大量のデータを読み込ませることで人工知能は学習していました。しかし、人間の考えや感じ方は複雑で、データとしてうまく表現できない部分が多くありました。そこで、人間の反応を直接取り入れることで、人工知能が人間の意図をより深く理解できるようにしたものが、この「人間による学習」なのです。
具体的には、人工知能がある行動をしたときに、人間が「良い」「悪い」といった評価をしたり、より良い行動を具体的に教えたりします。人工知能はこの人間の反応をヒントにして、より自然で適切な行動を学習していきます。まるで、子供が親の教えや周りの反応を見ながら成長していくように、人工知能も人間の教えを通して賢くなっていくのです。
この学習方法を使うことで、人工知能は人間の細かいニュアンスや価値観を理解できるようになります。例えば、文章を書くときには、ただ文法的に正しいだけでなく、読みやすく、心に響く文章を書けるようになります。また、絵を描くときには、ただ正確に描くだけでなく、作者の意図や感情を表現した絵を描けるようになるでしょう。
この「人間による学習」は、人工知能がより複雑な仕事をこなせるようになるために欠かせない技術です。人間からの指示をより正確に理解し、人間と協力して様々な課題を解決できるようになることが期待されています。将来的には、様々な分野でこの技術が活用され、私たちの生活をより豊かにしてくれることでしょう。
| 学習方法 | 概要 | 特徴 | 利点 | 将来性 |
|---|---|---|---|---|
| 人間による学習 (RLHF) | 人工知能が人間の思い描いた通りに動くようにするための学習方法。人間からのフィードバックを基に学習を行う。 | 人間の反応(良い/悪い、具体的な指示など)をヒントに学習。従来の機械学習では難しかった、人間の複雑な考えや価値観を理解可能。 | より自然で適切な行動が可能。例えば、文章作成では、読みやすく心に響く文章、絵画では作者の意図や感情を表現した絵を描けるようになる。 | より複雑な仕事、人間との協力による課題解決が可能。様々な分野での活用で生活の向上に貢献。 |
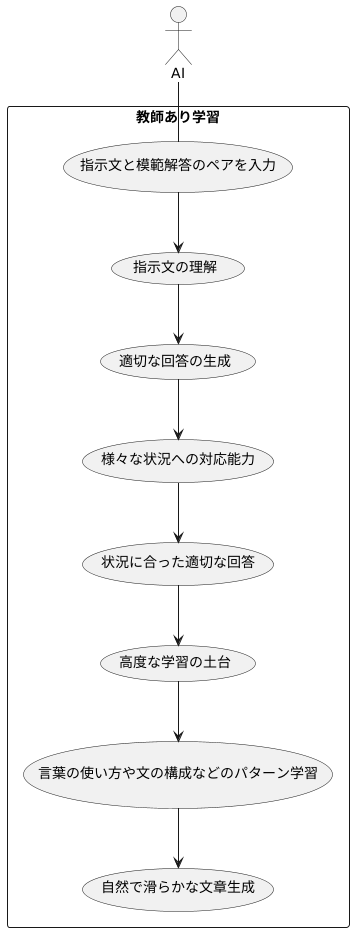
学習の土台

