学習済みモデルで賢く自然言語処理

AIの初心者
先生、「学習済みモデル」って、一体どんなものですか?なんだか難しそうでよくわからないです…

AI専門家
そうだね、難しいよね。簡単に言うと、人間でいう「ある程度のことを既に学んでいる人」みたいなものだよ。例えば、言葉を理解する学習済みモデルは、既にたくさんの文章を読んでいて、言葉の意味や繋がりを知っているんだ。
AIの初心者
なるほど!じゃあ、その「既に学んでいる人」に、さらに勉強させるってことですか?
AI専門家
まさにその通り!「既に学んでいること」を土台にして、特定の目的に合わせてさらに詳しく学習させることを「ファインチューニング(微調整)」と言うんだ。例えば、翻訳の学習済みモデルに、さらに医療の専門用語を覚えさせれば、医療の翻訳が得意なモデルになるんだよ。
自然言語処理における Pre-trained Modelsとは。
「人工知能」の用語で「学習済みの言葉の処理の型」というものがあります。これは、言葉の意味や流れを理解できるように既に学習された型に、新しい層を追加して、目的に合わせて細かく調整することで、やりたいことに合った型を簡単に作れる方法です。言葉の処理の目的は、翻訳や人間との会話、文章の種類分けなど様々ですが、どれも言葉の流れを理解することが必要です。そこで、言葉の流れを理解する学習済みの型を再利用することで、最初から学習させるよりも手間を省くことができます。
準備済みモデルとは

言葉に関する処理は、人間のように言葉を理解し、扱う必要があるため、とても複雑です。例えば、文章の意味を理解したり、複数の言葉の関係性を把握したり、文脈に沿った適切な応答を生成したりするなど、高度な処理が求められます。このような複雑な処理を効率的に行うために、近年注目を集めているのが「準備済みモデル」です。
準備済みモデルとは、膨大な量の文章データを使って、既に学習を終えているモデルのことです。例えるなら、言葉を扱うための基礎訓練を終えた状態と言えるでしょう。この基礎訓練によって、モデルは単語の意味や文脈、言葉同士の関係性など、言葉に関する様々な知識を既に習得しています。そのため、特定の作業に利用するためには、その作業に特化した少しの追加学習を行うだけで済みます。
ゼロから学習する場合に比べて、準備済みモデルは学習にかかる時間や労力を大幅に削減できます。さらに、既に多くの知識を持っているため、少ないデータで高い精度を実現できる可能性が高まります。例えば、翻訳作業を行う場合、準備済みモデルに翻訳に特化した追加学習を少しだけ行うことで、精度の高い翻訳システムを比較的簡単に構築できます。同様に、文章を分類する、文章の内容を要約する、質問に答える対話システムを作る、といった様々な作業にも活用できます。
このように、準備済みモデルは開発効率の向上と高精度化を両立できるため、言葉に関する様々なシステム開発において、強力な道具として多くの開発者に利用されています。あらかじめ準備されたモデルを活用することで、言葉の複雑な処理がより簡単になり、様々な応用が可能になります。
| 準備済みモデルとは | 膨大な量の文章データを使って、既に学習を終えているモデル |
|---|---|
| メリット |
|
| 活用例 |
|
言葉の理解を深める仕組み

人間が言葉を理解するように、機械も言葉を理解するための仕組みがあります。その仕組みを支えているのが準備済みモデルと呼ばれるものです。この準備済みモデルは、インターネット上に存在する膨大な量の文章データを読み込むことで学習を行います。そして、文章の中にどのような言葉が、どのくらいの頻度で、どのように組み合わされて使われているのかを分析し、言葉の意味や文脈を理解する能力を身につけます。
例えば、「りんご」という言葉を考えてみましょう。人間は、「りんご」という言葉を聞くと、赤い色の果物で、甘酸っぱい味がするといった情報を思い浮かべます。準備済みモデルも同様に、「りんご」という単語が「果物」「甘い」「赤い」といった言葉と一緒に使われる頻度が高いことを学習することで、「りんご」が果物の一種であることや、その味や色といった特徴を理解します。また、「走る」と「歩く」が一緒に使われることが多いことを学習することで、これらの言葉がどちらも移動に関する動作を表す言葉であることを理解し、その関連性の強さを把握します。
このようにして、準備済みモデルは言葉の意味を数値の列に変換します。これはベクトル表現と呼ばれ、言葉の意味をコンピュータが理解できる形に置き換えたものと言えます。このベクトル表現によって、言葉同士の関連性や類似性を計算することが可能になります。「りんご」と「みかん」はどちらも果物なので、ベクトル表現も似通ったものになります。反対に、「りんご」と「車」は全く異なるものなので、ベクトル表現も大きく異なります。
このベクトル表現こそが、言葉の複雑な意味を捉えるための重要な鍵となります。言葉は、文脈によって意味が変わることもあります。例えば、「走る」という言葉は、人が走ったり、車が走ったり、時間が走ったりと、様々な意味で使われます。準備済みモデルは、周りの言葉との関係性から、どの意味で使われているのかを判断し、人間のように文脈を理解した処理を行います。
この基礎的な言葉の理解を土台として、さらに特定の作業に特化した学習を行うことで、機械はより高度な文章処理をこなせるようになります。例えば、質問応答や文章要約、翻訳など、様々な分野で活用されています。
| 用語 | 説明 | 例 |
|---|---|---|
| 準備済みモデル | インターネット上の膨大な文章データを学習し、言葉の意味や文脈を理解するモデル。 | |
| ベクトル表現 | 言葉の意味を数値の列に変換したもの。コンピュータが言葉の意味を理解できる形。 | 「りんご」と「みかん」は似通ったベクトル表現を持つ。 |
| 基礎的な言葉の理解 | 準備済みモデルがベクトル表現を通じて言葉の意味や文脈を理解すること。 | 「走る」という言葉が、人、車、時間など、文脈に応じて異なる意味を持つことを理解する。 |
様々な応用

