アルゴリズム
アルゴリズム スキップ結合で画像認識を革新
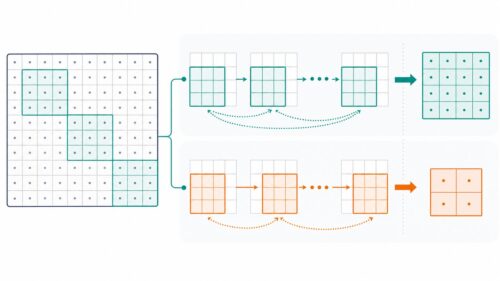
幾重にも層が積み重なった画像認識の仕組みである畳み込みニューラルネットワークにおいて、層と層を飛び越えた結びつきを作る工夫、これがスキップ結合です。通常、このネットワークでは、情報は順番に各層を伝わっていきます。ちょうどバケツリレーのように、前の層から次の層へと情報が受け渡されていくのです。しかし、スキップ結合はこの流れに、近道を作るような働きをします。ある層から得られた情報を、幾つかの層を飛び越えて、先の層に直接届けるのです。
具体的な仕組みとしては、ある層の出力を、数層先の層の入力にそのまま足し合わせることで実現されます。これにより、情報の通り道が複数になり、様々な利点が生じます。まず、勾配消失問題と呼ばれる学習の停滞を和らげることができます。深いネットワークでは、学習の際に誤差を修正していく過程で、層を遡るごとに修正の情報が薄れていく現象がしばしば起こります。スキップ結合によって、修正の情報が直接深い層にも届くため、この問題を軽減できるのです。
また、スキップ結合は、ネットワークの表現力を高める効果も持っています。異なる層は、それぞれ異なる特徴を捉えています。例えば、初期の層は単純な形や模様を、後の層はより複雑な物体の部分を捉えるといった具合です。スキップ結合によって、これらの異なる特徴を組み合わせることが可能になります。様々な種類の情報を統合することで、より深く、より豊かな理解が可能になり、結果として画像認識の精度向上に繋がるのです。まるで、複数の専門家の意見を統合して、より正確な判断を下すようなものです。