人間が学ぶように、人工知能も段階を踏んで学習していきます。その学習の土台となるのが、「指示された内容に対して模範解答を結びつける」という学習方法です。まるで先生が生徒に例題と解答を示すように、人工知能に対し、様々な質問や指示(これを「指示文」と呼びます)と、それに対する模範的な回答を対にして大量に与えます。
この学習方法を「教師あり学習」と呼びます。人工知能は、膨大な量の指示文と模範解答の組み合わせを学習することで、指示文の内容を理解し、適切な回答を生成するための基本的な能力を身につけます。この段階では、様々な状況に対応できるようになることが重要です。たくさんの例題と解答を学ぶことで、どのような指示文に対しても、状況に合った適切な回答を生成できるようになります。
この教師あり学習は、その後のより高度な学習の土台となります。しっかりと基礎を築くことで、後の学習の効果が大きく変わってきます。膨大なデータから、言葉の使い方や文の構成などのパターンを学ぶことで、まるで人間が書いたかのような自然で滑らかな文章を生成するための基礎能力を身につけるのです。この土台がしっかりしていればいるほど、その上に積み重ねる高度な学習の効果も高まり、より洗練された文章生成が可能になるのです。
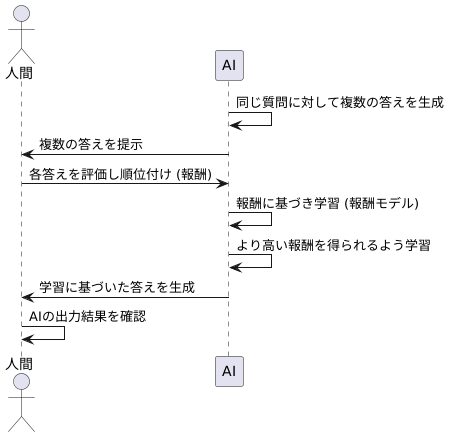
報酬モデルによる学習

人工知能は、まず同じ質問に対して複数の答えを作り出します。まるで複数の生徒が同じ問題にそれぞれ違った解答を出すようなものです。次に、これらの解答を人間が評価し、順位をつけます。良い解答には高い順位、良くない解答には低い順位がつけられます。この順位こそが、人工知能にとっての報酬、つまり学習の指針となるのです。人工知能は、この報酬を通じて人間の好みを学びます。先生に褒められた生徒が、どのようにすればもっと良い答えを書けるかを考えるのと同じように、人工知能もより高い順位、つまりより多くの報酬を得られるような答え方を学習していくのです。
この報酬を基にした学習方法は、報酬モデルと呼ばれます。報酬モデルは、人工知能の学習の方向性を定める羅針盤のような役割を果たします。人間のフィードバックを人工知能に伝えるための橋渡し役と言えるでしょう。もし羅針盤がなければ、船は目的地にたどり着けません。同様に、報酬モデルがなければ、人工知能は人間の望む答えを作り出すことができません。より良い解答、つまり人間がより高く評価する解答を生成するほど、人工知能は高い報酬を得ます。この仕組みにより、人工知能は人間の意図に沿った学習を進めることができるのです。まるで、先生が生徒の良い点を褒めることで、生徒の学習意欲を高め、より良い成果に導くのと同じです。このように、報酬モデルは人工知能が人間の期待に応えるための重要な鍵となります。
強化学習

強化学習とは、人工知能がまるで人間の子どもが遊びを通して学ぶように、試行錯誤を繰り返しながら学習していく方法です。子どもが新しいおもちゃで遊ぶ場面を想像してみてください。最初はどのように遊ぶのか分かりません。ボタンを押してみたり、振ってみたり、色々な行動を試します。そして、おもちゃが光ったり、音が鳴ったりすると、子どもは喜びを感じます。この喜びが「報酬」となり、子どもはどのような行動をすると報酬が得られるのかを徐々に理解していきます。
強化学習もこれと同じ仕組みです。人工知能はまず、与えられた環境の中で様々な行動を試します。そして、それぞれの行動に対して「報酬」が与えられます。この報酬は、目的とする行動に近づいたときに大きく、遠ざかったときに小さくなります。人工知能は、試行錯誤を通して、報酬を最大化する行動を学習していくのです。
例えば、囲碁のプログラムを強化学習で訓練する場合を考えてみましょう。プログラムは最初はランダムに石を置きます。そして、対戦結果に応じて報酬が与えられます。勝てば大きな報酬、負ければ小さな報酬です。プログラムはこの報酬を手がかりに、どの場所に石を置けば勝ちやすくなるのかを学習していきます。
強化学習は、教師あり学習と報酬モデルを組み合わせた学習方法です。教師あり学習では、正解が与えられたデータから学習しますが、強化学習では、正解は明示的に与えられません。代わりに、報酬という形で間接的にフィードバックが与えられます。この報酬を最大化することで、人工知能は最適な行動を学習していきます。
強化学習の利点は、複雑な状況においても、最適な行動を学習できることです。また、人間のフィードバックを取り入れることで、より人間の意図に沿った行動を学習することも可能です。そのため、自動運転やロボット制御など、様々な分野への応用が期待されています。
広義の調整