あらかじめ学習された言語モデルは、様々な場面で使われています。まるで人間のように言葉を理解し、扱う能力を持つため、幅広い分野で応用が可能です。
まず、言葉の壁を取り払う「翻訳」の分野では、この技術は大きな力を発揮します。異なる国の言葉でも、その文法や単語の違いを理解し、自然で正確な翻訳を作り出します。例えば、日本語から英語、英語からフランス語など、様々な言語の組み合わせに対応できます。これにより、世界中の人々がスムーズに意思疎通できるようになります。
次に、「文章の種類分け」の分野でも活用されています。ニュース記事、小説、詩など、様々な種類の文章の特徴を学習することで、自動的に文章を分類することが可能になります。例えば、ある文章がニュース記事なのか、それとも小説なのかを自動的に判断し、それぞれの種類に応じて適切な処理を行うことができます。これにより、大量の文章を効率的に管理し、必要な情報を素早く見つけることができます。
さらに、「人間とコンピュータが自然な会話をするシステム」を作る上でも、この技術は欠かせません。あらかじめ学習されたモデルは、会話の流れや文脈を理解し、適切な返答を生成することで、より人間らしいコミュニケーションを可能にします。例えば、「今日の天気は?」と聞かれたら、現在の天気情報を提供したり、「お腹が空いた」と言われたら、近くのレストランを提案したりすることができます。
このように、あらかじめ学習された言語モデルは、言葉に関する様々な作業を効率化し、私たちの生活を豊かにする可能性を秘めています。今後も、更なる技術の進歩により、様々な分野での応用が期待されます。
| 分野 | 活用例 | 効果 |
|---|---|---|
| 翻訳 | 日本語から英語、英語からフランス語など、様々な言語の組み合わせに対応した翻訳 | 世界中の人々がスムーズに意思疎通できる |
| 文章の種類分け | ニュース記事、小説、詩など、様々な種類の文章を自動的に分類 | 大量の文章を効率的に管理し、必要な情報を素早く見つける |
| 人間とコンピュータが自然な会話をするシステム | 会話の流れや文脈を理解し、適切な返答を生成。例えば、天気情報の提供やレストランの提案 | より人間らしいコミュニケーションが可能になる |
利点と課題

学習済みの模型を使う一番の利点は、学習にかかる時間とお金を大幅に減らせることです。既に膨大な量の資料で学習済みなので、やりたいことに合わせて少しだけ追加学習すれば、精度の高い模型を作ることができます。これは、例えるなら、既に出来上がった洋服を少しだけ自分の体に合わせて仕立て直すようなものです。ゼロから作るよりもずっと早く、費用も抑えられます。また、学習に使える資料が少ない場合でも、学習済みの模型を使うことで、少ない資料でも効果的に学習させることができます。これは、少ない材料でも、上手な料理人が美味しい料理を作れるのと同じです。
しかし、学習済みの模型を使うにも、いくつか注意すべき点があります。例えば、学習に使われた資料に偏りがある場合、その偏りが模型にも反映されてしまい、ある特定の言い回しに対して、おかしな結果を出してしまうことがあります。これは、偏った情報だけを学んだ人が、偏った意見を言うのと同じです。また、模型のサイズが大きいと、強力な計算機が必要になることもあります。大きな家を建てるには、広い土地が必要なのと同じです。模型を動かすにも、それなりの準備が必要なのです。
とはいえ、これらの課題を解決するための研究開発も進んでおり、今後はさらに便利で使いやすい学習済みの模型が登場することが期待されています。より多くの種類の洋服が用意され、どんな体型の人でも自分に合った洋服を見つけやすくなるでしょう。また、少ない材料でも、もっと簡単に美味しい料理が作れるようになるかもしれません。学習済みの模型は、まるで魔法の箱のようです。これからどんな発展を遂げるのか、本当に楽しみです。
| メリット | デメリット |
|---|---|
| 学習の時間と費用を大幅に削減できる 少ないデータでも効果的に学習できる |
学習データの偏りがモデルに反映される可能性がある モデルのサイズが大きい場合、強力な計算機が必要になる |
これからの展望

