学習
学習 教師あり学習:AIの成長を促す指導法
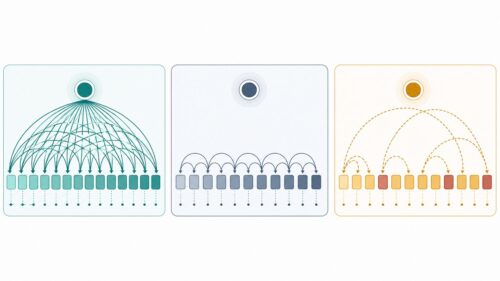
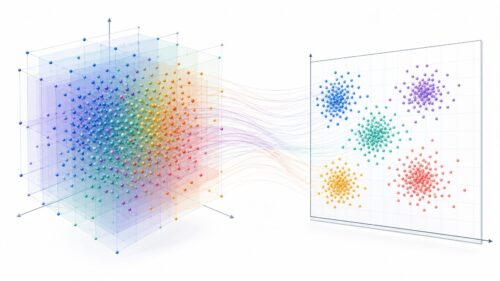
「教師あり学習」とは、人工知能に知識を教え込むための、いわば学校の先生のような学習方法です。 先生が生徒に勉強を教えるように、正解を与えながら学習を進めます。具体的には、たくさんの例題とそれに対する模範解答をセットにして人工知能に与えます。これらの例題と模範解答の組み合わせを「ラベル付きデータセット」と呼びます。ちょうど、算数の問題と解答、国語の文章と要約、といった組み合わせを想像してみてください。
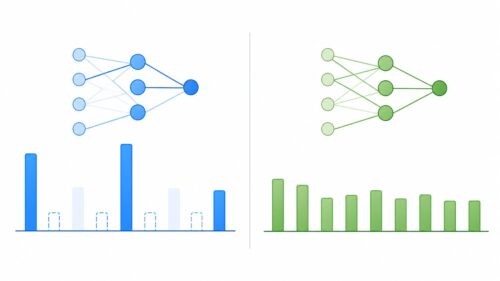
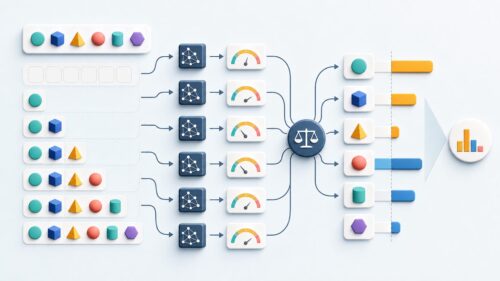
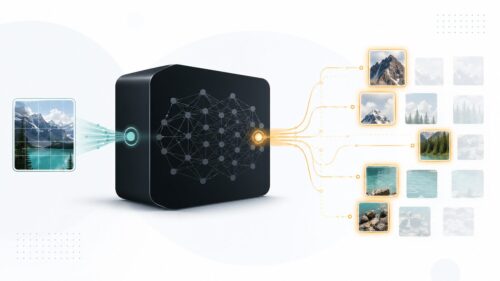
人工知能は、このラベル付きデータセットを使って学習し、新しい例題が与えられた際に、正しい解答を予測できるようになることを目指します。 例えば、大量の猫の画像と「猫」というラベル、犬の画像と「犬」というラベルを学習させれば、新しい画像を見たときに、それが猫か犬かを判断できるようになります。これは、生徒がたくさんの問題を解くことで、問題の解き方やパターンを理解し、新しい問題にも対応できるようになるのと似ています。
この教師あり学習は、様々な人工知能技術の土台となっています。 例えば、写真に写っているものを認識する「画像認識」、人の声を理解する「音声認識」、文章の意味を理解する「自然言語処理」など、幅広い分野で活用されています。身近な例では、迷惑メールの自動振り分け機能も教師あり学習によって実現されています。あらかじめ迷惑メールとそうでないメールを大量に学習させることで、新しいメールが来た時に迷惑メールかどうかを判断できるようになるのです。このように、教師あり学習は、私たちの生活をより便利で豊かにするために、様々な場面で活躍しています。