人工知能の学習において、広義の調整は性能を引き上げるための重要な工程です。この広義の調整の中には、二つの段階が含まれています。まず第一段階は、通常の調整と呼ばれる工程です。これは、特定の作業に特化した練習問題集を使って、人工知能の知識をその作業向けに磨き上げる作業と言えます。例えば、画像認識の人工知能を猫の品種を見分ける作業に特化させたい場合、猫の品種に関する大量の画像データを使って調整を行います。
第二段階は、人間からの反応を取り入れた学習、いわゆる人間からの反応に基づく強化学習です。この段階では、人工知能が出した答えに対して、人間が「良い答え」か「悪い答え」かを評価します。この人間の評価を基に、人工知能は自分の答え方を修正し、より人間が望むような答えを出せるように学習していきます。例えば、文章を要約する人工知能の場合、人間が「この要約は分かりやすい」「この要約は要点が抜けている」といった評価を下すことで、人工知能はより良い要約を生成する方法を学習します。
この二つの段階、つまり通常の調整と人間からの反応に基づく強化学習を組み合わせることで、人工知能は高い正確さと柔軟さを兼ね備えることができます。まず、通常の調整によって特定の作業に対する基本的な能力を高め、次に人間からの反応に基づく強化学習によって、人間の意図や価値観に沿った、より自然で洗練された答えを出せるように学習していくのです。このように、広義の調整は、人工知能を人間の意図に近づけるための重要な技術と言えるでしょう。まるで職人が、まず基本的な技術を学び、その後、師匠の指導を受けながら技を磨いていくように、人工知能も段階的な学習を通して成長していくのです。
未来への展望

人間からの反応を取り込む学習方法である「人間フィードバックによる強化学習」は、人工知能技術の進歩において極めて重要な一歩であり、これからますます関心を集めるものと期待されます。この学習方法を使うことで、人工知能はより人間らしい振る舞いをするようになり、信頼できる存在へと成長していくでしょう。これは人間と人工知能が協力し合う関係をより深め、様々な分野で技術革新を速める可能性を秘めています。
医療の分野では、この技術を使った診断支援システムによって、医師はより正確な診断を迅速に行えるようになるでしょう。患者の症状や検査結果を人工知能が分析し、最適な治療方針を提案することで、医療の質が向上し、人々の健康寿命の延伸に貢献することが期待されます。
教育の分野では、一人ひとりの学習速度や理解度に合わせた個別指導が可能になります。人工知能が生徒の得意・不得意を分析し、最適な学習教材や課題を提供することで、学習効果の最大化を目指します。また、教師の負担軽減にも繋がり、より質の高い教育の実現に貢献するでしょう。
ビジネスの分野では、顧客対応や商品開発など、様々な場面でこの技術が活用されるでしょう。顧客のニーズを的確に捉え、最適な商品やサービスを提供することで、顧客満足度を向上させ、企業の成長に貢献します。また、社内業務の効率化や生産性向上にも繋がり、企業競争力の強化に役立つと考えられます。
このように、医療、教育、ビジネスなど、様々な分野で人間フィードバックによる強化学習の活用が期待されています。人工知能が人間の生活をより豊かにするための重要な役割を果たし、人間の知恵と人工知能の能力を組み合わせることで、未来の社会は大きく変わっていくでしょう。人工知能は単なる道具ではなく、人間と共に未来を創造していくパートナーとなることが期待されます。
| 分野 | 活用例 | 期待される効果 |
|---|---|---|
| 医療 | 診断支援システム |
|
| 教育 | 個別指導 |
|
| ビジネス | 顧客対応、商品開発 |
|