近年の技術革新により、様々な分野で目覚ましい成果を上げている準備済みモデルは、言葉に関する処理においても、なくてはならない存在になりつつあります。膨大な量の文章を学習済みのこの技術は、今後ますます発展していくと見込まれています。
まず、学習に用いる文章量の増加が挙げられます。より多くの文章を学習することで、準備済みモデルはさらに賢くなり、より複雑な言葉の処理を可能にするでしょう。例として、今までは難しかった、より自然で人間らしい文章の作成や、高度な翻訳などが実現するでしょう。また、特定の分野に絞って学習した特化型モデルの登場も期待されます。例えば、医療や法律といった専門性の高い分野に特化したモデルは、その分野特有の言葉遣いや表現を理解し、より精度の高い処理を可能にするでしょう。これにより、医療診断の補助や法律文書の自動作成など、様々な場面での活用が期待されます。
さらに、説明可能な人工知能の研究も重要性を増しています。従来のモデルは、どのように答えを導き出したのか分かりにくいという課題がありました。しかし、説明可能な人工知能の研究が進めば、モデルがどのような情報に基づいて判断したのかを理解できるようになります。これは、モデルの信頼性を高めるだけでなく、人間がモデルの判断を理解し、修正していく上でも非常に重要です。例えば、誤った判断をした場合に、その原因を特定し改善することで、より精度の高い、信頼できるモデルの構築に繋がります。
このように、準備済みモデルは人間と機械との言葉による円滑な意思疎通を実現する上で、重要な役割を担っています。今後の更なる発展により、私たちの社会は大きく変わっていく可能性を秘めています。様々な分野で言葉の壁が取り払われ、より豊かなコミュニケーションが実現する未来が期待されます。
| 発展方向 | 内容 | 期待される効果 |
|---|---|---|
| 学習に用いる文章量の増加 | より多くの文章を学習することで、準備済みモデルはさらに賢くなり、より複雑な言葉の処理が可能になる。 | より自然で人間らしい文章の作成や、高度な翻訳などが実現する。 |
| 特化型モデルの登場 | 特定の分野に絞って学習したモデルが登場。 | 医療診断の補助や法律文書の自動作成など、専門性の高い分野での活用が期待される。 |
| 説明可能な人工知能の研究 | モデルがどのように答えを導き出したのかを理解できるようになる。 | モデルの信頼性を高め、人間がモデルの判断を理解し、修正していくことが可能になる。誤った判断の原因を特定し改善することで、より精度の高い、信頼できるモデルの構築につながる。 |
より良い活用に向けて

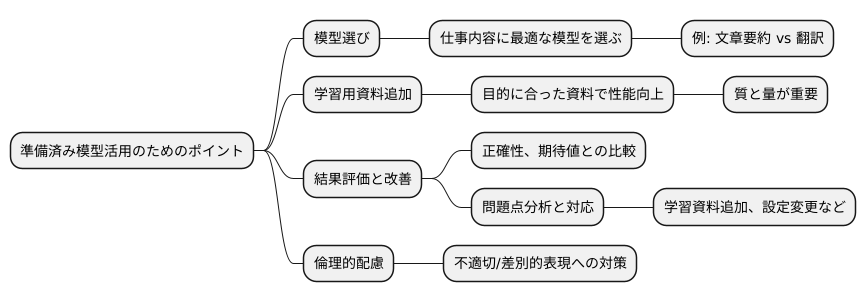
近年、様々な分野で準備済みの学習済み模型が利用されるようになってきました。これらの模型をうまく活用することで、作業の効率化や新たな発見につながる可能性が広がります。しかし、ただ単に模型を使うだけでは、その真価を引き出すことはできません。より良い成果を得るためには、いくつかの重要な点に注意する必要があります。
まず、取り組む仕事内容に最適な模型を選ぶことが大切です。仕事の内容によって、適した模型の種類や特性が異なります。例えば、文章の要約を作る模型と、翻訳をする模型では、得意とする処理内容が違います。それぞれの模型の特徴を理解し、目的に合ったものを選ぶ必要があります。
次に、目的に合った学習用資料を追加することで、模型の性能を向上させることができます。準備済みの模型は、あらかじめ大量の資料で学習されていますが、特定の分野や仕事内容に特化した知識は不足している場合があります。そこで、追加の学習用資料を用いて、模型をより専門的なものへと育てていく必要があります。この学習用資料の質と量は、最終的な模型の性能に大きく影響しますので、慎重に準備する必要があります。
さらに、模型が作った結果をしっかりと評価し、改善点を明らかにすることも重要です。模型は完璧ではなく、誤った結果を出力する場合もあります。出力された結果が正しいか、期待通りかを確認し、問題点があれば、その原因を分析する必要があります。原因に応じて、学習用資料の追加や模型の設定変更などを行い、精度を高めるための工夫を繰り返すことが重要です。
最後に、倫理的な側面にも配慮する必要があります。模型が不適切な表現や差別的な表現を生成する可能性も考慮し、適切な対策を講じる必要があります。
このように、準備済みの模型をうまく活用するためには、継続的な学習と改善が欠かせません。適切な模型選び、学習用資料の準備、結果の評価と改善、そして倫理的な配慮。これらの点を踏まえることで、準備済みの模型は、より強力な道具となり、私たちの生活をより豊かにしてくれるでしょう。